开源课程
开源课程
100. 机器学习
学习地址: 南瓜书 PumpkinBook
1.1 绪论
什么是机器学习 What
研究关于【学习算法】的学科,深度学习是机器学习的子集,属于神经网络类的机器学习。
为什么要学习机器学习 Why
- 底层--理论研究
- 底层--系统的开发
- 将机器学习中的算法应用到自己的研究
- 从事AI应用方向的研究:NLP,CV(计算机视觉),推荐系统
怎样学习 How
对于第二和第三种
学习方法:
1.基础数学自己补
- 时间充裕:高等数学,线性代数,概率论基础
- 时间紧张:直接啃 西瓜书,不懂的补
- 推荐课程:张宇考研数学基础班视频
2.高阶数学知识 南瓜书+本视频
学习程度:
1.学的过程中看懂每一步推到过程即可。
2.会调用scikit-learn库即可,不用自行实现。
3.时间紧张的同学,学完前5章即可开始深度学习。
1 假设空间和版本空间
假设空间:一元一次函数,算法:线性回归,模型:y=3x-2
假设空间:一元二次函数,算法:多项式回归,模型:y=x**2
所有能够拟合训练的模型(假设)构成的集合称为“版本空间”。
2 基本术语
算法
算法:从数据中习得的“模型”的具体方法。
算法产出的结果称为“模型”;
样本
关于一个事件或者对象的描述。其实就是向量。
向量中的各个维度称为“特征”或者“属性”
向量中用;分隔为列向量,,分隔为行向量。
把属性值变成数字称其为“特征工程”
标记
机器学习的本质就是在学习样本在某方面的表现是否存在潜在的规律,该方面的信息为“标记”
标记通常也看作样本的一部分,因此一个完整的样本通常表示为(x,y)
y为标记
样本空间
也称为“输入空间”或者“属性空间”,有样本便有样本空间,变量组成的空间。大写x表示
标记空间
也称为“标记空间”或者“输出空间”,大写y表示
标记的取值不同,机器学习任务分为两类
- 标记取值为离散型时,此任务为“分类”
- 当标记取值为连续型时,此任务为“回归”
是否有用到标记信息,机器学习任务分为两类
- 模型训练阶段有用到标记信息时,称此类任务为“监督学习”
- 在模型训练阶段没有用到标记信息时,称此任务为“无监督学习”
数据集
数据集通常用集合来表示。
模型-训练流程
首先收集若干样本。
然后将其分为训练样本和测试样本。训练集和测试集
接着选用某个机器学习算法,让其在训练集上进行学习(训练)。
然后产出模型。
最后用测试集来测试模型的效果。
泛华
机器学习的目标根据已知来对未知做出尽可能的准确判断,因此对未知事物判断的准确与否才是衡量一个模型好坏的关键。我们称其为泛华能力。
分布
指的是概率论中的概率分布。
数据决定模型的上限,算法是让模型无限接近上限
1.2 一元线性回归
正交回归:蓝色的线平行与y轴到拉出来线的距离;
均方误差:全部的y‘相加后2平方;
线性回归:垂直于拉出来的线的距离;
最小二乘估计
基于均方误差最小化来进行模型求解的方法称为“最小二乘法”
极大似然估计
误差:均值为0的正态分布
求解w和b
本质上是一个多元函数求最值的问题,更具体是凸函数求最值问题。
凸集:两个点属于此集合,连接这两个点的任意一点属于此集合。
梯度:多元函数的一阶导数;
机器学习三要素
- 模型:根据具体问题,确定假设空间
- 策略:根据评价标准,确定选取最优模型的策略(损失函数)
- 算法:求解损失函数,确定最优模型
1.3 多元线性回归
推导公式
∂w∂*E***w**=2XT(X****w^−y)=0
2XTXw−2XTy=02**X**T**X****w**−2XTy=0
2XTXw=2XTy2**X**T**X****w**=2XTy
w=(XTX)−1XTy**w**=(XTX)−1XTy
定理3.1:设D⊂RnD⊂Rn是非空开凸集,f(x)f(x)是定义在DD上的实值函数,且f(x)f(x)在DD上二阶连续可微,如果f(x)f(x)的Hessian矩阵∇2f(x)∇2f(x)在DD上是半正定的,则f(x)f(x)是DD上的凸函数;如果∇2f(x)∇2f(x)在DD上是正定的,则f(x)f(x)是DD上的严格凸函数。
定理3.2:若f(x)f(x)是凸函数,且f(x)f(x)一阶连续可微,则x∗x∗是全局解的充分必要条件是其梯度等于零向量,即∇f(x∗)=0∇f(x∗)=0。
1.4 对数几率回归
====文章分界线=*****=*********=============
101 Happy-LLM
从零开始的大语言模型原理与实践教程
Task1
项目介绍
本项目是一个 系统性的 LLM 学习教程 ,将从 NLP 的基本研究方法出发,根据 LLM 的思路及原理逐层深入,依次为读者剖析 LLM 的架构基础和训练过程。同时,我们会结合目前 LLM 领域最主流的代码框架,演练如何亲手搭建、训练一个 LLM,期以实现授之以鱼,更授之以渔。希望大家能从这本书开始走入 LLM 的浩瀚世界,探索 LLM 的无尽可能。
✨ 你将收获什么?
- 📚 Datawhale 开源免费 完全免费的学习本项目所有内容
- 🔍 深入理解 Transformer 架构和注意力机制
- 📚 掌握 预训练语言模型的基本原理
- 🧠 了解 现有大模型的基本结构
- 🏗️ 动手实现 一个完整的 LLaMA2 模型
- ⚙️ 掌握训练 从预训练到微调的全流程
- 🚀 实战应用 RAG、Agent 等前沿技术
第一章 NLP基础概念 - Task2
自然语言处理==Natural Language Processing,NLP
0.0 Task2 的总结
NLP的的组成:
中文处理,文本理解,结构化抽取,内容生成以及智能交互,这几种分类;在NLP的实际操作中可能用到其中多种或者机种。

文本表示发展历程的工作流图谱,有离散表示,连续表示以及动态表示继而文中阐述的细分如下图:
1.1 什么是 NLP
NLP 是 一种让计算机理解、解释和生成人类语言的技术。
1.2 NLP 发展历程
graph LR
F[开始] -->|1940s| A[早期探索]
A -->|1970s| B[符号主义与统计方法]
B -->|2000s| C[机器学习与深度学习]
C -->|2018| D[BERT预训练模型]
D -->|2020+| E[GPT系列与多模态模型]1.3 NLP 任务
从文本的基本处理到复杂的语义理解和生成的各个方面。这些任务包括但不限于中文分词、子词切分、词性标注、文本分类、实体识别、关系抽取、文本摘要、机器翻译以及自动问答系统的开发。每一项任务都有其特定的挑战和应用场景,它们共同推动了语言技术的发展,为处理和分析日益增长的文本数据提供了强大的工具。
1.3.1 中文分词
中文分词(Chinese Word Segmentation, CWS)是 NLP 领域中的一个基础任务。在处理中文文本时,由于中文语言的特点,词与词之间没有像英文那样的明显分隔(如空格),所以无法直接通过空格来确定词的边界。因此,中文分词成为了中文文本处理的首要步骤,其目的是将连续的中文文本切分成有意义的词汇序列。
输入:雍和宫的荷花开的很好。
正确切割:雍和宫 | 的 | 荷花 | 开 | 的 | 很 | 好 | 。
错误切割 1:雍 | 和 | 宫的 | 荷花 | 开的 | 很好 | 。 (地名被拆散)
错误切割 2:雍和 | 宫 | 的荷 | 花开 | 的很 | 好。 (词汇边界混乱)1.3.2 子词切分
一、英文的子词切分
子词切分(Subword Segmentation)是 NLP 领域中的一种常见的文本预处理技术,旨在将词汇进一步分解为更小的单位,即子词。子词切分特别适用于处理词汇稀疏问题,即当遇到罕见词或未见过的新词时,能够通过已知的子词单位来理解或生成这些词汇。子词切分在处理那些拼写复杂、合成词多的语言(如德语)或者在预训练语言模型(如BERT、GPT系列)中尤为重要。
子词切分的方法有很多种,常见的有Byte Pair Encoding (BPE)、WordPiece、Unigram、SentencePiece等。这些方法的基本思想是将单词分解成更小的、频繁出现的片段,这些片段可以是单个字符、字符组合或者词根和词缀。
“Byte Pair Encoding” 即字节对编码,是一种数据压缩算法,也用于自然语言处理中的子词分词。它通过统计字符或符号对出现的频率,将高频的字符对合并为一个新的单元,重复这一过程来构建编码表。在数据压缩中,可减少数据存储空间;在 NLP 里,能处理低频词和未登录词,如将单词 “low”“lower”“newest”“widest”,可能通过字节对编码,把 “est” 作为一个子词单元,这样既有效处理低频词,又能利用子词间的语义关联。
WordPiece 是一种子词切分算法。它将单词拆分成更小的子词单元,旨在解决词汇表外(OOV)单词的问题。通过这种方式,模型可以处理各种复杂词汇,减少词汇表规模同时提升对不同词汇的表征能力。例如单词 “unaffordable”,可能被切分成 “un”“afford”“able” 这些 WordPiece 单元。这种切分方法在自然语言处理如 BERT 等模型中广泛应用,有助于模型更有效地学习语言表示。
“Unigram” 指一元语法,是自然语言处理中的一个基本概念。在文本分析里,它将单个词作为一个分析单元。比如在句子 “She likes apples” 中,“She”“likes”“apples” 就分别是三个 unigram。Unigram 常用于词频统计,像统计一篇文章中每个单词出现的次数,以此来了解文本词汇的分布情况;也用于文本分类,通过分析不同类别文本中一元语法的特征,判断新文本所属类别。
“SentencePiece” 是一种用于自然语言处理的子词分词(sub - word tokenization)工具和技术。它能够将文本分割成合适的子词单元,这些子词在处理不同语言文本时非常有效。在处理一些词汇量巨大或形态丰富的语言时,传统的分词方法可能难以应对。而 SentencePiece 通过统计文本中的字符频率等信息,自适应地构建子词表,能把长单词切分成合理的子词,比如对于一些罕见词,会将其拆分成常见的子词组合,这样既减少了词汇表的规模,又能有效处理未登录词(OOV,out - of - vocabulary words)。例如在处理日语中复杂的汉字和假名组合时,SentencePiece 可以合理地切分,让模型更好地理解和处理文本。它在许多基于 Transformer 架构的预训练模型如 BERT、GPT 等中都有应用,有助于提升模型对文本的理解和处理能力。二、中文的子词切分
在 NLP 领域,汉字语句的子词切分就像把句子拆成 “中间大小” 的碎片,既不像单个字那么碎,也不像完整词语那么大,方便计算机理解。下面用大白话举例说明:
1)、子词切分的核心逻辑:拆高频组合
以句子 “我喜欢吃北京烤鸭” 为例,子词切分的过程类似拼积木:
- 初始状态:先把每个字单独拆开,作为最小单位:
我/喜/欢/吃/北/京/烤/鸭 - 统计相邻字的搭配频率:比如 “北京” 和 “烤鸭” 在语料库中经常一起出现,比 “北” 和 “烤” 更常见。
- 合并高频组合:把 “北京” 合并成一个子词,“烤鸭” 也合并成一个子词,最终切分结果可能是:
我/喜/欢/吃/北京/烤鸭
如果遇到更长的词,比如 “人工智能实验室”,子词切分可能会拆成:人工/智能/实验室(因为这三个部分经常作为独立单元出现),而不是拆成单个字。
2、常见子词切分算法:BPE(字节对编码)的大白话解释
BPE 的核心就是 “找最常见的字对合并”,类似玩 “消消乐”,不过是反向合并:
- 第一步:把句子拆成单个字,比如 “我爱中国”→
我/爱/中/国 - 第二步:统计所有相邻两个字的出现次数,比如 “中国” 出现 100 次,“我爱” 出现 50 次,“爱中” 出现 10 次。
- 第三步:把出现次数最多的 “中国” 合并成一个子词,下次遇到 “中” 和 “国” 就直接当成 “中国” 处理。
- 重复步骤:继续统计新的子词组合,比如 “我爱中国” 可能变成
我/爱/中国,如果 “爱中国” 出现次数多,下次合并成我/爱中国。
2)、子词切分的优势:解决 “生僻词” 问题
比如句子 “他在玩区块链游戏”,其中 “区块链” 是新词:
- 传统分词:如果词典没有 “区块链”,可能拆成 “区 / 块 / 链”,但这样会丢失词义。
- 子词切分:可能拆成 “区块” 和 “链”,因为 “区块” 在比特币等语境中常见,“链” 也有独立意义,计算机更容易理解这是一个和 “区块” 相关的 “链”。
3)、总结:子词切分像 “智能拆词器”
它的目标是让计算机用最少的 “碎片” 理解最多的句子:
- 遇到常见词(如 “北京烤鸭”)就整个拆成子词;
- 遇到生僻词(如 “量子计算”)就拆成 “量子”+“计算”,用已知的子词组合理解新词;
- 避免拆成单个字(丢失词义),也避免依赖固定词典(无法处理新词)。
这种方法让 NLP 模型(如 ChatGPT、BERT)能更灵活地处理各种中文句子,尤其是网络新词、专业术语等。
1.3.3 词性标注
词性标注(Part-of-Speech Tagging,POS Tagging)是 NLP 领域中的一项基础任务,它的目标是为文本中的每个单词分配一个词性标签,如名词、动词、形容词等。这个过程通常基于预先定义的词性标签集,如英语中的常见标签有名词(Noun,N)、动词(Verb,V)、形容词(Adjective,Adj)等。词性标注对于理解句子结构、进行句法分析、语义角色标注等高级NLP任务至关重要。通过词性标注,计算机可以更好地理解文本的含义,进而进行信息提取、情感分析、机器翻译等更复杂的处理。
假设我们有一个英文句子:She is playing the guitar in the park.
词性标注的结果如下:
- She (代词,Pronoun,PRP)
- is (动词,Verb,VBZ)
- playing (动词的现在分词,Verb,VBG)
- the (限定词,Determiner,DT)
- guitar (名词,Noun,NN)
- in (介词,Preposition,IN)
- the (限定词,Determiner,DT)
- park (名词,Noun,NN)
- . (标点,Punctuation,.)
词性标注通常依赖于机器学习模型,如隐马尔可夫模型(Hidden Markov Model,HMM)、条件随机场(Conditional Random Field,CRF)或者基于深度学习的循环神经网络 RNN 和长短时记忆网络 LSTM 等。这些模型通过学习大量的标注数据来预测新句子中每个单词的词性。
1.3.4 文本分类
文本分类(Text Classification)是 NLP 领域的一项核心任务,涉及到将给定的文本自动分配到一个或多个预定义的类别中。这项技术广泛应用于各种场景,包括但不限于情感分析、垃圾邮件检测、新闻分类、主题识别等。文本分类的关键在于理解文本的含义和上下文,并基于此将文本映射到特定的类别。
假设有一个文本分类任务,目的是将新闻文章分类为“体育”、“政治”或“科技”三个类别之一。
文本:“NBA季后赛将于下周开始,湖人和勇士将在首轮对决。”
类别:“体育”
文本:“美国总统宣布将提高关税,引发国际贸易争端。”
类别:“政治”
文本:“苹果公司发布了新款 Macbook,配备了最新的m3芯片。”
类别:“科技” 随着深度学习技术的发展,使用神经网络进行文本分类已经成为一种趋势,它们能够捕捉到文本数据中的复杂模式和语义信息,从而在许多任务中取得了显著的性能提升。
1.3.5 实体识别
实体识别(Named Entity Recognition, NER),也称为命名实体识别,是 NLP 领域的一个关键任务,旨在自动识别文本中具有特定意义的实体,并将它们分类为预定义的类别,如人名、地点、组织、日期、时间等。实体识别任务对于信息提取、知识图谱构建、问答系统、内容推荐等应用很重要,它能够帮助系统理解文本中的关键元素及其属性。
假设有一个实体识别任务,目的是从文本中识别出人名、地名和组织名等实体。
输入:李雷和韩梅梅是北京市海淀区的居民,他们计划在2024年4月7日去上海旅行。
输出:[("李雷", "人名"), ("韩梅梅", "人名"), ("北京市海淀区", "地名"), ("2024年4月7日", "日期"), ("上海", "地名")] 通过实体识别任务,我们不仅能识别出文本中的实体,还能了解它们的类别,为深入理解文本内容和上下文提供了重要信息。随着NLP技术的发展,实体识别的精度和效率不断提高,可以为各种NLP应用提供强大的支持。
1.3.6 关系抽取
关系抽取(Relation Extraction)是 NLP 领域中的一项关键任务,它的目标是从文本中识别实体之间的语义关系。这些关系可以是因果关系、拥有关系、亲属关系、地理位置关系等,关系抽取对于理解文本内容、构建知识图谱、提升机器理解语言的能力等方面具有重要意义。
假设我们有以下句子:
输入:比尔·盖茨是微软公司的创始人。
输出:[("比尔·盖茨", "创始人", "微软公司")] 在这个例子中,关系抽取任务的目标是从文本中识别出“比尔·盖茨”和“微软公司”之间的“创始人”关系。通过关系抽取,我们可以从文本中提取出有用的信息,帮助计算机更好地理解文本内容,为后续的知识图谱构建、问答系统等任务提供支持。
1.3.7 文本摘要
文本摘要(Text Summarization)是 NLP 中的一个重要任务,目的是生成一段简洁准确的摘要,来概括原文的主要内容。根据生成方式的不同,文本摘要可以分为两大类:抽取式摘要(Extractive Summarization)和生成式摘要(Abstractive Summarization)。
- 抽取式摘要:抽取式摘要通过直接从原文中选取关键句子或短语来组成摘要。优点是摘要中的信息完全来自原文,因此准确性较高。然而,由于仅仅是原文中句子的拼接,有时候生成的摘要可能不够流畅。
- 生成式摘要:与抽取式摘要不同,生成式摘要不仅涉及选择文本片段,还需要对这些片段进行重新组织和改写,并生成新的内容。生成式摘要更具挑战性,因为它需要理解文本的深层含义,并能够以新的方式表达相同的信息。生成式摘要通常需要更复杂的模型,如基于注意力机制的序列到序列模型(Seq2Seq)。
假设我们有以下新闻报道:
2021年5月22日,国家航天局宣布,我国自主研发的火星探测器“天问一号”成功在火星表面着陆。此次任务的成功,标志着我国在深空探测领域迈出了重要一步。“天问一号”搭载了多种科学仪器,将在火星表面进行为期90个火星日的科学探测工作,旨在研究火星地质结构、气候条件以及寻找生命存在的可能性。抽取式摘要:
我国自主研发的火星探测器“天问一号”成功在火星表面着陆,标志着我国在深空探测领域迈出了重要一步。生成式摘要:
“天问一号”探测器成功实现火星着陆,代表我国在宇宙探索中取得重大进展。 文本摘要任务在信息检索、新闻推送、报告生成等领域有着广泛的应用。通过自动摘要,用户可以快速获取文本的核心信息,节省阅读时间,提高信息处理效率。
1.3.8 机器翻译
机器翻译(Machine Translation, MT)是 NLP 领域的一项核心任务,指使用计算机程序将一种自然语言(源语言)自动翻译成另一种自然语言(目标语言)的过程。机器翻译不仅涉及到词汇的直接转换,更重要的是要准确传达源语言文本的语义、风格和文化背景等,使得翻译结果在目标语言中自然、准确、流畅,以便跨越语言障碍,促进不同语言使用者之间的交流与理解。
假设我们有一句中文:“今天天气很好。”,我们想要将其翻译成英文。
源语言:今天天气很好。
目标语言:The weather is very nice today. 在这个简单的例子中,机器翻译能够准确地将中文句子转换成英文,保持了原句的意义和结构。然而,在处理更长、更复杂的文本时,机器翻译面临的挑战也会相应增加。为了提高机器翻译的质量,研究者不断探索新的方法和技术,如基于神经网络的Seq2Seq模型、Transformer模型等,这些模型能够学习到源语言和目标语言之间的复杂映射关系,从而实现更加准确和流畅的翻译。
1.3.9 自动问答
自动问答(Automatic Question Answering, QA)是 NLP 领域中的一个高级任务,旨在使计算机能够理解自然语言提出的问题,并根据给定的数据源自动提供准确的答案。自动问答任务模拟了人类理解和回答问题的能力,涵盖了从简单的事实查询到复杂的推理和解释。自动问答系统的构建涉及多个NLP子任务,如信息检索、文本理解、知识表示和推理等。
自动问答大致可分为三类:检索式问答(Retrieval-based QA)、知识库问答(Knowledge-based QA)和社区问答(Community-based QA)。检索式问答通过搜索引擎等方式从大量文本中检索答案;知识库问答通过结构化的知识库来回答问题;社区问答则依赖于用户生成的问答数据,如问答社区、论坛等。
自动问答系统的开发和优化是一个持续的过程,随着技术的进步和算法的改进,这些系统在准确性、理解能力和应用范围上都有显著的提升。通过结合不同类型的数据源和技术方法,自动问答系统正变得越来越智能,越来越能够处理复杂和多样化的问题。
1.3.10 总结
graph TD
A[NLP任务] --> B[中文处理]
A --> C[文本理解]
A --> D[结构化抽取]
A --> E[内容生成]
A --> F[智能交互]
B --> B1[中文分词 CWS]
B --> B2[子词切分 Subword]
C --> C1[词性标注 POS]
C --> C2[文本分类]
C --> C3[实体识别 NER]
D --> D1[关系抽取]
E --> E1[文本摘要]
E --> E2[机器翻译 MT]
F --> F1[自动问答 QA]1.4 文本表示的发展历程
文本表示的目的是将人类语言的自然形式转化为计算机可以处理的形式,也就是将文本数据数字化,使计算机能够对文本进行有效的分析和处理。文本表示是 NLP 领域中的一项基础性和必要性工作,它直接影响甚至决定着 NLP 系统的质量和性能。
在 NLP 中,文本表示涉及到将文本中的语言单位(如字、词、短语、句子等)以及它们之间的关系和结构信息转换为计算机能够理解和操作的形式,例如向量、矩阵或其他数据结构。这样的表示不仅需要保留足够的语义信息,以便于后续的 NLP 任务,如文本分类、情感分析、机器翻译等,还需要考虑计算效率和存储效率。
文本表示的发展历程经历了多个阶段,从早期的基于规则的方法,到统计学习方法,再到当前的深度学习技术,文本表示技术不断演进,为 NLP 的发展提供了强大的支持。
1.4.1 词向量
向量空间模型(Vector Space Model, VSM)是 NLP 领域中一个基础且强大的文本表示方法,最早由哈佛大学Salton提出。向量空间模型通过将文本(包括单词、句子、段落或整个文档)转换为高维空间中的向量来实现文本的数学化表示。在这个模型中,每个维度代表一个特征项(例如,字、词、词组或短语),而向量中的每个元素值代表该特征项在文本中的权重,这种权重通过特定的计算公式(如词频TF、逆文档频率TF-IDF等)来确定,反映了特征项在文本中的重要程度。
向量空间模型的应用极其广泛,包括但不限于文本相似度计算、文本分类、信息检索等自然语言处理任务。它将复杂的文本数据转换为易于计算和分析的数学形式,使得文本的相似度计算和模式识别成为可能。此外,通过矩阵运算如特征值计算、奇异值分解(singular value decomposition, SVD)等方法,可以优化文本向量表示,进一步提升处理效率和效果。
然而,向量空间模型也存在很多问题。其中最主要的是数据稀疏性和维数灾难问题,因为特征项数量庞大导致向量维度极高,同时多数元素值为零。此外,由于模型基于特征项之间的独立性假设,忽略了文本中的结构信息,如词序和上下文信息,限制了模型的表现力。特征项的选择和权重计算方法的不足也是向量空间模型需要解决的问题。
VSM 方法词向量:
# "雍和宫的荷花很美"
# 词汇表大小:16384,句子包含词汇:["雍和宫", "的", "荷花", "很", "美"] = 5个词
vector = [0, 0, ..., 1, 0, ..., 1, 0, ..., 1, 0, ..., 1, 0, ..., 1, 0, ...]
# ↑ ↑ ↑ ↑ ↑
# 16384维中只有5个位置为1,其余16379个位置为0
# 实际有效维度:仅5维(非零维度)
# 稀疏率:(16384-5)/16384 ≈ 99.97% 为了解决这些问题,研究者们对向量空间模型的研究主要集中在两个方面:一是改进特征表示方法,如借助图方法、主题方法等进行关键词抽取;二是改进和优化特征项权重的计算方法,可以在现有方法的基础上进行融合计算或提出新的计算方法.
1.4.2 语言模型
N-gram 模型是 NLP 领域中一种基于统计的语言模型,广泛应用于语音识别、手写识别、拼写纠错、机器翻译和搜索引擎等众多任务。N-gram模型的核心思想是基于马尔可夫假设,即一个词的出现概率仅依赖于它前面的N-1个词。这里的N代表连续出现单词的数量,可以是任意正整数。例如,当N=1时,模型称为unigram,仅考虑单个词的概率;当N=2时,称为bigram,考虑前一个词来估计当前词的概率;当N=3时,称为trigram,考虑前两个词来估计第三个词的概率,以此类推N-gram。
N-gram模型通过条件概率链式规则来估计整个句子的概率。具体而言,对于给定的一个句子,模型会计算每个N-gram出现的条件概率,并将这些概率相乘以得到整个句子的概率。例如,对于句子“The quick brown fox”,作为trigram模型,我们会计算 P("brown"|"The","quick")、$P("fox" | "quick", "brown")$等概率,并将它们相乘。
N-gram的优点是实现简单、容易理解,在许多任务中效果不错。但当N较大时,会出现数据稀疏性问题。模型的参数空间会急剧增大,相同的N-gram序列出现的概率变得非常低,导致模型无法有效学习,模型泛化能力下降。此外,N-gram模型忽略了词之间的范围依赖关系,无法捕捉到句子中的复杂结构和语义信息。
尽管存在局限性,N-gram模型由于其简单性和实用性,在许多 NLP 任务中仍然被广泛使用。在某些应用中,结合N-gram模型和其他技术(如深度学习模型)可以获得更好的性能。
1.4.3 Word2Vec
Word2Vec是一种流行的词嵌入(Word Embedding)技术,由Tomas Mikolov等人在2013年提出。它是一种基于神经网络NNLM的语言模型,旨在通过学习词与词之间的上下文关系来生成词的密集向量表示。Word2Vec的核心思想是利用词在文本中的上下文信息来捕捉词之间的语义关系,从而使得语义相似或相关的词在向量空间中距离较近。
Word2Vec模型主要有两种架构:连续词袋模型CBOW(Continuous Bag of Words)是根据目标词上下文中的词对应的词向量, 计算并输出目标词的向量表示;Skip-Gram模型与CBOW模型相反, 是利用目标词的向量表示计算上下文中的词向量. 实践验证CBOW适用于小型数据集, 而Skip-Gram在大型语料中表现更好。
相比于传统的高维稀疏表示(如One-Hot编码),Word2Vec生成的是低维(通常几百维)的密集向量,有助于减少计算复杂度和存储需求。Word2Vec模型能够捕捉到词与词之间的语义关系,比如”国王“和“王后”在向量空间中的位置会比较接近,因为在大量文本中,它们通常会出现在相似的上下文中。Word2Vec模型也可以很好的泛化到未见过的词,因为它是基于上下文信息学习的,而不是基于词典。但由于CBOW/Skip-Gram模型是基于局部上下文的,无法捕捉到长距离的依赖关系,缺乏整体的词与词之间的关系,因此在一些复杂的语义任务上表现不佳。
1.4.4 ELMo
ELMo(Embeddings from Language Models)实现了一词多义、静态词向量到动态词向量的跨越式转变。首先在大型语料库上训练语言模型,得到词向量模型,然后在特定任务上对模型进行微调,得到更适合该任务的词向量,ELMo首次将预训练思想引入到词向量的生成中,使用双向LSTM结构,能够捕捉到词汇的上下文信息,生成更加丰富和准确的词向量表示。
ELMo采用典型的两阶段过程: 第1个阶段是利用语言模型进行预训练; 第2个阶段是在做特定任务时, 从预训练网络中提取对应单词的词向量作为新特征补充到下游任务中。基于RNN的LSTM模型训练时间长, 特征提取是ELMo模型优化和提升的关键。
ELMo模型的主要优势在于其能够捕捉到词汇的多义性和上下文信息,生成的词向量更加丰富和准确,适用于多种 NLP 任务。然而,ELMo模型也存在一些问题,如模型复杂度高、训练时间长、计算资源消耗大等。
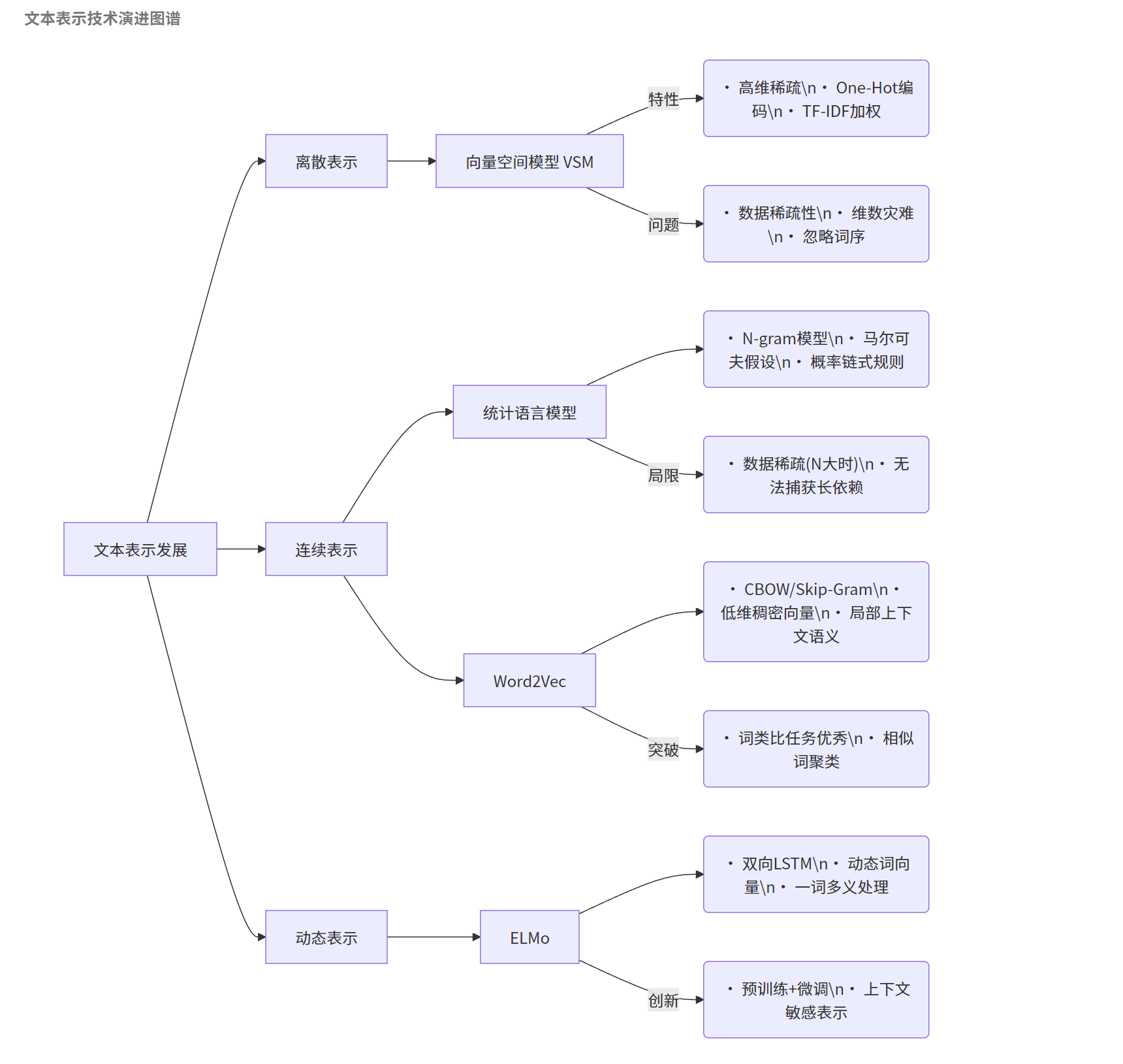
1.4.5 总结
以下是针对文本表示发展历程的工作流图谱,采用技术演进时间轴+关键特性对比的方式呈现,便于记忆和对比:
文本表示技术演进图谱
flowchart LR
A[文本表示发展] --> B[离散表示]
A --> C[连续表示]
A --> D[动态表示]
B --> B1["向量空间模型 VSM"]
B1 -->|特性| B1a("• 高维稀疏\n• One-Hot编码\n• TF-IDF加权")
B1 -->|问题| B1b("• 数据稀疏性\n• 维数灾难\n• 忽略词序")
C --> C1["统计语言模型"]
C1 --> C1a("• N-gram模型\n• 马尔可夫假设\n• 概率链式规则")
C1 -->|局限| C1b("• 数据稀疏(N大时)\n• 无法捕获长依赖")
C --> C2["Word2Vec"]
C2 --> C2a("• CBOW/Skip-Gram\n• 低维稠密向量\n• 局部上下文语义")
C2 -->|突破| C2b("• 词类比任务优秀\n• 相似词聚类")
D --> D1["ELMo"]
D1 --> D1a("• 双向LSTM\n• 动态词向量\n• 一词多义处理")
D1 -->|创新| D1b("• 预训练+微调\n• 上下文敏感表示")关键对比表(结构化记忆)
| 技术阶段 | 代表模型 | 核心思想 | 优势 | 缺陷 | 典型应用场景 |
|---|---|---|---|---|---|
| 离散表示 | VSM | 词袋模型+权重计算 | 简单直观,易于实现 | 高维稀疏,语义丢失 | 早期文本分类/检索 |
| 统计模型 | N-gram | 马尔可夫链概率建模 | 捕获局部词序关系 | 数据稀疏,无法长依赖 | 语音识别/拼写纠错 |
| 连续表示 | Word2Vec | 神经网络学习词嵌入 | 稠密向量,语义相似性 | 静态向量,一词一义 | 词相似度计算 |
| 动态表示 | ELMo | 上下文敏感的双向语言模型 | 一词多义,动态调整 | 计算复杂度高 | 复杂语义任务 |
记忆锚点示例
VSM稀疏性问题
# "雍和宫的荷花很美" 的16384维One-Hot表示 [0,0,...,1(雍和宫),0,...,1(的),...,1(荷花),...,1(很),...,1(美),...] # 有效信息仅5/16384≈0.03%N-gram概率计算
P("fox"|"quick brown") = \frac{count("quick brown fox")}{count("quick brown")}Word2Vec词类比
king - man + woman ≈ queenELMo动态特性
"苹果"在以下句子的向量不同: - 我吃了一个[苹果] - [苹果]公司发布了新手机
技术演进关键突破
- 维度变化:高维稀疏 → 低维稠密 → 动态维度
- 语义捕获:词频统计 → 局部语义 → 全局上下文
- 计算范式:规则加权 → 统计概率 → 神经网络
建议将此图谱与具体代码示例(如TF-IDF计算、Word2Vec训练)结合实践,可强化记忆效果。
第二章 Transformer 架构
0. Task03打卡:
- Transformer 是什么?
- 一个处理文本(或序列数据)的超级引擎,是 ChatGPT 等大模型的核心。它不用按顺序读句子,能一下子看到整个句子所有词的关系。
- 核心绝招:自注意力 (Self-Attention)
- 核心思想: 让句子里的每个词都当一次“中心词”。
- 过程:
- 提问 (Q): 中心词问:“句子里的所有词(包括我自己),你们谁跟我关系最铁?”
- 查标签 (K): 每个词亮出自己的“身份标签”。
- 算关系分: 中心词拿自己的“问题”去跟所有词的“标签”匹配打分(点积),分数高的关系近。
- 加权混合 (V): 根据关系分,把所有词本身的意思 (Value) 按分数混合搅拌,得到中心词在这个语境下更丰富的新身份。
- 好处: 每个词的新身份都融合了全局信息,知道自己在整个句子里的角色和上下文。
- 升级版:多头注意力 (Multi-Head Attention)
- 为啥需要? 一个词的关系可能很复杂(语法、意思、指代谁...),单头注意力可能只看懂一种。
- 怎么做? 同时派出好几组专家团队(比如语法组、语义组、指代组...)。
- 各组独立工作: 每组都用自注意力机制,但关注点不同,各自算出中心词的新身份。
- 汇总整合: 把所有组算出的新身份拼起来,再交给一个整合专家压缩回一个更厉害的新身份。
- 好处: 对词语关系的理解更全面、更深入。
- Transformer 大楼:编码器 (Encoder) 和解码器 (Decoder)
- 编码器 (理解者):
- 任务: 深度阅读理解输入句子(比如一句中文)。
- 结构: 由好几层(比如 6 层)相同的砖块堆成。
- 每层砖块干两件事:
- 用多头自注意力 让句子里的词充分交流,更新各自的身份(理解上下文)。
- 过一个“小脑” (FFN) 对更新后的身份进行加工提炼。
- 稳定器: 每件事做完后,都把原始输入加回来 (残差连接),然后做个“标准化” (层归一化),防止训练跑偏或崩溃。
- 输出: 一个富含上下文信息的句子表示(每个词都变成了深刻理解后的向量)。
- 解码器 (生成者):
- 任务: 根据编码器的理解结果,一个字一个字地生成目标句子(比如翻译后的英文)。
- 结构: 也由好几层相同的砖块堆成。
- 每层砖块干三件事 (比编码器多一件):
- 带遮罩的多头自注意力: 只关注已经生成的词(看自己写了啥)。关键: 生成当前词时,用“遮罩”挡住还没生成的词(不能作弊看未来)。
- 交叉注意力 (关键!): 主动去问编码器:“根据我目前写的内容和你们的理解,我现在该生成什么词最合适?” (Query 来自解码器当前状态,Key/Value 来自编码器输出)。
- 过一个“小脑” (FFN) 加工提炼信息。
- 稳定器: 同样,每件事做完后都有残差连接 + 层归一化。
- 输出: 最终层输出经过一个**“选词专家” (Linear + Softmax)**,预测下一个词的概率。
- 编码器 (理解者):
- Transformer 为啥厉害?
- 并行计算快: 不像 RNN 必须一个个算,Transformer 的矩阵运算可以大规模并行,训练超快。
- 看得远记得清: 自注意力让每个词都能直接关注到句子最远端的词,彻底解决“记性差”问题。
- 理解力超强: 多头机制让它能多维度、深层次理解词语间复杂关系。
- 基石地位: 它是几乎所有现代大语言模型 (BERT, GPT 等) 的基础设计蓝图。
划重点!记住三个核心:
自注意力 (Self-Attention): “划重点”机制,让每个词都能全局扫描句子,找到相关信息融合到自己身上。
多头 (Multi-Head): 派多个专家从不同角度划重点,理解更全面。
编码器-解码器 (Encoder-Decoder): 理解 (Encoder) 和 生成 (Decoder) 分开。生成时,解码器要回头看自己写了啥 (Masked Attn),更要主动问编码器理解了什么 (Cross Attn)。
文章正文如下,需要反复理解阅读:
1. 为什么 LLM 基石——Transformer 架构。
- 痛点: RNN/LSTM 处理长序列时存在梯度消失/爆炸问题,难以并行计算(必须按顺序处理),速度慢。
- 革命: Transformer (2017年论文 Attention is All You Need 提出) 彻底抛弃 RNN,完全依赖注意力机制,解决了并行化问题,成为 NLP 乃至多模态领域的霸主架构。
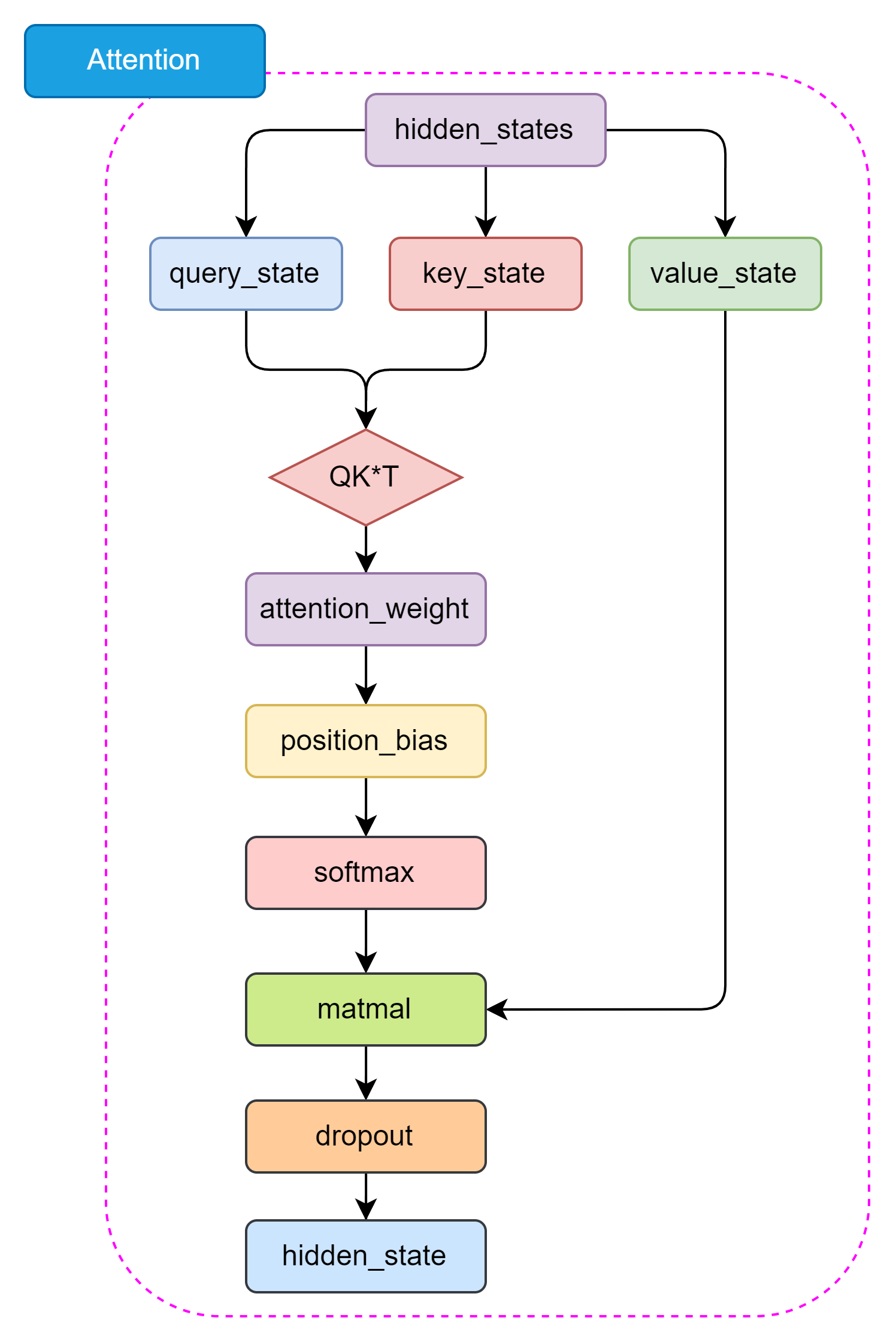
2. 核心机制:自注意力 (Self-Attention)
- 目标: 让序列中的每个词都能同时关注序列中所有其他词(包括自己),捕捉长距离依赖。
- 关键概念:
- Query (Q), Key (K), Value (V): 每个输入词向量通过三个不同的权重矩阵
W_q,W_k,W_v线性变换得到 Q, K, V 向量。理解:Q 是“我要找什么”,K 是“我有什么标签”,V 是“我实际代表什么”。 - 注意力分数 (Attention Score): 计算一个词 (Q) 与其他所有词 (K) 的关联程度。通常用 点积
Q · K^T计算(然后除以sqrt(d_k)防止数值过大)。 - Softmax: 对注意力分数进行归一化,得到权重 (0 到 1 之间,总和为 1)。权重大的表示关联性强。
- 加权求和: 用 Softmax 得到的权重对值向量 (V) 进行加权求和,得到该词的输出向量。这个输出向量融合了整个序列的相关信息。
- Query (Q), Key (K), Value (V): 每个输入词向量通过三个不同的权重矩阵
- 公式 (核心):
Attention(Q, K, V) = softmax(QK^T / sqrt(d_k)) V - 大白话: 想象你在读一句话。自注意力让句子里的每个词都当一次“提问者”。它问:“句子里的所有词(包括我自己),哪些跟我最相关?有多相关?” 然后根据这个“相关度分数”,把其他词的含义信息(V)按分数加权混合起来,形成这个词在这个语境下更丰富、更准确的新表示。
3 多头注意力 (Multi-Head Attention)
- 动机: 单一的注意力机制可能只关注到一种模式的关系(如语法、语义、指代等)。
- 做法: 把 Q, K, V 投影到
h个(比如 8 个)不同的“子空间”(通过h组不同的W_q, W_k, W_v矩阵)。在每个子空间里独立做一次自注意力,得到h个输出向量。 - 拼接与投影: 把这
h个输出向量拼接 (Concat) 起来,再通过一个线性投影层 (Wo) 映射回原始维度,得到最终输出。 - 好处: 模型能并行地在不同子空间学习到不同方面的依赖关系(比如一个头关注语法结构,一个头关注语义相似,一个头关注指代关系等),增强了模型的表示能力。
- 大白话: 单头注意力好比一个人看问题只有一个角度。多头注意力是派了多组专家团队,每组从不同的专业视角(语法专家、语义专家、上下文专家等)分别去分析句子中词语间的关系。最后把所有专家团队的结论汇总整合,得出一个更全面、更深入的理解。
4 Transformer 架构总览 (Encoder-Decoder)
- 主要组件:
- 输入嵌入 (Input Embedding) + 位置编码 (Positional Encoding): 将单词 ID 转为稠密向量 (Embedding),并加上表示单词在句子中位置信息的编码 (Positional Encoding)。(因为 Transformer 本身没有位置概念,需要显式告知位置)。
- 编码器 (Encoder) 堆叠 N 层: 每层包含两个核心子层:
- 多头自注意力层 (Multi-Head Self-Attention): 处理输入序列,每个位置都能关注序列所有位置。
- 前馈神经网络层 (Feed Forward Network - FFN): 通常是一个包含 ReLU 激活函数的两层 MLP。作用:对自注意力层的输出进行非线性变换和特征增强。
- 残差连接 (Residual Connection) + 层归一化 (Layer Normalization): 每个子层周围应用!子层输入直接加到子层输出上 (
Output = Sublayer(x) + x),然后进行层归一化。作用: 解决深层网络梯度消失/爆炸,加速训练收敛,稳定网络。
- 解码器 (Decoder) 堆叠 N 层: 每层包含三个核心子层:
- 带掩码的多头自注意力层 (Masked Multi-Head Self-Attention): 处理已生成的输出序列。掩码 (Mask): 确保在生成第
t个词时,只能看到1到t-1位置的词(不能看到未来信息),保证自回归生成。 - 多头交叉注意力层 (Multi-Head Cross-Attention): Query 来自解码器上一层的输出,Key 和 Value 来自编码器最终的输出。作用:让解码器在生成当前词时,能够聚焦于输入序列中最相关的部分。
- 前馈神经网络层 (FFN): 同编码器。
- 残差连接 (Residual Connection) + 层归一化 (Layer Normalization): 同样应用于每个子层周围。
- 带掩码的多头自注意力层 (Masked Multi-Head Self-Attention): 处理已生成的输出序列。掩码 (Mask): 确保在生成第
- 线性层 (Linear Layer) + Softmax: 解码器最终输出经过线性层映射到词汇表大小的向量,再通过 Softmax 转换为下一个词的概率分布。
5. 关键优势总结
- 强大的并行性: 核心运算 (矩阵乘法) 高度并行,训练速度远超 RNN。
- 捕捉长距离依赖: 自注意力机制天然能关注序列中任意距离的元素。
- 强大的表示能力: 多头注意力机制能学习多种复杂的依赖关系。
- 成为基石: 是 BERT, GPT, T5 等几乎所有现代 LLM 的核心架构或重要灵感来源。
6.搭建一个 Transformer
6.1 Embedding概念解释
概念:
Embedding 层的作用,就像是“给每个词一个专属的向量名片”。
你输入的是一个二维的整数矩阵 (batch_size, seq_len),里面装的是词的编号,比如 [ [0, 1, 2] ] 表示一句话有3个词。
Embedding 层内部藏着一本“向量字典”(形状是 (vocab_size, embedding_dim)),每个编号都有一条向量表示。
模型训练时,这些向量会被不断优化,让它们能表达出词的语义特征。
所以你一输入 token 编号,Embedding 就去字典里“查号入座”,拿出对应的向量,拼成一个新的矩阵,形状是 (batch_size, seq_len, embedding_dim)。这就是模型能理解的向量版本的语言了。
实例
“我喜欢你”**
第一步:Tokenizer 分词+编码(词 → index)
假设我们的词表是这样的(词表大小 vocab_size = 5):
| Token令 牌 | Index指数 |
|---|---|
| 我 | 0 |
| 喜欢 | 1 |
| 你 | 2 |
| 他 | 3 |
| 吃饭 | 4 |
🔧 输入 “我喜欢你”
👇 Tokenizer 处理后得到 token 索引序列:
python
复制编辑
[ [0, 1, 2] ] # batch_size=1, seq_len=3第二步:Embedding 层查向量(index → vector)
我们设:
embedding_dim = 4(每个 token 用4维向量表示)- Embedding 层内部的参数矩阵是:
python复制编辑# (vocab_size=5, embedding_dim=4)
Embedding Table (可训练参数):
Index 0(我): [0.1, 0.2, 0.3, 0.4]
Index 1(喜欢): [0.5, 0.6, 0.7, 0.8]
Index 2(你): [0.9, 1.0, 1.1, 1.2]
...现在,输入 [ [0, 1, 2] ] 就相当于在这个表里查:
python复制编辑输出:
[[
[0.1, 0.2, 0.3, 0.4], # 我
[0.5, 0.6, 0.7, 0.8], # 喜欢
[0.9, 1.0, 1.1, 1.2] # 你
]]
# shape: (batch_size=1, seq_len=3, embedding_dim=4)最终结果
输入的 [ [0, 1, 2] ]
👉 经过 Embedding 层
👉 输出成 (1, 3, 4) 的浮点向量矩阵!
6.2 位置编码
1. 为什么要“位置编码”?
注意力机制不看顺序。
句子“我喜欢你” 和 “你喜欢我” 对它来说完全一样。
但语言讲究顺序,我们得告诉模型:谁在前谁在后。
所以,Transformer 要加一个“位置信息” —— 这就是**位置编码(Positional Encoding)**的用处。
2. 怎么编码?——正余弦函数公式
Transformer 用的是一种“正弦+余弦波”的绝对位置编码:
对于某个位置 pos,向量维度为 d_model,第 i 个维度用以下公式:
PE(pos, 2i) = sin(pos / (10000 ^ (2i / d_model)))
PE(pos, 2i+1) = cos(pos / (10000 ^ (2i / d_model)))👀 简化理解:
pos: 第几个词(0开始)2i,2i+1: 奇偶位分开编码10000是为了缩放(调节不同频率)- sin / cos 保证不同位置有不同的“编码曲线”
3. 举个例子(让你真感受到)
假设我们句子是:
“I like to code”,共 4 个词,向量维度 4(简化看)
我们用 x 表示原始词向量:
x = [
[0.1, 0.2, 0.3, 0.4], # I
[0.2, 0.3, 0.4, 0.5], # like
[0.3, 0.4, 0.5, 0.6], # to
[0.4, 0.5, 0.6, 0.7] # code
]然后我们给每一行加上位置编码:
x_pe = x + pos_encoding也就是说,第 0 个词加 pos=0 的位置编码;第 1 个词加 pos=1 的位置编码;以此类推。
那位置编码长啥样?
我们不手算公式(有点复杂),但你可以理解成:
| 位置 | 编码前(词向量) | 位置编码(sin、cos 曲线) | 编码后(相加) |
|---|---|---|---|
| 0 | [0.1, 0.2, 0.3, 0.4] | [0.0, 1.0, 0.0, 1.0] | [0.1, 1.2, 0.3, 1.4] |
| 1 | [0.2, 0.3, 0.4, 0.5] | [0.84, 0.54, 0.91, 0.41] | [1.04, 0.84, 1.31, 0.91] |
| … | … | … | … |
你最后得到的是一个:
(batch_size, seq_len, embedding_dim)的向量矩阵,它既包含了词的语义(词向量),又包含了词的位置(位置编码)!
6.3 最后让我们来实现完整的 Transformer 模型:
第一步:类定义和初始化
class Transformer(nn.Module):
def __init__(self, args):
super().__init__()👉 创建一个名叫 Transformer 的类,继承自 PyTorch 的 nn.Module,这是构建神经网络的标准做法。
✅ 模块初始化(搭建“骨架”)
self.transformer = nn.ModuleDict(dict(
wte = nn.Embedding(args.vocab_size, args.n_embd), # Token Embedding
wpe = PositionalEncoding(args), # 位置编码模块
drop = nn.Dropout(args.dropout), # Dropout 随机丢弃,防止过拟合
encoder = Encoder(args), # 编码器模块
decoder = Decoder(args), # 解码器模块
))这段就像在搭积木,把整个 Transformer 的核心结构拼起来:
| 模块名 | 作用 |
|---|---|
wte | 把词变成向量(Word Token Embedding) |
wpe | 加位置信息(Positional Encoding) |
drop | 正常训练时随机扔掉部分神经元(Dropout) |
encoder | 把输入处理成上下文相关的表示 |
decoder | 根据 encoder 的输出生成新序列(用于翻译等任务) |
输出层(分类器)
self.lm_head = nn.Linear(args.n_embd, args.vocab_size, bias=False)最后一步是个线性层,用来把模型的输出转成“每个词的概率”,比如“你”的概率 0.1、“我”的概率 0.2。
权重初始化 + 参数统计
self.apply(self._init_weights)
print("number of parameters: %.2fM" % (self.get_num_params()/1e6,))初始化:每一层的权重随机生成(但可控),否则模型一动不动。
打印参数数量,供调试或炫耀用 😎。
第二步:前向传播(核心函数)
def forward(self, idx, targets=None):模型运行时,从这里开始,“输入一句话”走完整个模型流程。
1⃣ 输入检查
b, t = idx.size()
assert t <= self.args.block_sizeb: batch size,比如一次送进来 32 句话
t: 每句话有多少词(token 数量)
2⃣ Token Embedding:词 → 向量2⃣ 标记嵌入:词 → 向量
tok_emb = self.transformer.wte(idx)把 [ [0, 1, 2] ] 转成:
[
[0.1, 0.2, 0.3, 0.4], # 第一个词
[0.4, 0.3, 0.6, 0.8], # 第二个词
...
]形状从 (b, t) 变成 (b, t, n_embd)。
3⃣ 加位置编码
pos_emb = self.transformer.wpe(tok_emb)每个 token 的向量加上了“你第几个”的信息(通过正余弦函数),得到更聪明的嵌入向量。
4⃣ Dropout
x = self.transformer.drop(pos_emb)在训练时随机丢掉部分元素,避免模型死记硬背。
5⃣ 编码器(Encoder)
enc_out = self.transformer.encoder(x)这一步相当于:模型开始“理解上下文”,让每个词知道“句子里其他词的存在”。
6⃣ 解码器(Decoder)
x = self.transformer.decoder(x, enc_out)这一步是针对某些任务(比如翻译)才用的,它可以根据输入句子生成输出句子。
🧾 最终输出:
logits = self.lm_head(x[:, [-1], :])x是最后一层的输出lm_head把它转成“每个词的概率分布”[:, [-1], :]表示只取句子最后一个词的输出结果(因为我们是一个一个生成的)
✅ 如果训练,就计算 loss:
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)如果你给了“标准答案”,那就比较预测和真实结果的差异(用交叉熵函数),来更新模型。
🔁 模型运行全流程总结
文本句子 → tokenizer → token index (idx)
↓
Embedding (tok_emb)
↓
位置编码 (pos_emb)
↓
Dropout
↓
Encoder → 得到 enc_out(理解上下文)
↓
Decoder(根据上下文生成目标)
↓
Linear + Softmax → 得到 logits(预测下一个词)
↓
与 targets 比较 → loss(训练阶段)代码部分:
class Transformer(nn.Module):
'''整体模型'''
def __init__(self, args):
super().__init__()
# 必须输入词表大小和 block size
assert args.vocab_size is not None
assert args.block_size is not None
self.args = args
self.transformer = nn.ModuleDict(dict(
wte = nn.Embedding(args.vocab_size, args.n_embd),
wpe = PositionalEncoding(args),
drop = nn.Dropout(args.dropout),
encoder = Encoder(args),
decoder = Decoder(args),
))
# 最后的线性层,输入是 n_embd,输出是词表大小
self.lm_head = nn.Linear(args.n_embd, args.vocab_size, bias=False)
# 初始化所有的权重
self.apply(self._init_weights)
# 查看所有参数的数量
print("number of parameters: %.2fM" % (self.get_num_params()/1e6,))
'''统计所有参数的数量'''
def get_num_params(self, non_embedding=False):
# non_embedding: 是否统计 embedding 的参数
n_params = sum(p.numel() for p in self.parameters())
# 如果不统计 embedding 的参数,就减去
if non_embedding:
n_params -= self.transformer.wpe.weight.numel()
return n_params
'''初始化权重'''
def _init_weights(self, module):
# 线性层和 Embedding 层初始化为正则分布
if isinstance(module, nn.Linear):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
if module.bias is not None:
torch.nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
'''前向计算函数'''
def forward(self, idx, targets=None):
# 输入为 idx,维度为 (batch size, sequence length, 1);targets 为目标序列,用于计算 loss
device = idx.device
b, t = idx.size()
assert t <= self.args.block_size, f"不能计算该序列,该序列长度为 {t}, 最大序列长度只有 {self.args.block_size}"
# 通过 self.transformer
# 首先将输入 idx 通过 Embedding 层,得到维度为 (batch size, sequence length, n_embd)
print("idx",idx.size())
# 通过 Embedding 层
tok_emb = self.transformer.wte(idx)
print("tok_emb",tok_emb.size())
# 然后通过位置编码
pos_emb = self.transformer.wpe(tok_emb)
# 再进行 Dropout
x = self.transformer.drop(pos_emb)
# 然后通过 Encoder
print("x after wpe:",x.size())
enc_out = self.transformer.encoder(x)
print("enc_out:",enc_out.size())
# 再通过 Decoder
x = self.transformer.decoder(x, enc_out)
print("x after decoder:",x.size())
if targets is not None:
# 训练阶段,如果我们给了 targets,就计算 loss
# 先通过最后的 Linear 层,得到维度为 (batch size, sequence length, vocab size)
logits = self.lm_head(x)
# 再跟 targets 计算交叉熵
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
else:
# 推理阶段,我们只需要 logits,loss 为 None
# 取 -1 是只取序列中的最后一个作为输出
logits = self.lm_head(x[:, [-1], :]) # note: using list [-1] to preserve the time dim
loss = None
return logits, loss第三章 预训练语言模型
3.1 Encoder-only PLM
Encoder-only 预训练语言模型(PLM)主要包括 BERT、RoBERTa、ELECTRA 等,是以 Transformer 编码器结构 为基础,仅使用输入的上下文信息进行理解任务,不生成新文本。
📌 要点概念简析:
- 结构组成:
- 多层 Transformer Encoder。
- 每一层包含多头注意力机制(Multi-head Self-Attention)和前馈神经网络(Feed Forward)。
- 输入处理:
- 通常是完整文本(句子对或单句),进行 Tokenization 和 Position Embedding。
- 添加特殊标志如
[CLS](分类)和[SEP](句子分隔)。
- 预训练目标:MLM(Masked Language Modeling)
- 随机遮盖输入中15%的token,训练模型预测被遮盖的内容。
- 例:
我喜欢[mask]球➝ 预测“足球”。
- 适用任务:
- 分类(情感分析、文本类型识别)、实体识别、问答(抽取式)、句子对判断等。
- 特点总结:
- 优势:双向建模能力强,适合语义理解任务。
- 局限:不具备文本生成能力。
示例模型对比(简要):
| 模型 | 预训练方式 | 典型用途 |
|---|---|---|
| BERT | MLM | 语义理解、问答 |
| RoBERTa | 更大数据+动态mask | 更强性能的BERT |
| ELECTRA | 生成器-判别器训练(替代MLM) | 更高效训练 |
graph TB
A[输入文本] --> B[Tokenizer:切词 + 编码]
B --> C[Embedding:Token + Position Embedding]
C --> D[多层Transformer Encoder]
D --> E1[分类任务(取CLS)]
D --> E2[命名实体识别(逐Token)]
D --> E3[问答匹配(取句向量)]3.2 Encoder-Decoder PLM
引入
T5 基于 Transformer 架构,包含编码器和解码器两个部分。
T5 (Text-To-Text Transfer Transformer)是由 Google 提出的一种预训练语言模型,通过将所有 NLP 任务统一表示为文本到文本的转换问题
从模型结构、预训练任务和大一统思想三个方面来介绍 T5 模型。
1 模型结构
编码器和解码器组成:编码器就是将输入数据处理成机器语言,解码器就是将机器语言解码为文本。
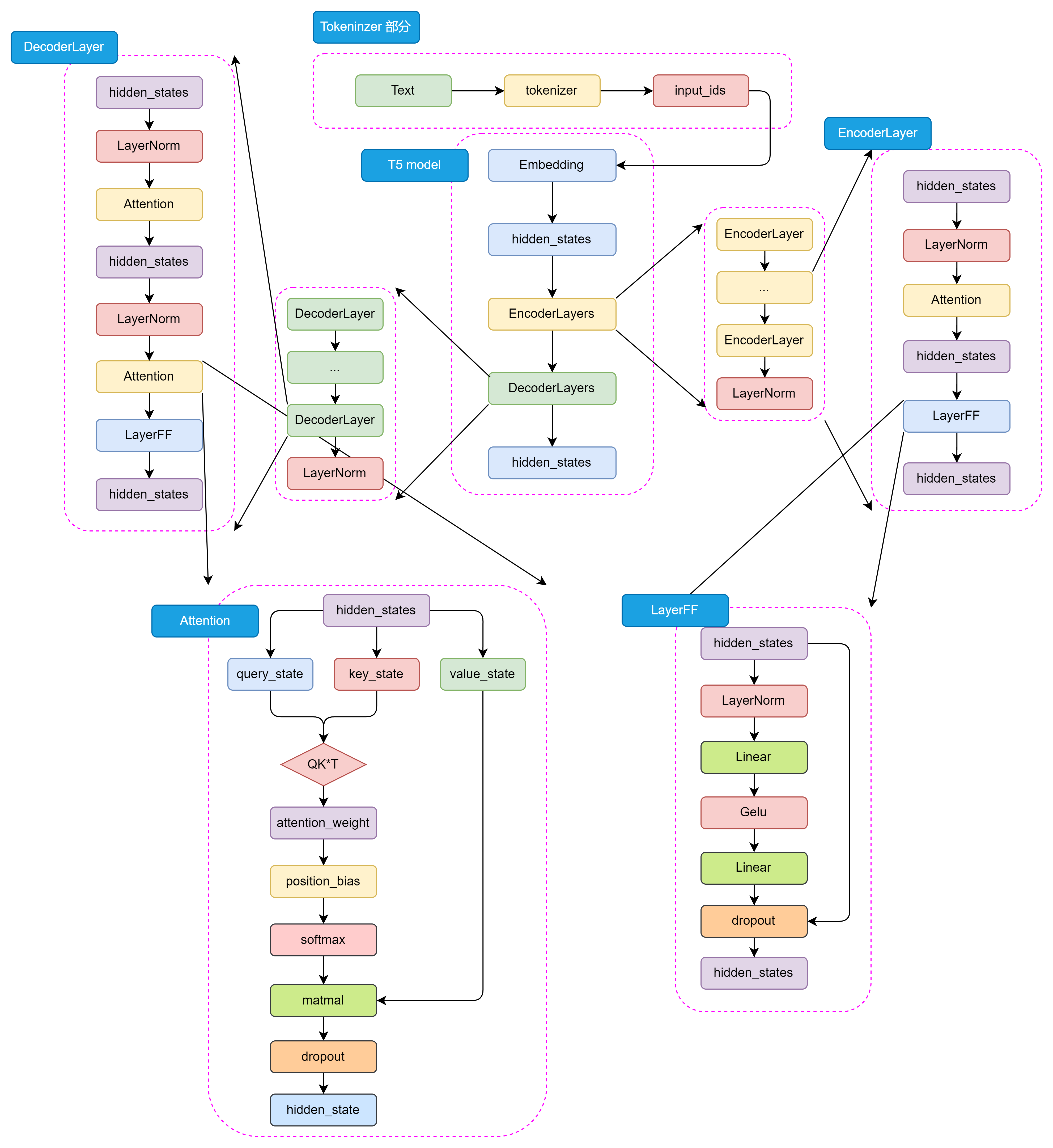
从图中可得 T5有两个部分组成: Tokeninzer部分和Transformer部分。Tokenizer部分负责将输入转为Embeedding可以接受的格式。Transformer部分又分为EncoderLayers和DecoderLayers两个部分。
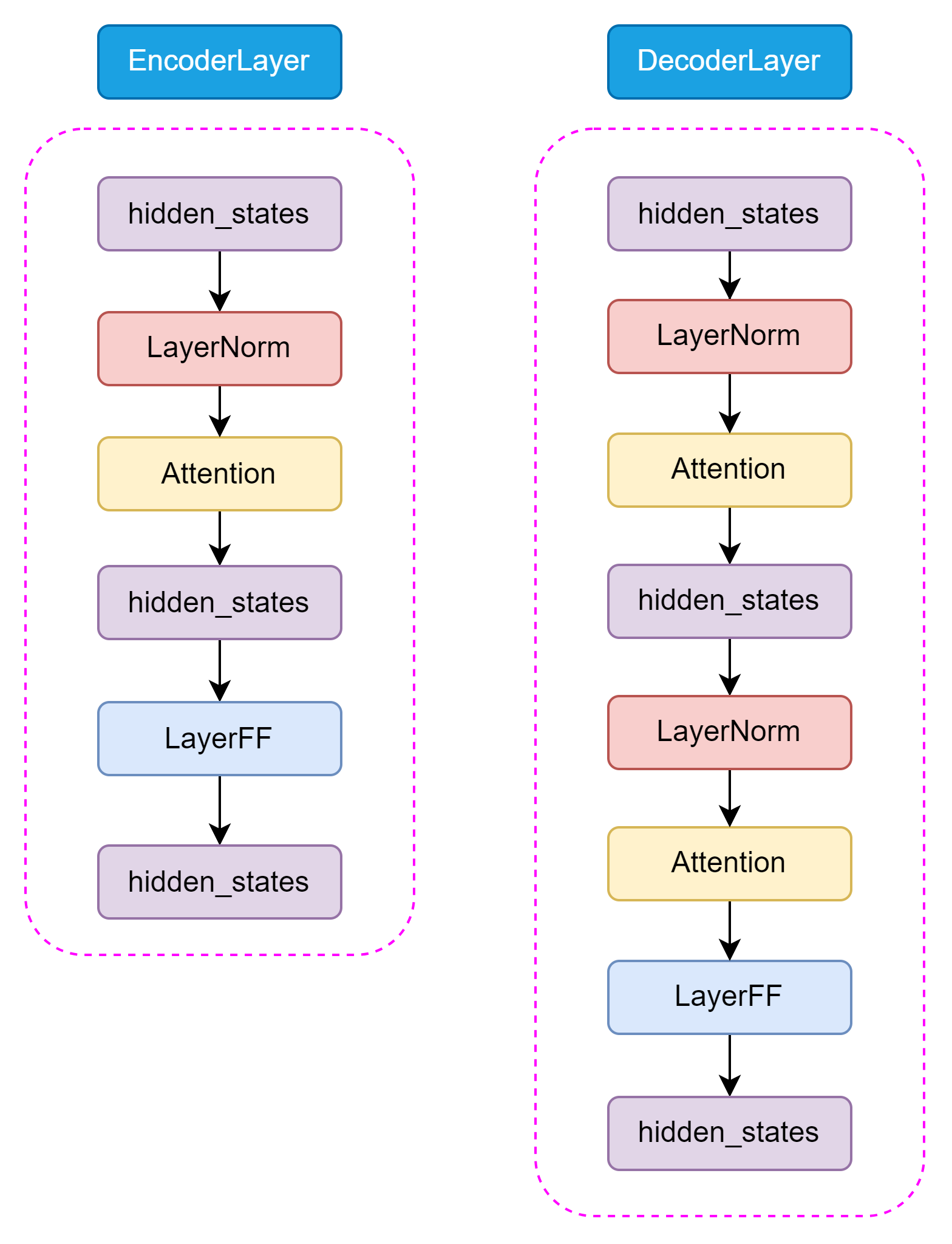
T5模型中的Encoder和Decoder基于Transformer架构设计,主要包括Self-Attention和前馈神经网络,Self-Attention就是对一句话进行理解时会关注文章中的其他相关的内容。而前馈神经网络如同在Transformer理解句子含义后,对句子进行深层次分析。
Self-Attention 结构如下:
2 预训练任务
预训练任务是T5的一个关键的组成部分,它能够使模型能够微调。
预训练任务的组成:预训练任务、输入格式、预训练数据集、多任务预训练、预训练到微调的转换
3 大一统思想
T5模型的一个核心理念是“大一统思想”,即所有的 NLP 任务都可以统一为文本到文本的任务
3.3 Decoder-Only PLM
Decoder-Only 就是目前大火的 LLM 的基础架构。
3.3.1 GPT
GPT,即 Generative Pre-Training Language Model
1 模型架构——Decoder Only
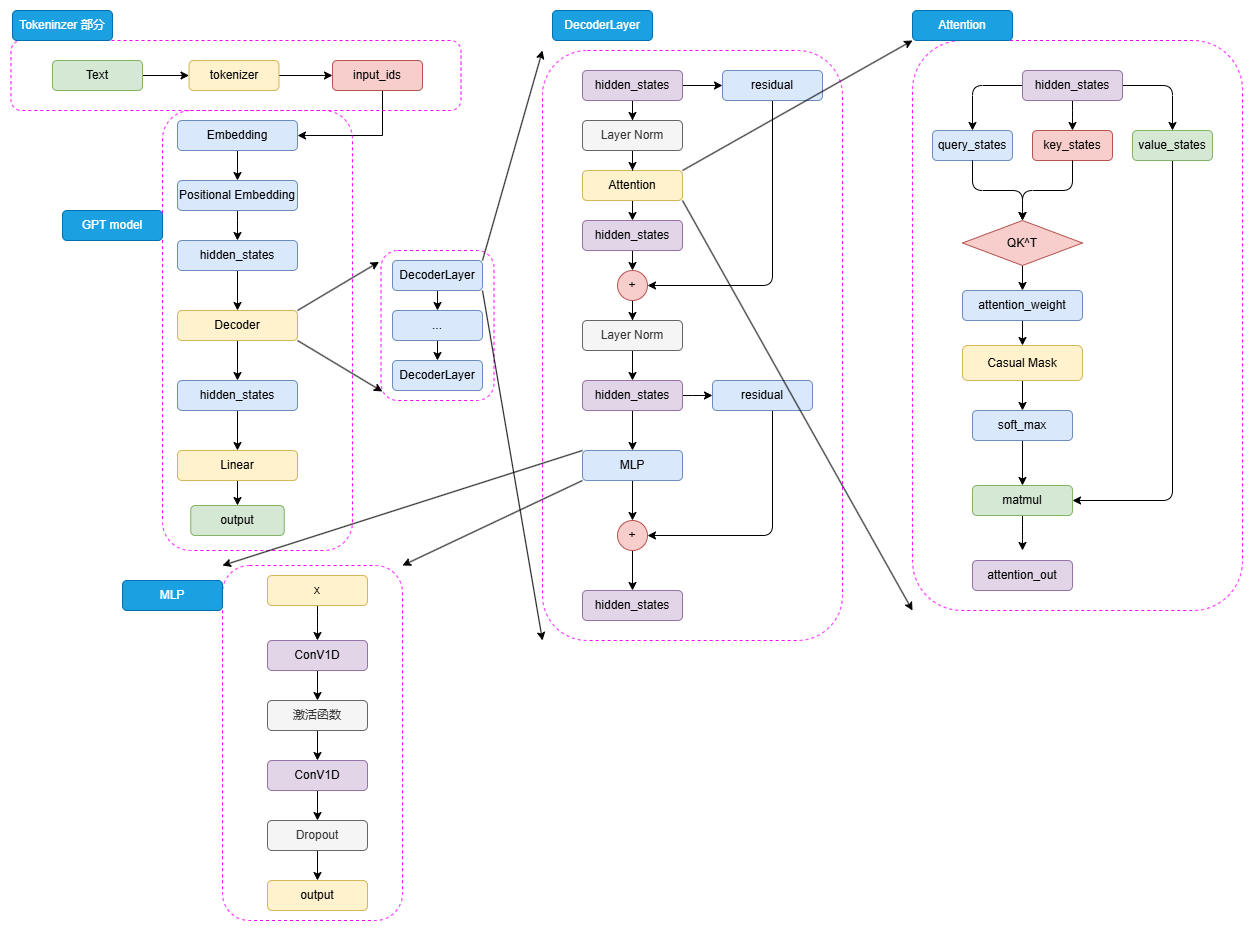
我们用流程图来理解GPT的Decoder-only架构:
graph TD
A[原始文本输入] --> B[tokenizer 分词 → input_ids]
B --> C[Embedding:词向量编码]
C --> D[位置编码:三角函数Sin编码]
D --> E[初始 hidden_states]
E --> F[Decoder 层 × N次循环(默认12次)]
subgraph Decoder 层 单次处理
F1[LayerNorm 归一化]
F2[掩码自注意力计算]
F3[残差连接]
F4[LayerNorm 归一化2]
F5[MLP:两个1维卷积核提特征]
F6[残差连接2]
F1 --> F2 --> F3 --> F4 --> F5 --> F6
end
F --> G[输出 hidden_states]
G --> H[Linear 映射 → 词表大小]
H --> I[生成新 token(一个个生成)]💬 Encoder-Only 每步大白话解释如下:
🅰️ 原始文本输入
用户输入一句话,比如:“我想吃火锅”。
🅱️ Tokenizer 分词 → 转成数字
就像翻字典一样,每个词或字都会查出一个编号,比如:
- “我” → 102
- “想” → 203
- “吃” → 304
...
这些编号就是 input_ids。
🅲 Embedding 词向量
每个词的编号还不够看,要变成有语义的“词向量”,就是给每个词贴上“理解用的数字描述”。
🅳 位置编码(Positional Embedding)
因为神经网络不记顺序,要加点“我是第几个词”的信息。
GPT 用的是三角函数编码方式(sin/cos),简单高效,不用训练。
🅴 初始 hidden_states
Embedding + 位置编码之后,变成了带顺序的词语理解向量,准备进主菜——Decoder 层。
🅵 Decoder 层(12次打怪升级)
每一层干几件事:
1️⃣ LayerNorm:洗干净准备处理
把数据归一化,让模型更稳定,不容易“暴走”。
2️⃣ 掩码自注意力:
- 每个词“看别人”,但不能偷看后面的词
- 所以 GPT 会用遮罩挡住未来内容,只能看见前面
- 注意力机制:决定“我该多关注谁”
3️⃣ 残差连接:
加点“直通车”,防止信息丢失。
4️⃣ 再归一化 LayerNorm:
保持每层数据稳定,再来一遍。
5️⃣ MLP 特征提取(两层卷积):
不是用普通的全连接层,而是“两个1D卷积核”提特征(其实效果差不多,只是做法不一样)。
6️⃣ 再来一次残差连接。
这个过程重复12次(或者更多层),像打怪升级一样逐渐增强理解力。
🅶 最后的 hidden_states
每个词现在都“知道”该说啥了(只知道前文,没看后文)。
🅷 映射到词表维度
用一个线性矩阵,把 hidden_states 映射到“词表的大小”(比如词表有5万个词,就映射成5万个可能性)。
🅸 选词生成 token
每次生成一个 token,然后继续把这个 token 喂进去,再生成下一个……直到生成一整句。
🎯 总结一句话:
GPT 像个“只能看过去”的语言预测大师,它读完前面的词后,不停猜下一个词应该是啥,直到猜完整句话。
3.3.2 预训练任务——CLM
Decoder-Only 模型往往选择了最传统也最直接的预训练任务——因果语言模型,Casual Language Model,下简称 CLM。
3.3.3 GPT 系列模型的发展
下表总结了从 GPT-1 到 GPT-3 的模型结构、预训练语料大小的变化:
| 模型 | Decoder Layer | Hidden_size | 注意力头数 | 注意力维度 | 总参数量 | 预训练语料 |
|---|---|---|---|---|---|---|
| GPT-1 | 12 | 3072 | 12 | 768 | 0.12B | 5GB |
| GPT-2 | 48 | 6400 | 25 | 1600 | 1.5B | 40GB |
| GPT-3 | 96 | 49152 | 96 | 12288 | 175B | 570GB |
3.3.4 LLaMA
1 模型架构——Decoder Only
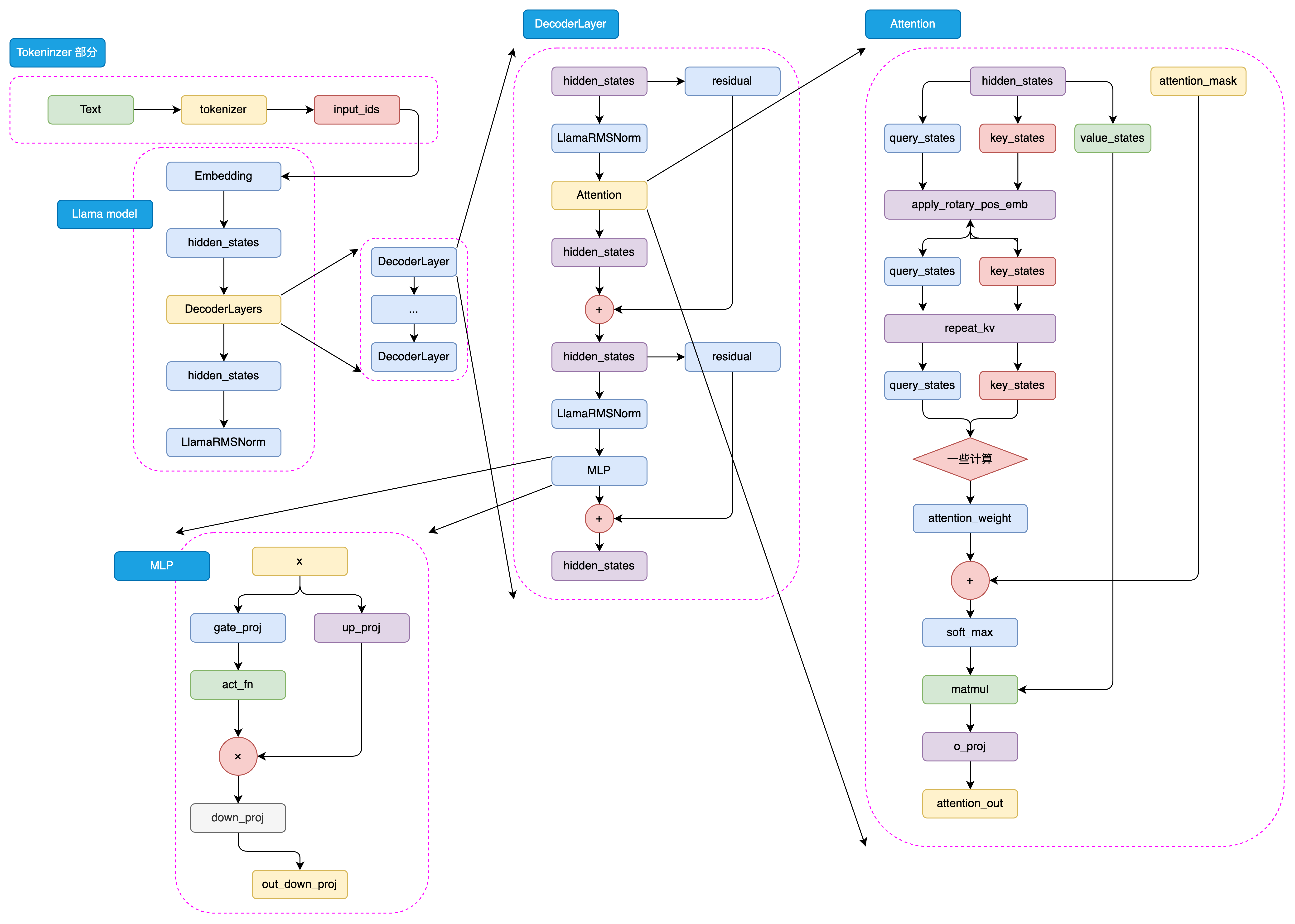
====文章分界线=*****=*********=============
102 FunRec
本教程对于入门推荐算法的同学来说,可以从推荐算法的基础到实战再到面试,形成一个闭环。每个部分的详细内容如下:
- 推荐系统概述。 这部分内容会从推荐系统的意义及应用,到架构及相关的技术栈做一个概述性的总结,目的是为了让初学者更加了解推荐系统。
- 推荐系统算法基础。 这部分会介绍推荐系统中对于算法工程师来说基础并且重要的相关算法,如经典的召回、排序算法。随着项目的迭代,后续还会不断的总结其他的关键算法和技术,如重排、冷启动等。
- 推荐系统实战。 这部分内容包含推荐系统竞赛实战和新闻推荐系统的实践。其中推荐系统竞赛实战是结合阿里天池上的新闻推荐入门赛做的相关内容。新闻推荐系统实践是实现一个具有前后端交互及整个推荐链路的项目,该项目是一个新闻推荐系统的demo没有实际的商业化价值。
- 推荐系统算法面经。 这里会将推荐算法工程师面试过程中常考的一些基础知识、热门技术等面经进行整理,方便同学在有了一定推荐算法基础之后去面试,因为对于初学者来说只有在公司实习学到的东西才是最有价值的。
第一章 推荐系统概述
0.0 Task1 总结
本机内容理论很多,主要从算法和工程两个大方向,通俗易懂地介绍了推荐系统的核心模块、技术应用及所需技能,帮助新手快速建立对推荐系统的整体认知。我主要以技术栈的角度进行总结:
一、推荐系统的核心算法模块
- 推荐流程的四大环节
- 召回:从海量物品中快速挑出几千个可能感兴趣的候选集,就像在大仓库里先粗筛出一批 “可能喜欢” 的东西,讲究速度和全面性,常用多路召回(如根据用户行为、内容标签等不同渠道同时筛选)。
- 粗排:当召回的东西还是太多时,用简单模型快速过滤,减轻后续压力,类似在粗筛后的候选集中再快速淘汰一批明显不合适的。
- 精排:对粗排后的候选集精准打分排序,是推荐系统的核心,会用到深度学习模型(如 DNN、Wide&Deep),结合用户历史行为、物品特征等精细计算 “喜欢程度”。
- 重排:在精排结果基础上,加入运营策略(如节日促销商品提权)、多样性要求(避免推荐内容重复)等,调整最终展示顺序,比如 “三八节多推美妆”“不让同一家店铺的商品连续出现”。
- 画像与多模态理解
- 用户画像与物品画像:给用户打标签(如年龄、爱好),给物品做内容理解(如视频的标题、封面、标签),比如通过用户注册信息和浏览行为知道 “你喜欢美妆”,通过视频分析知道 “这个视频是美妆教程”。
- 多模态技术:处理文本、图片、视频等多种信息,比如用 NLP 分析标题语义,用 CV 识别视频中的人脸或物体,提取特征后用于推荐。
- 关键算法类型
- 召回算法:包括基于协同过滤(“和你类似的人喜欢的东西”)、序列模型(分析用户行为顺序,如 “你之前看了美妆视频,可能接下来想看护肤视频”)、知识图谱(用物品关联关系推荐,如 “买了口红的人常买粉底液”)等。
- 精排算法:深度学习模型为主,如 DNN 处理特征交叉,多任务学习同时优化点击率、观看时长等多个目标(避免只推 “标题党”),强化学习动态调整推荐策略(适应用户兴趣变化)。
二、工程实现所需技术
- 编程语言与框架
- 必学 Python,用于算法开发;Java/Scala、C++ 用于工程落地;SQL 处理数据查询。
- 机器学习框架:TensorFlow/PyTorch 用于搭建深度学习模型,XGBoost/LightGBM 用于快速建模。
- 数据处理与存储
- 数据分析:Pandas 处理小规模数据,Spark/Hadoop 处理大规模数据。
- 数据存储:MySQL 存结构化数据,Redis 存缓存(快速读取用户实时行为),Hive 存历史数据。
- 分布式与流计算
- 分布式框架:Hadoop/Spark 实现大规模数据处理和模型训练。
- 流计算:Flink/Spark Streaming 实时处理用户行为(如用户刚点击的商品,马上用于推荐)。
三、给新手的建议
推荐系统是算法与工程的结合,新手不必贪多,可先在召回或精排模块选一个方向深入,比如掌握双塔模型(DSSM)做召回,或学习 Wide&Deep 做精排,其他技术(如强化学习、跨域推荐)了解原理即可,工作中遇到再深入学习。
文章正文如下,需要反复理解阅读:
1 正文
1.1 推荐系统的意义
推荐系统就是一个将信息生产者和信息消费者连接起来的桥梁。
graph TD
A[用户行为] --> B[数据采集服务]
B --> C[数据存储与预处理]
C --> D[推荐算法引擎]
D --> E[推荐结果生成]
E --> F[前端展示]
F --> G[用户反馈]
G --> C[数据回流]graph TD
%% 用户端
subgraph 用户端
style 用户端 fill:#ffffff,stroke:#cccccc,stroke-width:2px,stroke-dasharray:5,5
A(用户端APP/PC):::layer --> B(行为数据 浏览/加购/购买):::data
A --> C(画像数据性别/消费层级):::data
B --> D(数据采集Flume):::process
C --> E(数据仓库Hive):::process
end
%% 数据处理层
subgraph 数据处理层
style 数据处理层 fill:#ffffff,stroke:#cccccc,stroke-width:2px,stroke-dasharray:5,5
D --> F(实时流处理 Flink):::process
E --> G(离线处理Spark):::process
F --> H{特征存储Redis+HBase}:::storage
G --> H
end
%% 算法层
subgraph 算法层
style 算法层 fill:#ffffff,stroke:#cccccc,stroke-width:2px,stroke-dasharray:5,5
H --> I(召回ItemCF+向量检索):::process
I --> J(排序DeepFM模型):::process
J --> K(重排序 库存过滤+类目打散):::process
end
%% 服务层
subgraph 服务层
style 服务层 fill:#ffffff,stroke:#cccccc,stroke-width:2px,stroke-dasharray:5,5
K --> L(推荐API接口 首页/详情页/购物车):::process
M(A/B测试):::process -.-> I
M -.-> J
M -.-> K
N(监控报警):::process --> L
end
%% 样式定义
classDef process fill:#E5F6FF,stroke:#73A6FF,stroke-width:2px;
classDef data fill:#FFF6CC,stroke:#FFBC52,stroke-width:2px;
classDef storage fill:#FFEBEB,stroke:#E68994,stroke-width:2px;
classDef layer fill:#E5F6E5,stroke:#73A673,stroke-width:2px;
%% 虚线连接样式
linkStyle 12 stroke:#999,stroke-width:1.5px,stroke-dasharray:5,5
linkStyle 13 stroke:#999,stroke-width:1.5px,stroke-dasharray:5,5
linkStyle 14 stroke:#999,stroke-width:1.5px,stroke-dasharray:5,5推荐和搜索的区别
搜索和推荐都是解决互联网大数据时代信息过载的手段,但是它们也存在着许多的不同:
- 用户意图:搜索时的用户意图是非常明确的,用户通过查询的关键词主动发起搜索请求。对于推荐而言,用户的需求是不明确的,推荐系统在通过对用户历史兴趣的分析给用户推荐他们可能感兴趣的内容。
- 个性化程度:对于搜索而言,由于限定的了搜索词,所以展示的内容对于用户来说是有标准答案的,所以搜索的个性化程度较低。而对于推荐来说,推荐的内容本身就是没有标准答案的,每个人都有不同的兴趣,所以每个人展示的内容,个性化程度比较强。
- 优化目标:对于搜索系统而言,更希望可以快速地、准确地定位到标准答案,所以希望搜索结果中答案越靠前越好,通常评价指标有:归一化折损累计收益(NDCG)、精确率(Precision)和召回率(Recall)。对于推荐系统而言,因为没有标准的答案,所以优化目标可能会更宽泛。例如用户停留时长、点击、多样性,评分等。不同的优化目标又可以拆解成具体的不同的评价指标。
- 马太效应和长尾理论:对于搜索系统来说,用户的点击基本都集中在排列靠前的内容上,对于排列靠后的很少会被关注,这就是马太效应。而对于推荐系统来说,热门物品被用户关注更多,冷门物品不怎么被关注的现象也是存在的,所以也存在马太效应。此外,在推荐系统中,冷门物品的数量远远高于热门物品的数量,所以物品的长尾性非常明显。
1.2 推荐系统架构
从下面两个角度:系统架构和算法架构 出发解析推荐系统通用架构
- 系统架构设计思想:
是大数据背景下如何有效利用海量和实时数据,将推荐系统按照对数据利用情况和系统响应要求出发,将整个架构分为离线层、近线层、在线层三个模块。
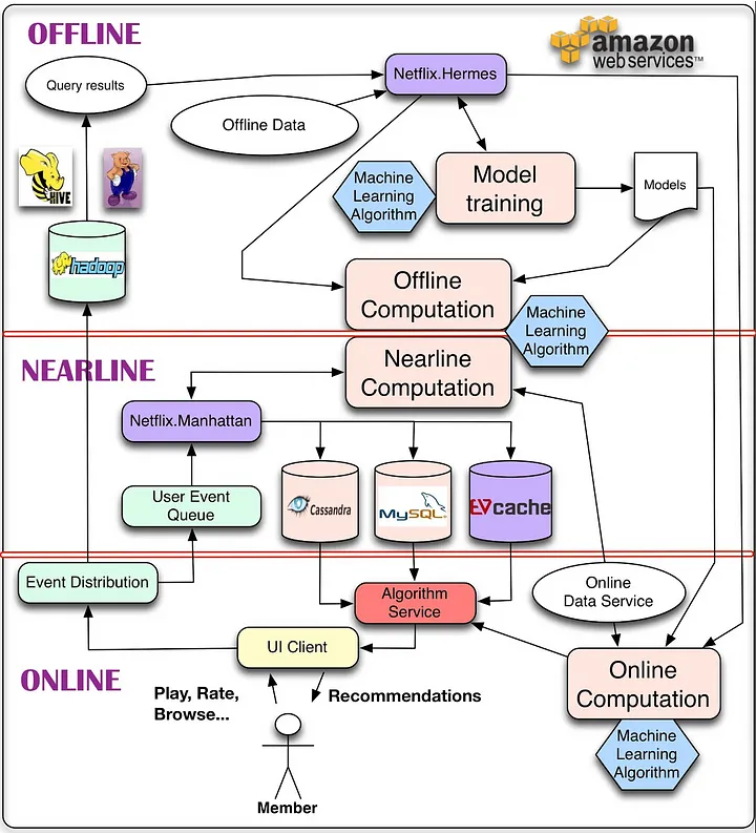
更容易理解
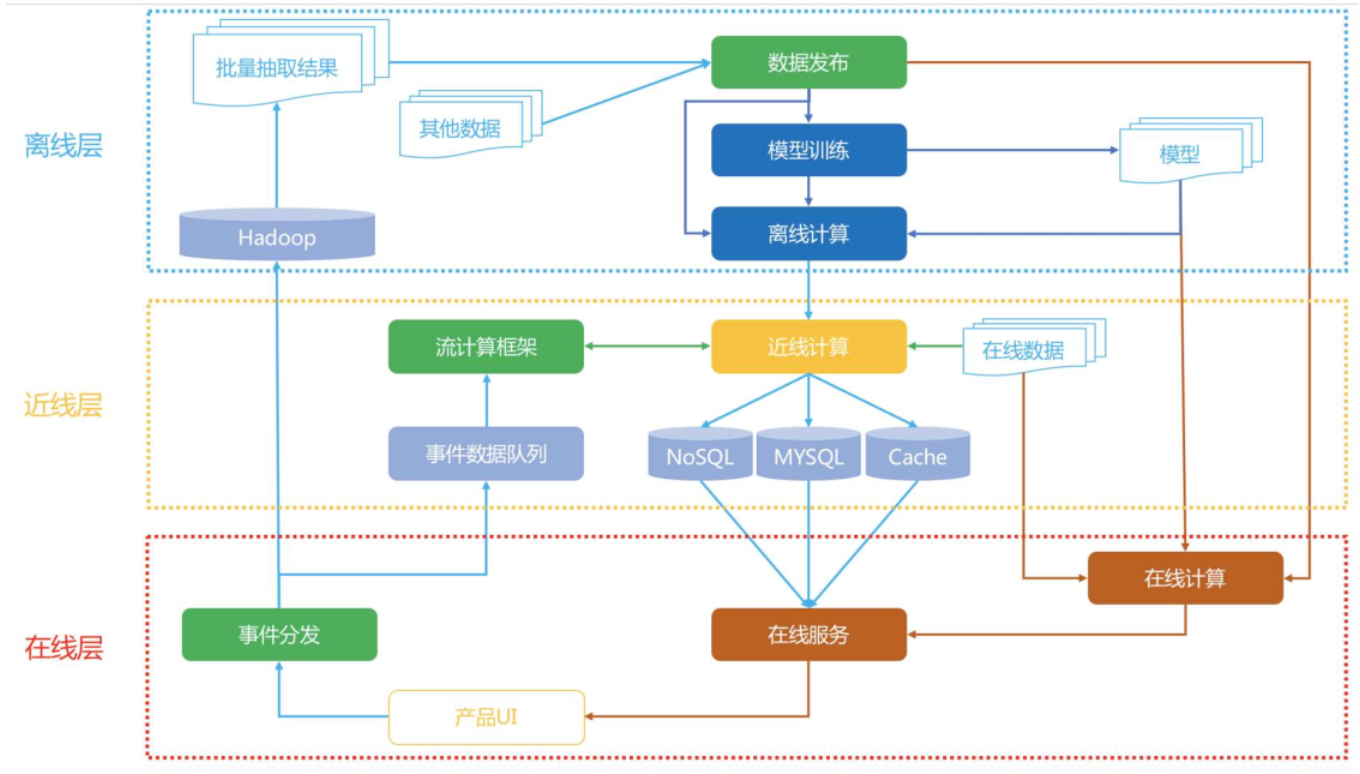
image-20250616091636181
离线层就是我们用来管理离线作业的部分架构。
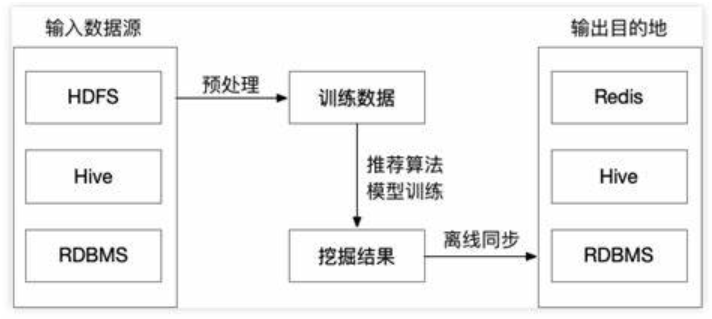
在线层能更快地响应最近的事件和用户交互,但必须实时完成。这会限制使用算法的复杂性和处理的数据量。离线计算对于数据数量和算法复杂度限制更少,因为它以批量方式完成,没有很强的时间要求。不过,由于没有及时加入最新的数据,所以很容易过时。
个性化架构的关键问题,就是如何以无缝方式结合、管理在线和离线计算过程。
近线层介于两种方法之间,可以执行类似于在线计算的方法,但又不必以实时方式完成。这种设计思想最经典的就是Netflix在2013年提出的架构,整个架构分为
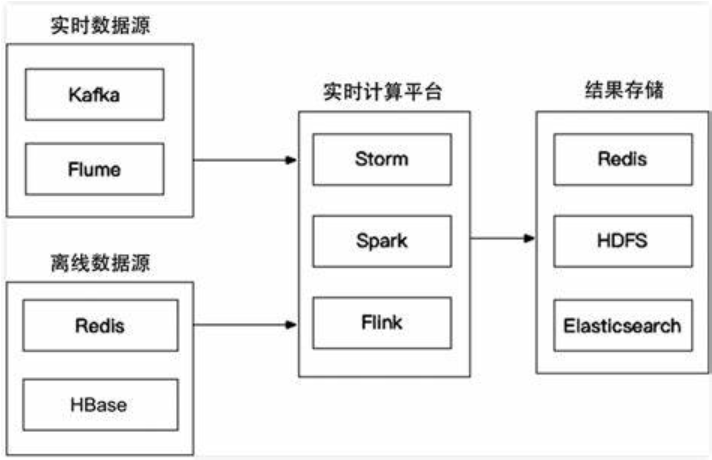
离线层:不用实时数据,不提供实时响应;
近线层:使用实时数据,不保证实时响应;
在线层:使用实时数据,保证实时在线服务;
算法架构:
是从我们比较熟悉的召回、粗排、排序、重排等算法环节角度出发的,重要的是要去理解每个环节需要完成的任务,每个环节的评价体系,以及为什么要那么设计。
我们在入门学习推荐系统的时候,更加关注的是哪个模型AUC更高、topK效果好,哪个模型更加牛逼的问题,从基本的协同过滤到点击率预估算法,从深度学习到强化学习,学术界都始终走在最前列。一个推荐算法从出现到在业界得到广泛应用是一个长期的过程,因为在实际的生产系统中,首先需要保证的是稳定、实时地向用户提供推荐服务,在这个前提下才能追求推荐系统的效果。
一个通用的算法架构,设计思想就是对数据层层建模,层层筛选,帮助用户从海量数据中找出其真正感兴趣的部分。
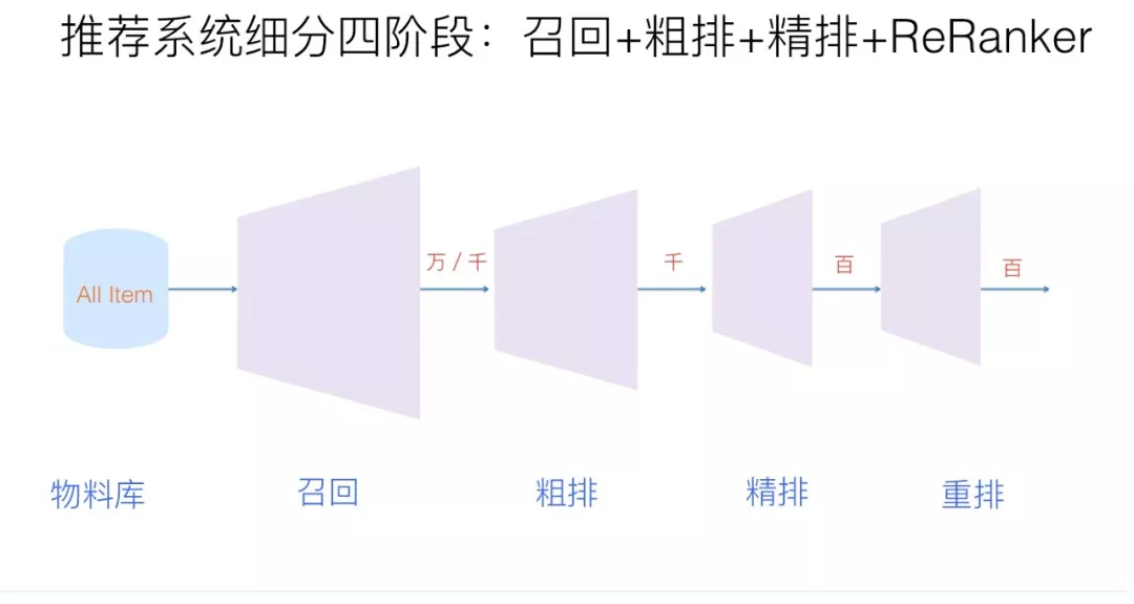
- 召回
召回层的主要目标是从推荐池中选取几千上万的item,送给后续的排序模块。由于召回面对的候选集十分大,且一般需要在线输出,故召回模块必须轻量快速低延迟。由于后续还有排序模块作为保障,召回不需要十分准确,但不可遗漏(特别是搜索系统中的召回模块)。
召回阶段我们现在主要是在保证Item质量的基础上注重覆盖率多样性,粗排阶段主要用简单的模型来解决不同路的召回和当前用户的相关性问题,最后截断到1k个以内的候选集,这个候选集符合一定的个性化相关性、视频质量和多样性的保证,然后做ranking去做复杂模型的predict。
召回主要考虑的内容有:
- 考虑用户层面:用户兴趣的多元化,用户需求与场景的多元化:例如:新闻需求,重大要闻,相关内容沉浸阅读等等
- 考虑系统层面:增强系统的鲁棒性;部分召回失效,其余召回队列兜底不会导致整个召回层失效;排序层失效,召回队列兜底不会导致整个推荐系统失效
- 系统多样性内容分发:图文、视频、小视频;精准、试探、时效一定比例;召回目标的多元化,例如:相关性,沉浸时长,时效性,特色内容等等
- 可解释性推荐一部分召回是有明确推荐理由的:很好的解决产品性数据的引入;
大白话解释: 召回:超市快速筛货小能手
想象你走进一个超大型超市想买零食,货架上可能有成千上万种商品。如果让店员一个一个挑出你可能喜欢的零食,太慢了!
召回就像超市的 “快速筛货小能手”,它的任务是先从海量商品里,快速挑出几千上万件你可能感兴趣的零食。
因为要快速给出结果,所以它的方法不会太精细,比如先把最近卖得最火的零食挑出来,或者根据你以前买过的零食类型,先选出类似的。它不需要一下子找到你最爱的那款零食,但绝对不能把你可能喜欢的漏了。要是没有召回这一步,就相当于让店员把超市里每一种零食都仔细评估一遍再推荐给你,这得等到啥时候!
召回还分好几条 “筛选路线”:有的只看大家都喜欢啥(非个性化召回),有的会参考你的购物记录(个性化召回),就像有的店员按大众喜好推荐,有的店员专门记着你的口味。而且召回还要考虑很多事,比如满足不同顾客的多样需求,保证万一某条筛选路线出问题,还有其他路线能顶上,就像超市准备好多备用方案,保证随时能给你推荐东西。- 粗排
粗排可以理解为精排前的一轮过滤机制,减轻精排模块的压力。目前粗排一般也都模型化了,其训练样本类似于精排,选取曝光点击为正样本,曝光未点击为负样本。但由于粗排一般面向上万的候选集,而精排只有几百上千,其解空间大很多。
粗排阶段的架构设计主要是考虑三个方面,一个是根据精排模型中的重要特征,来做候选集的截断,另一部分是有一些召回设计,比如热度或者语义相关的这些结果,仅考虑了item侧的特征,可以用粗排模型来排序跟当前User之间的相关性,据此来做截断,这样是比单独的按照item侧的倒排分数截断得到更加个性化的结果,最后是算法的选型要在在线服务的性能上有保证,因为这个阶段在pipeline中完成从召回到精排的截断工作,在延迟允许的范围内能处理更多的召回候选集理论上与精排效果正相关。
大白话解释:粗排:给精排减负的 “助理”
召回挑出的几千上万件零食还是太多了,店员根本来不及仔细评估每一个。这时候粗排就像精排的 “助理”,先帮着把明显不合适的零食去掉,只留下几百件更靠谱的候选。
粗排会参考精排看重的条件,比如精排很在意零食的好评率,粗排就先把差评多的零食淘汰掉;它还会结合你的喜好,比如你总买巧克力,粗排就把巧克力类零食往前放。而且粗排干活必须快,不能慢悠悠的,就像超市临时助理得快速把明显不行的零食筛掉,把 “尖子生” 留给精排。- 精排
精排层,也是我们学习推荐入门最常常接触的层,我们所熟悉的算法很大一部分都来自精排层。
这一层的任务是获取粗排模块的结果,对候选集进行打分和排序。精排需要在最大时延允许的情况下,保证打分的精准性,是整个系统中至关重要的一个模块,也是最复杂,研究最多的一个模块。
精排是推荐系统各层级中最纯粹的一层,他的目标比较单一且集中,一门心思的实现目标的调优即可。最开始的时候精排模型的常见目标是ctr,后续逐渐发展了cvr等多类目标。
精排和粗排层的基本目标是一致的,都是对商品集合进行排序,但是和粗排不同的是,精排只需要对少量的商品(即粗排输出的商品集合的topN)进行排序即可。因此,精排中可以使用比粗排更多的特征,更复杂的模型和更精细的策略(用户的特征和行为在该层的大量使用和参与也是基于这个原因)。
精排层模型是推荐系统中涵盖的研究方向最多,有非常多的子领域值得研究探索,这也是推荐系统中技术含量最高的部分,毕竟它是直接面对用户,产生的结果对用户影响最大的一层。目前精排层深度学习已经一统天下了,精排阶段采用的方案相对通用,首先一天的样本量是几十亿的级别,我们要解决的是样本规模的问题,尽量多的喂给模型去记忆,另一个方面时效性上,用户的反馈产生的时候,怎么尽快的把新的反馈给到模型里去,学到最新的知识。
精排:精挑细选的 “专家店员”
精排就像超市里最懂零食的 “专家店员”,它拿到粗排筛选后的几百件零食,会仔仔细细考虑各种因素。比如你的口味偏好、零食的价格、最近的促销活动等等,给每一件零食打个精准的分数,然后按分数高低,挑出最适合推荐给你的几十件零食。
精排是推荐里最关键、最复杂的环节,就像超市里的 “明星店员”。最开始它主要看你会不会点击(买)某个零食,后来还会考虑你会不会真的买回家(转化)。因为它处理的零食数量少,所以能用更复杂的方法、更多的信息来判断,就像专家店员有时间慢慢研究每一款零食,给出最靠谱的推荐。- 重排
常见的有三种优化目标:Point Wise、Pair Wise 和 List Wise。重排序阶段对精排生成的Top-N个物品的序列进行重新排序,生成一个Top-K个物品的序列,作为排序系统最后的结果,直接展现给用户。
重排序的原因是因为多个物品之间往往是相互影响的,而精排序是根据PointWise得分,容易造成推荐结果同质化严重,有很多冗余信息。而重排序面对的挑战就是海量状态空间如何求解的问题,一般在精排层我们使用AUC作为指标,但是在重排序更多关注NDCG等指标。
重排序在业务中,获取精排的排序结果,还会根据一些策略、运营规则参与排序,比如强制去重、间隔排序、流量扶持等、运营策略、多样性、context上下文等,重新进行一个微调。重排序更多的是List Wise作为优化目标的,它关注的是列表中商品顺序的问题来优化模型,但是一般List Wise因为状态空间大,存在训练速度慢的问题。
由于精排模型一般比较复杂,基于系统时延考虑,一般采用point-wise方式,并行对每个item进行打分。这就使得打分时缺少了上下文感知能力。用户最终是否会点击购买一个商品,除了和它自身有关外,和它周围其他的item也息息相关。重排一般比较轻量,可以加入上下文感知能力,提升推荐整体算法效率。比如三八节对美妆类目商品提权,类目打散、同图打散、同卖家打散等保证用户体验措施。重排中规则比较多,但目前也有不少基于模型来提升重排效果的方案。
重排:调整推荐顺序的 “整理师”
精排选出来的零食顺序,有时候还得再调整一下。重排就像 “整理师”,它会重新梳理精排给出的零食推荐顺序。
精排打分的时候,可能只考虑了单个零食的情况,没考虑这些零食放在一起合不合适,就像店员只单独评价每款零食好不好,没考虑把它们放在一个篮子里你会不会觉得重复。
重排会考虑零食之间的影响,比如避免推荐太多同类型的零食,还会根据一些特殊规则调整,比如三八节给女性喜欢的零食加分,就像超市在节日给特定商品搞促销。重排既要让推荐的零食顺序更合理,又要解决 “选择太多不好挑” 的难题,就像整理师得把篮子里的零食摆得又好看又好选。- 混排
多个业务线都想在Feeds流中获取曝光,则需要对它们的结果进行混排。比如推荐流中插入广告、视频流中插入图文和banner等。可以基于规则策略(如广告定坑)和强化学习来实现。
混排:协调各方推荐的 “调度员”
超市里可能有不同部门都想推荐东西,比如零食区想推新口味薯片,日用品区想推打折纸巾,广告部门想推合作品牌。混排就像 “调度员”,负责把这些不同的推荐结果合理安排在一起。
它会按照一些规则或者智能算法,决定哪些推荐该放在前面,哪些该穿插在中间。比如规定广告必须放在第 3 个位置,或者根据你平时的购买习惯,智能调整不同推荐的顺序,就像调度员合理安排超市里不同区域的促销展示,让你逛得舒服,又能看到各种推荐。- 总结
整篇文章从系统架构梳理了Netfliex的经典推荐系统架构,整个架构更多是偏向实时性能和效果之间tradeoff的结果。如果从另外的角度看推荐系统架构,比如从数据流向,或者说从推荐系统各个时序依赖来看,就是我们最熟悉的召回、粗排、精排、重排、混排等模块了。这种角度来看是把推荐系统从前往后串起来,其中每一个模块既有在离线层工作的,也有在在线层工作的。而从数据驱动角度看,更能够看到推荐系统的完整技术栈,推荐系统当前面临的局限和发展方向。
召回、排序这些里面单拿出任何一个模块都非常复杂。这也是为什么大家都说大厂拧螺丝的原因,因为很可能某个人只会负责其中很小的一个模块。许多人说起自己的模块来如数家珍,但对于全局缺乏认识,带来的结果是当你某天跳槽了或者是工作内容变化了,之前从工作当中的学习积累很难沉淀下来,这对于程序员的成长来说是很不利的。
所以希望这篇文章能够帮助大家在负责某一个模块,优化某一个功能的时候,除了能够有算法和数据,还能能够考虑对整个架构带来的影响,如何提升整体的一个性能,慢慢开阔自己的眼界,构建出一个更好的推荐系统。
1.3 推荐系统的技术栈
推荐系统是一个非常大的框架,有非常多的模块在里面,完整的一套推荐系统体系里,不仅会涉及到推荐算法工程师、后台开发工程师、数据挖掘/分析工程师、NLP/CV工程师还有前端、客户端甚至产品、运营等支持。
我们作为算法工程师,需要掌握的技术栈主要就是在算法和工程两个区域了,所以这篇文章将会分别从算法和工程两个角度出发,结合两者分析当前主流的一些推荐算法技术栈。
1. 算法
首先我们从推荐系统架构出发,一种分法是将整个推荐系统架构分为召回、粗排、精排、重排、混排等模块。它的分解方法是从一份数据如何从生产出来,到线上服务完整顺序的一个流程。因为在不同环节,我们一般会考虑不同的算法,所以这种角度出发我们来研究推荐系统主流的算法技术栈。
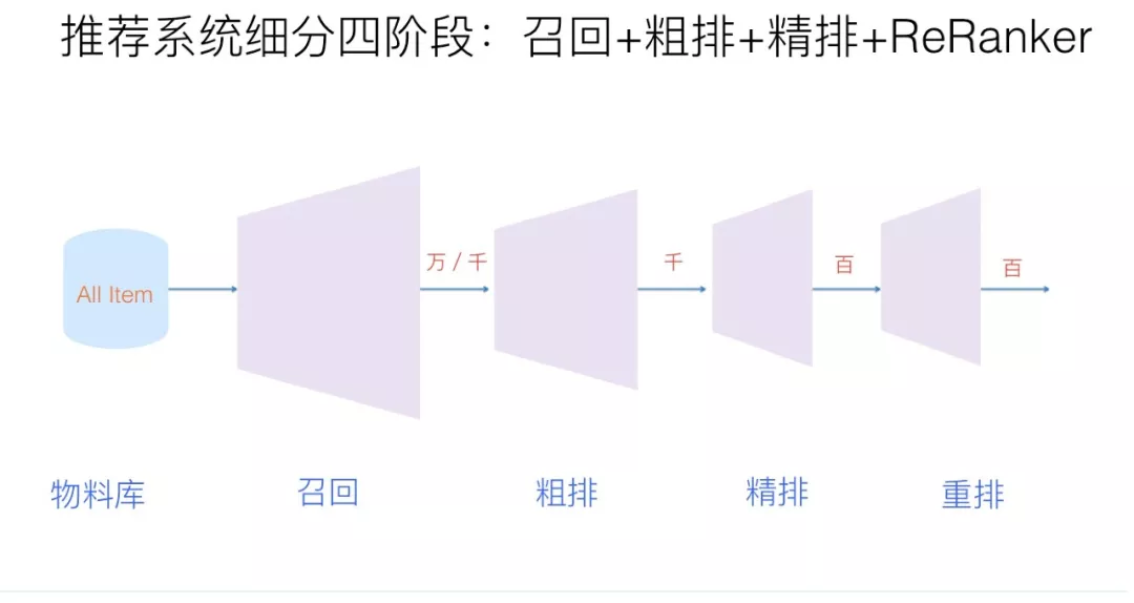
为了帮助新手在后文方便理解,首先简单介绍这些模块的功能主要是:
- 召回:从推荐池中选取几千上万的item,送给后续的排序模块。由于召回面对的候选集十分大,且一般需要在线输出,故召回模块必须轻量快速低延迟。由于后续还有排序模块作为保障,召回不需要十分准确,但不可遗漏(特别是搜索系统中的召回模块)。目前基本上采用多路召回解决范式,分为非个性化召回和个性化召回。个性化召回又有content-based、behavior-based、feature-based等多种方式。
- 粗排:粗拍的原因是有时候召回的结果还是太多,精排层速度还是跟不上,所以加入粗排。粗排可以理解为精排前的一轮过滤机制,减轻精排模块的压力。粗排介于召回和精排之间,要同时兼顾精准性和低延迟。一般模型也不能过于复杂
- 精排:获取粗排模块的结果,对候选集进行打分和排序。精排需要在最大时延允许的情况下,保证打分的精准性,是整个系统中至关重要的一个模块,也是最复杂,研究最多的一个模块。精排系统构建一般需要涉及样本、特征、模型三部分。
- 重排:获取精排的排序结果,基于运营策略、多样性、context上下文等,重新进行一个微调。比如三八节对美妆类目商品提权,类目打散、同图打散、同卖家打散等保证用户体验措施。重排中规则比较多,但目前也有不少基于模型来提升重排效果的方案。
- 混排:多个业务线都想在Feeds流中获取曝光,则需要对它们的结果进行混排。比如推荐流中插入广告、视频流中插入图文和banner等。可以基于规则策略(如广告定坑)和强化学习来实现。
1.1. 画像层
下面我贴了一个微信看一看的内容画像框架,然后我们来介绍下在这一块主要使用的算法技术。
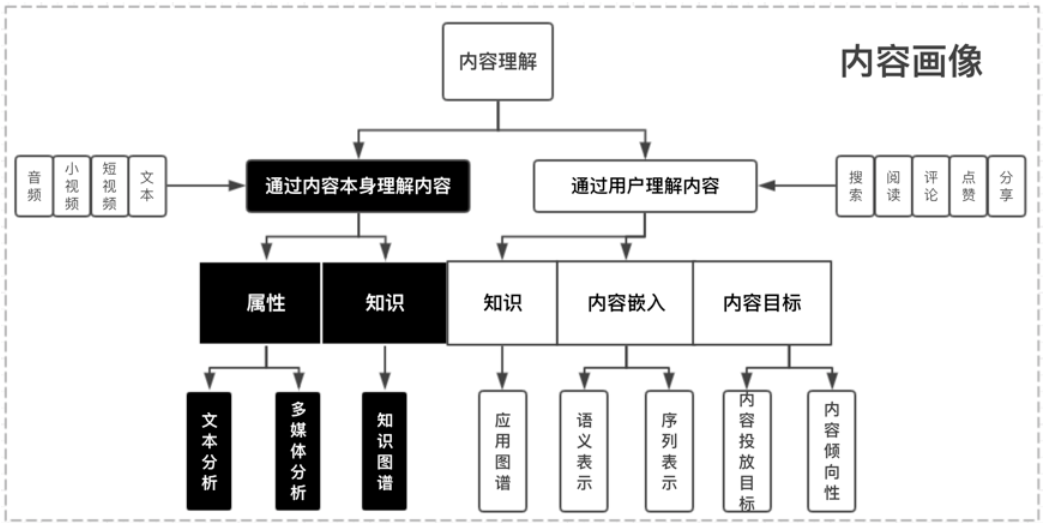
一般推荐系统会加入多模态的一个内容理解。我们用短视频形式举个例子,假设用户拍摄了一条短视频,上传到了平台,从推荐角度看,首先我们有的信息是这条短视频的作者、长度、作者为它选择的标签、时间戳这些信息。但是这对于推荐来说是远远不够的,首先作者打上的标签不一定准确反映作品,原因可能是我们模型的语义空间可能和作者/现实世界不一致。其次我们需要更多维度的特征,比如有些用户喜欢看小姐姐跳舞,那我希望能够判断一条视频中是否有小姐姐,这就涉及到封面图的基于CV的内容抽取或者整个视频的抽取;再比如作品的标题一般能够反映主题信息,除了很多平台常用的用“#”加上一个标签以外,我们也希望能够通过标题抽取出基于NLP的信息。还有更多的维度可以考虑:封面图多维度的多媒体特征体系,包括人脸识别,人脸embedding,标签,一二级分类,视频embedding表示,水印,OCR识别,清晰度,低俗色情,敏感信息等多种维度。
这里面涉及的任务主要是CV的目标检测、语义分割等任务,NLP中的情感分析、摘要抽取、自然语言理解等任务。但是这部分算法一般团队都会有专门负责的组,不需要推荐算法工程师来负责,他们会有多模态的语意标签输出,主要形式是各种粒度的Embedding。我们只需要在我们的推荐模型中引入这些预训练的Embedding。
1.1.1 文本理解
这应该是用的最多的模态信息,包括item的标题、正文、OCR、评论等数据。这里面也可以产生不同粒度的信息,比如文本分类,把整个item做一个粗粒度的分类。
这里的典型算法有:RNN、TextCNN、FastText、Bert等;
1.1.2 关键词标签
相比文本分类,关键词是更细粒度的信息,往往是一个mutil-hot的形式,它会对item在我们的标签库的选取最合适的关键词或者标签。
这里典型的算法有:TF-IDF、Bert、LSTM-CRF等。
1.1.3 内容理解
在很多场景下,推荐的主题都是视频或者图片,远远多于仅推荐文本的情况,这里视频/图片item中的内容中除了文本的内容以外,更多的信息其实来源于视频/图片内容本身, 因此需要尝试从多种模态中抽取更丰富的信息。主要包括分类信息、封面图OCR的信息、视频标签信息等
这里典型的算法有:TSN、RetinaFace、PSENet等。
1.1.4 知识图谱
知识图谱作为知识承载系统,用于对接内外部关键词信息与词关系信息;内容画像会将原关系信息整合,并构建可业务应用的关系知识体系,其次,依赖业务中积累用户行为产生的实体关系数据,本身用户需求的标签信息,一并用于构建业务知识的兴趣图谱,基于同构网络与异构网络表示学习等核心模型,输出知识表示与表达,抽象后的图谱用于文本识别,推荐语义理解,兴趣拓展推理等场景,直接用于兴趣推理的冷启场景已经验证有很不错的收益。
这方面的算法有:KGAT、RippleNet等。
1.2 召回/粗排
推荐系统的召回阶段可以理解为根据用户的历史行为数据,为用户在海量的信息中粗选一批待推荐的内容,挑选出一个小的候选集的过程。粗排用到的很多技术与召回重合,所以放在一起讲,粗排也不是必需的环节,它的功能对召回的结果进行个粗略的排序,在保证一定精准的前提下,进一步减少往后传送的物品数量,这就是粗排的作用。
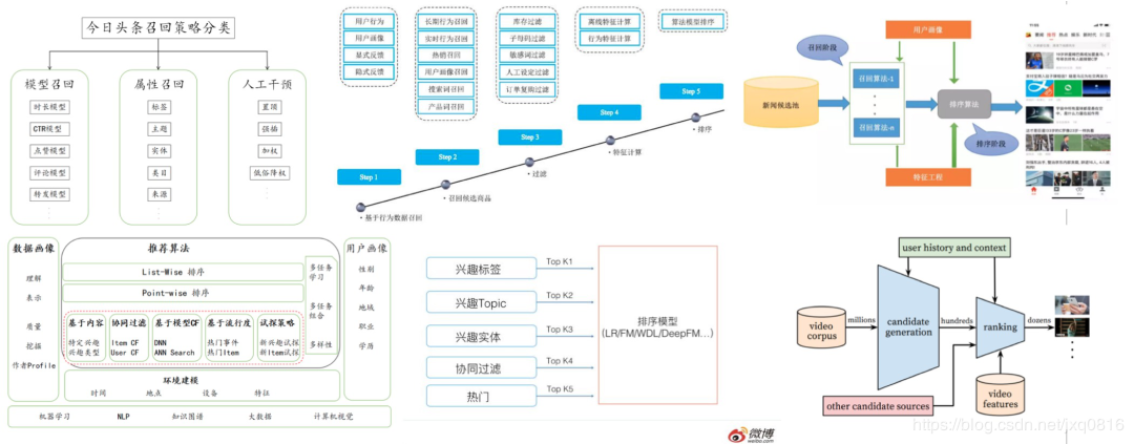
召回模块面对几百上千万的推荐池物料规模,候选集十分庞大。由于后续有排序模块作为保障,故不需要十分准确,但必须保证不要遗漏和低延迟。目前主要通过多路召回来实现,一方面各路可以并行计算,另一方面取长补短。可以看到各类同类竞品的系统虽然细节上多少存在差异,但不约而同的采取了多路召回的架构,这类设计考虑如下几点问题:
- 考虑用户层面:用户兴趣的多元化,用户需求与场景的多元化:例如:新闻需求,重大要闻,相关内容沉浸阅读等等
- 考虑系统层面:增强系统的鲁棒性;部分召回失效,其余召回队列兜底不会导致整个召回层失效;排序层失效,召回队列兜底不会导致整个推荐系统失效
- 系统多样性内容分发:图文、视频、小视频;精准、试探、时效一定比例;召回目标的多元化,例如:相关性,沉浸时长,时效性,特色内容等等
- 可解释性推荐一部分召回是有明确推荐理由的:很好的解决产品性数据的引入;
介绍了召回任务的目的和场景后,接下来分析召回层面主要的技术栈,因为召回一般都是多路召回,从模型角度分析有很多召回算法,这种一般是在召回层占大部分比例点召回,除此之外,还会有探索类召回、策略运营类召回、社交类召回等。接下来我们着重介绍模型类召回。
1.2.1经典模型召回
随着技术发展,在Embedding基础上的模型化召回是一个技术发展潮流方向。这种召回的范式是通过某种算法,对user和item分别打上Embedding,然后user与item在线进行KNN计算实时查询最近领结果作为召回结果,快速找出匹配的物品。需要注意的是如果召回采用模型召回方法,优化目标最好和排序的优化目标一致,否则可能被过滤掉。
在这方面典型的算法有:FM、双塔DSSM、Multi-View DNN等。
1.2.2 序列模型召回
推荐系统主要解决的是基于用户的隐式阅读行为来做个性化推荐的问题,序列模型一些基于神经网络模型学习得到Word2Vec模型,再后面的基于RNN的语言模型,最先用的最多的Bert,这些方法都可以应用到召回的学习中。
用户在使用 APP 或者网站的时候,一般会产生一些针对物品的行为,比如点击一些感兴趣的物品,收藏或者互动行为,或者是购买商品等。而一般用户之所以会对物品发生行为,往往意味着这些物品是符合用户兴趣的,而不同类型的行为,可能代表了不同程度的兴趣。比如购买就是比点击更能表征用户兴趣的行为。在召回阶段,如何根据用户行为序列打 embedding,可以采取有监督的模型,比如 Next Item Prediction 的预测方式即可;也可以采用无监督的方式,比如物品只要能打出 embedding,就能无监督集成用户行为序列内容,例如 Sum Pooling。
这方面典型的算法有:CBOW、Skip-Gram、GRU、Bert等。
1.2.3 用户序列拆分
上文讲了利用用户行为物品序列,打出用户兴趣 Embedding 的做法。但是,另外一个现实是:用户往往是多兴趣的,比如可能同时对娱乐、体育、收藏感兴趣。这些不同的兴趣也能从用户行为序列的物品构成上看出来,比如行为序列中大部分是娱乐类,一部分体育类,少部分收藏类等。那么能否把用户行为序列物品中,这种不同类型的用户兴趣细分,而不是都笼统地打到一个用户兴趣 Embedding 里呢?用户多兴趣拆分就是解决这类更细致刻画用户兴趣的方向。
本质上,把用户行为序列打到多个 embedding 上,实际它是个类似聚类的过程,就是把不同的 Item,聚类到不同的兴趣类别里去。目前常用的拆分用户兴趣 embedding 的方法,主要是胶囊网络和 Memory Network,但是理论上,很多类似聚类的方法应该都是有效的,所以完全可以在这块替换成你自己的能产生聚类效果的方法来做。
这方面典型的算法有:Multi-Interest Network with Dynamic Routing for Recommendation at Tmall等。
1.2.4 知识图谱
知识图谱有一个独有的优势和价值,那就是对于推荐结果的可解释性;比如推荐给用户某个物品,可以在知识图谱里通过物品的关键关联路径给出合理解释,这对于推荐结果的解释性来说是很好的,因为知识图谱说到底是人编码出来让自己容易理解的一套知识体系,所以人非常容易理解其间的关系。知识图谱的可解释性往往是和图路径方法关联在一起的,而 Path 类方法,很多实验证明了,在排序角度来看,是效果最差的一类方法,但是它在可解释性方面有很好的效果,所以往往可以利用知识图谱构建一条可解释性的召回通路。
这方面的算法有:KGAT、RippleNet等。
1.2.5 图模型
推荐系统中User和Item相关的行为、需求、属性和社交信息具有天然的图结构,可以使用一张复杂的异构图来表示整个推荐系统。图神经网络模型推荐就是基于这个想法,把异构网络中包含的结构和语义信息编码到结点Embedding表示中,并使用得到向量进行个性化推荐。知识图谱其实是图神经网络的一个比较特殊的具体实例,但是,知识图谱因为编码的是静态知识,而不是用户比较直接的行为数据,和具体应用距离比较远,这可能是导致两者在推荐领域表现有差异的主要原因。
这方面典型的算法有:GraphSAGE、PinSage等。
1.3 精排
排序模型是推荐系统中涵盖的研究方向最多,有非常多的子领域值得研究探索,这也是推荐系统中技术含量最高的部分,毕竟它是直接面对用户,产生的结果对用户影响最大的一层。目前精排层深度学习已经一统天下了,这是王喆老师《深度学习推荐算法》书中的精排层模型演化线路。具体来看分为DNN、Wide&Deep两大块,实际深入还有序列建模,以及没有提到的多任务建模都是工业界非常常用的,所以我们接下来具体谈论其中每一块的技术栈。
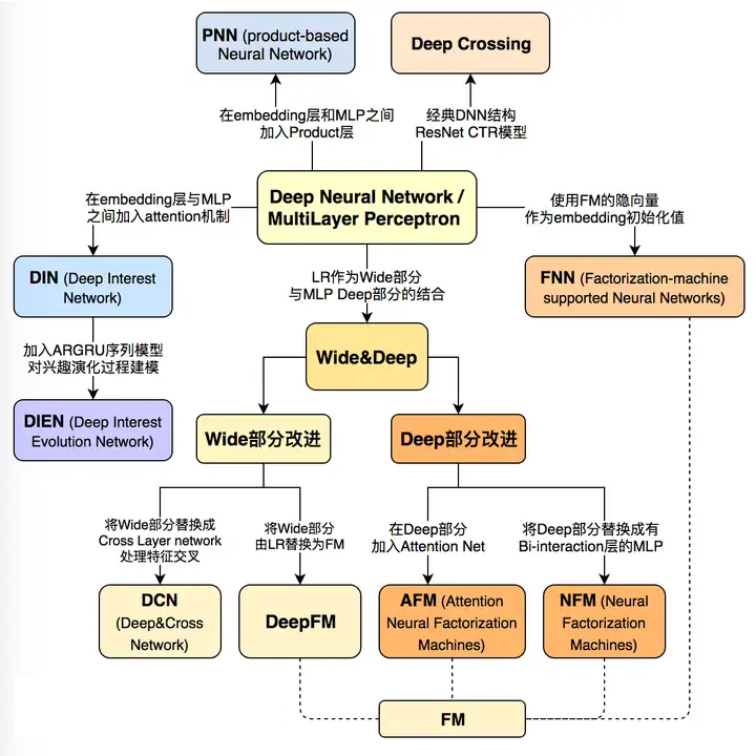
1.3.1 特征交叉模型
在深度学习推荐算法发展早期,很多论文聚焦于如何提升模型的特征组合和交叉的能力,这其中既包含隐式特征交叉Deep Crossing也有采用显式特征交叉的探究。本质上是希望模型能够摆脱人工先验的特征工程,实现端到端的一套模型。
在早期的推荐系统中,基本是由人工进行特征交叉的,往往凭借对业务的理解和经验,但是费时费力。于是有了很多的这方面的研究,从FM到GBDT+LR都是引入模型进行自动化的特征交叉。再往后就是深度模型,深度模型虽然有万能近似定理,但是真正想要发挥模型的潜力,显式的特征交叉还是必不可少的。
这方面的经典研究工作有:DCN、DeepFM、xDeepFM等;
1.3.2 序列模型
在推荐系统中,历史行为序列是非常重要的特征。在序列建模中,主要任务目标是得到用户此刻的兴趣向量(user interest vector)。如何刻画用户兴趣的广泛性,是推荐系统比较大的一个难点,用户历史行为序列建模的研究经历了从Pooling、RNN到attention、capsule再到transformer的顺序。在序列模型中,又有很多细分的方向,比如根据用户行为长度有研究用户终身行为序列的,也有聚焦当下兴趣的,还有研究如何抽取序列特征的抽取器,比如研究attention还是胶囊网络。
这方面典型的研究工作有:DIN、DSIN、DIEN、SIM等;
1.3.3 多模态信息融合
在上文我们提到算法团队往往会利用内容画像信息,既有基于CV也有基于NLP抽取出来的信息。这是非常合理的,我们在逛抖音、淘宝的时候关注的不仅仅item的价格、品牌,同样会关注封面小姐姐好不好看、标题够不够震惊等信息。除此之外,在冷启动场景下,我们能够利用等信息不够多,如果能够使用多模态信息,能很大程度上解决数据稀疏的问题。
传统做法在多模态信息融合就是希望把不同模态信息利用起来,通过Embedding技术融合进模型。在推荐领域,主流的做法还是一套非端到端的体系,由其他模型抽取出多模态信息,推荐只需要融合入这些信息就好了。同时也有其他工作是利用注意力机制等方法来学习不同模态之间的关联,来增强多模态的表示。
比较典型的工作有:Image Matters: Visually modeling user behaviors using Advanced Model Server、UMPR等。
1.3.4 多任务学习
很多场景下我们模型优化的目标都是CTR,有一些场景只考虑CTR是不够的,点击率模型、时长模型和完播率模型是大部分信息流产品推荐算法团队都会尝试去做的模型。单独优化点击率模型容易推出来标题党,单独优化时长模型可能推出来的都是长视频或长文章,单独优化完播率模型可能短视频短图文就容易被推出来,所以多目标就应运而生。信息流推荐中,我们不仅希望用户点进我们的item,还希望能有一个不错的完播率,即希望用户能看完我们推荐的商品。或者电商场景希望用户不仅点进来,还希望他买下或者加入购物车了。这些概率实际上就是模型要学习的目标,多种目标综合起来,包括阅读、点赞、收藏、分享等等一系列的行为,归纳到一个模型里面进行学习,这就是推荐系统的多目标学习。
这方面比较典型的算法有:ESSM、MMoE、DUPN等。
1.3.5 强化学习
强化学习与一般有监督的深度学习相比有一些很显著的优势,首先强化学习能够比较灵活的定义优化的业务目标,考虑推荐系统长短期的收益,比如用户留存,在深度模型下,我们很难设计这个指标的优化函数,而强化学习是可以对长期收益下来建模。第二是能够体现用户兴趣的动态变化,比如在新闻推荐下,用户兴趣变化很快,强化学习更容易通过用户行为动态产生推荐结果。最后是EE也就是利用探索机制,这种一种当前和长期收益的权衡,强化学习能够更好的调节这里的回报。
这方面比较典型的算法有:DQN、Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology;
1.3.6 跨域推荐
一般一家公司业务线都是非常多的,比如腾讯既有腾讯视频,也有微信看一看、视频号,还有腾讯音乐,如果能够结合这几个场景的数据,同时进行推荐,一方面对于冷启动是非常有利的,另一方面也能补充更多数据,更好的进行精确推荐。
跨域推荐系统相比一般的推荐系统要更加复杂。在传统推荐系统中,我们只需要考虑建立当前领域内的一个推荐模型进行分析;而在跨域推荐中,我们更要关心在不同领域间要选择何种信息进行迁移,以及如何迁移这些信息,这是跨域推荐系统中非常关键的问题。
这方面典型的模型有:DTCDR、MV-DNN、EMCDR等;
1.4 重排序
我们知道常见的有三种优化目标:Point Wise、Pair Wise 和 List Wise。重排序阶段对精排生成的Top-N个物品的序列进行重新排序,生成一个Top-K个物品的序列,作为排序系统最后的结果,直接展现给用户。重排序的原因是因为多个物品之间往往是相互影响的,而精排序是根据PointWise得分,容易造成推荐结果同质化严重,有很多冗余信息。而重排序面对的挑战就是海量状态空间如何求解的问题,一般在精排层我们使用AUC作为指标,但是在重排序更多关注NDCG等指标。
重排序在业务中,还会根据一些策略、运营规则参与排序,比如强制去重、间隔排序、流量扶持等,但是总计趋势上看还是算法排序越来越占据主流趋势。重排序更多的是List Wise作为优化目标的,它关注的是列表中商品顺序的问题来优化模型,但是一般List Wise因为状态空间大,存在训练速度慢的问题。这方面典型的做法,基于RNN、Transformer、强化学习的都有,这方面因为不是推荐的一个核心,所以没有展开来讲,而且这一块比较依赖实际的业务场景。
这里的经典算法有:MRR、DPP、RNN等;
2 工程
推荐系统的实现需要依托工程,很多研究界Paper的idea满天飞,却忽视了工业界能否落地,进入工业界我们很难或者很少有组是做纯research的,所以我们同样有很多工程技术需要掌握。下面列举了在推荐中主要用到的工程技术:
- 编程语言:Python、Java(scala)、C++、sql、shell;
- 机器学习:Tensorflow/Pytorch、GraphLab/GraphCHI、LGB/Xgboost、SKLearn;
- 数据分析:Pandas、Numpy、Seaborn、Spark;
- 数据存储:mysql、redis、mangodb、hive、kafka、es、hbase;
- 相似计算:annoy、faiss、kgraph
- 流计算:Spark Streaming、Flink
- 分布式:Hadoop、Spark
上面那么多技术,我内容最重要的就是加粗的三部分,
第一是语言:必须掌握的是Python,C++和JAVA中根据不同的组使用的是不同的语言,这个如果没有时间可以等进组后慢慢学习。
然后是机器学习框架:Tensorflow和Pytorch至少要掌握一个吧,前期不用纠结学哪个,这个迁移成本很低,基本能够达到触类旁通,而且面试官不会为难你只会这个不会那个。
最后是数据分析工具:Pandas是我们处理单机规模数据的利器,但是进入工业界,Hadoop和Spark是需要会用的,不过不用学太深,会用即可。
3 总结
本文从算法和工程两个角度分析了推荐系统的一个技术栈,但是还有很多方向遗漏,也有很多方向受限于现在的技术水平深度不够和有错误的情况,后续会不断补充和更正。
所以技术栈我列出的是一个非常广度的技术,实际上每一个技术钻研下去都需要非常多时间,而且不一定是你实际工作中会遇到的,所以不要被那么多技术吓到,也要避免陷入技术细节的海洋中。
我和非常多的大厂面试官讨论过技术深度和广度的问题,得出来的结论是对于入门的推荐算法工程师而言,实际上深度和广度的要求取决于你要去的组,有些组有很深的推荐技术沉淀,有很强的工程师团队,这样的组就会希望候选者能够在某个方面有比较深入的研究,这个方面既包含工程方面也包含研究方面。但是如果是比较新的组、或者技术沉淀不深、推荐不是主要任务的组,对深度要求就不会很高。总而言之,我认为对于应届生/实习生来说,在推荐最重要的工程技术/研究方向,至少在召回和排序模块,需要选一个作为方向,是需要较深钻研。对于其他技术/研究方向需要有一定了解,比如可以没用过强化学习,但是要知道强化学习能够在推荐中解决什么问题,剩下的可以等到真实遇到需要后再去学习。
参考资料
- 万字入门推荐系统
- 张俊林:技术演进趋势:召回->排序->重排
- 微信"看一看"多模型内容策略与召回
- 多目标学习在推荐系统中的应用
- 强化学习在美团“猜你喜欢”的实践
- 推荐系统技术演进趋势:重排篇
- 阿里强化学习重排实践
第二章 推荐系统算法基础
0.0 Task2 总结
推荐系统算法分为:经典召回模型和经典排序模型
一、 经典召回模型中有:
基于协同过滤的召回下面进行说明,因为太多的原理部分,这里用大白话便于理解,关注于应用层面:
UserCF是 “人以群分” 的推荐:找到和你品味相似的用户,看看他们喜欢什么(但你没看过/买过),就把这些东西推荐给你。
ItemCF是:算物品之间的 “相似程度”,再给用户推荐和他们喜欢的物品相似的其他物品。
什么时候用 ItemCF?和 UserCF 怎么选?
场景 适合用 ItemCF 适合用 UserCF 用户和物品数量 物品少,用户多(比如音乐、电影推荐) 用户少,物品多(比如新闻推荐) 用户兴趣特点 兴趣稳定、持久(比如长期喜欢古典音乐) 兴趣变化快、时效性强(比如新闻、热点) 推荐特点 更个性化,贴近用户已有兴趣 更社交化,适合发现热点、新信息 例子 推荐艺术品、音乐、电影 新闻 APP、社交媒体热点内容推荐 Swing(Graph-based):
Swing 算法专门找 “替代品”,比如不同款式的衬衫。它的逻辑很像 “物以类聚,人以群分”,但反过来:两件物品如果被很多 “兴趣不同” 的用户同时购买,说明它们很可能是替代品。
Surprise负责找 “互补品”,比如衬衫和裤子,通过类别、购买顺序、时间间隔和聚类来挖掘关联。
矩阵分解
协同过滤的召回,当遇到 “稀疏矩阵” 就傻眼 —— 比如大部分用户没给物品打分,或者新用户 / 新物品数据太少,推荐不准。把稀疏的用户 - 物品评分矩阵,分解成两个更稠密的 “隐向量矩阵”:
用户矩阵:记录每个用户对不同 “隐藏特征” 的偏好程度(比如用户多喜欢 “小清新”“重口味”)。
物品矩阵:记录每个物品包含的 “隐藏特征” 的程度(比如歌曲多符合 “小清新”“重口味”)。
作用:用这两个矩阵的乘积还原评分矩阵,预测用户没打分的物品,解决稀疏问题。
二、对于应用场景:
| 方法 | 适用场景核心特征 | 典型业务场景举例 | 什么时候优先选? | 什么时候组合用? |
|---|---|---|---|---|
| UserCF | 想借 “同类人喜好” 推荐,用户行为差异大、更新快 | 新闻 APP、社交平台内容推荐 | 1. 新用户多(依赖 “群体行为” 补全画像) 2. 内容更新极快(新闻 / 短视频) | 和 ItemCF 组合,覆盖 “人找物 + 物找物” |
| ItemCF | 想借 “物品关联” 推荐,物品标签明确、用户行为稳定 | 电商商品推荐、音乐 / 影视推荐 | 1. 物品属性强(手机壳→手机膜) 2. 用户行为稳定(买手机后推配件) | 和 Swing 组合,提升 “相似物品” 精准度 |
| Swing | 想精准找 “物品替代关系”,需过滤 “活跃用户干扰” | 电商 “同类商品” 推荐、长尾商品推荐 | 1. 有大量 “乱买用户”(比如促销时疯狂囤货的用户) 2. 需区分 “替代 vs 互补”(衬衫→不同衬衫,而非领带) | 和 ItemCF 互补,Swing 负责 “精准替代” |
| 矩阵分解 | 想挖掘 “隐藏兴趣”,用户 / 物品行为稀疏、需冷启动 | 小众商品推荐、新用户 / 新品冷启动 | 1. 数据稀疏(用户只买过 1-2 件商品) 2. 需突破 “显性行为” 推荐(比如用户没买过,但潜在喜欢) | 和 UserCF/ItemCF 组合,补全 “隐藏特征” |
三、真实场景例子(看怎么用)
1. 新闻 APP 推荐(UserCF 主场)
- 场景:用户每天刷不同新闻,内容更新极快(每小时上新),新用户多。
- 逻辑:用 UserCF 找 “相似用户”(比如都爱看科技 + 体育新闻的人),直接抄他们刚看的新闻。
- 为啥不用其他:ItemCF 难追热点(新闻标签更新慢);Swing 对 “快速更新内容” 没必要;矩阵分解冷启动慢(新用户 / 新闻特征难挖掘)。
2. 电商 “手机配件” 推荐(ItemCF 主场)
场景:用户买了手机,想推手机壳、膜、充电宝(物品关联强,行为稳定)。
逻辑:ItemCF 算 “手机” 和其他物品的相似度,直接推关联商品。
组合玩法:如果商品多、用户乱买(比如大促时用户囤货),
ItemCF + Swing:
- ItemCF 先筛出 “手机相关” 商品(壳 / 膜 / 充电宝)
- Swing 再过滤 “乱买用户” 干扰,精准推 “真正替代 / 互补” 的(比如别因为有人乱买就推无关商品)
3. 小众设计师品牌推荐(矩阵分解主场)
场景:用户买过 1-2 件小众衣服,行为稀疏;需推 “潜在喜欢” 的设计师款(没显性行为关联)。
逻辑:矩阵分解挖掘 “隐藏特征”(比如用户喜欢 “复古 + 亚麻材质”,物品也有这些潜在标签),直接推匹配的。
组合玩法:
矩阵分解 + UserCF:
- 矩阵分解补 “隐藏兴趣”(推复古亚麻裙)
- UserCF 补 “同类人实时喜好”(推其他用户刚买的同款风格新品)
4. 大促期间 “同类商品” 推荐(Swing 主场)
- 场景:大促时用户疯狂囤货(比如买了 10 件衣服,行为噪声大),需精准推 “替代款衬衫”。
- 逻辑:Swing 过滤 “乱买用户”,只看 “兴趣差异大但都买了同款衬衫” 的用户,算物品相似度。
- 对比 ItemCF:ItemCF 可能因为 “乱买用户” 把衬衫和无关商品(比如袜子)关联,Swing 能避开这种噪声。
四、总结(一句话选方法)
- 想抄 “同类人作业”→ UserCF(新闻 / 社交)
- 想抄 “同类物品作业”→ ItemCF(电商配件 / 音乐)
- 想精准抄 “同类物品作业,还得过滤捣乱的”→ Swing(大促商品 / 长尾替代)
- 想抄 “用户自己都没发现的作业”→ 矩阵分解(小众商品 / 冷启动)
组合用的核心逻辑:用不同方法覆盖 “显性行为 + 隐性特征 + 噪声过滤”,比如:
- 电商首页推荐 = ItemCF(显性关联) + Swing(精准替代) + 矩阵分解(潜在兴趣)
- 新闻推荐 = UserCF(实时同类人) + 矩阵分解(隐藏兴趣)
文章正文如下,需要反复理解阅读:
2.1 经典召回模型
2.1.1 基于协同过滤的召回
1. UserCF(基于用户的协同过滤)
核心就是 “人以群分” 这个道理在推荐系统里的应用。
核心思想一句话总结:
找到和你品味相似的用户,看看他们喜欢什么(但你没看过/买过),就把这些东西推荐给你。
就像你发现几个朋友和你喜欢的电影、音乐高度一致,当他们发现一部新好片时,你大概率也会感兴趣。
- 核心: 利用“品味相似的用户喜欢的东西也相似”这个规律做推荐。
- 关键步骤:
- 算谁像你: 基于历史行为(评分等),找到和目标用户最相似的Top N个用户(邻居)。
- 猜你喜欢啥: 预测目标用户对未接触物品的评分 = 邻居们对该物品评分的加权平均(权重是邻居与你的相似度)。
- 推荐高分货: 把预测评分最高的Top K个未接触物品推荐给目标用户。
适用场景: 用户数量不是特别巨大(避免计算瓶颈),且希望推荐结果能带来一些意外惊喜(发现小众兴趣)的场景。当用户数爆炸时,ItemCF通常是更主流的选择。实际应用中,两者常结合使用。
相似性度量方法
杰卡德(Jaccard)相似系数:由于杰卡德相似系数一般无法反映具体用户的评分喜好信息,所以常用来评估用户是否会对某物品进行打分, 而不是预估用户会对某物品打多少分。
余弦相似度:余弦相似度衡量了两个向量的夹角,夹角越小越相似。
皮尔逊相关系数:在用户之间的余弦相似度计算时,将用户向量的内积展开为各元素乘积和,相较于余弦相似度,皮尔逊相关系数通过使用用户的平均分对各独立评分进行修正,减小了用户评分偏置的影响。
适用场景
JaccardJaccar**d 相似度表示两个集合的交集元素个数在并集中所占的比例 ,所以适用于隐式反馈数据(0-1)。
余弦相似度在度量文本相似度、用户相似度、物品相似度的时候都较为常用。
皮尔逊相关度,实际上也是一种余弦相似度。不过先对向量做了中心化,范围在−1−1。
相关度量的是两个变量的变化趋势是否一致,两个随机变量是不是同增同减。
不适合用作计算布尔值向量(0-1)之间相关度。
基于用户的协同过滤
基本思想:基于用户的协同过滤(UserCF):
- 例如,我们要对用户 AA 进行物品推荐,可以先找到和他有相似兴趣的其他用户。
- 然后,将共同兴趣用户喜欢的,但用户 AA 未交互过的物品推荐给 AA。
计算过程:以下图为例,给用户推荐物品的过程可以形象化为一个猜测用户对物品进行打分的任务,表格里面是5个用户对于5件物品的一个打分情况,就可以理解为用户对物品的喜欢程度。
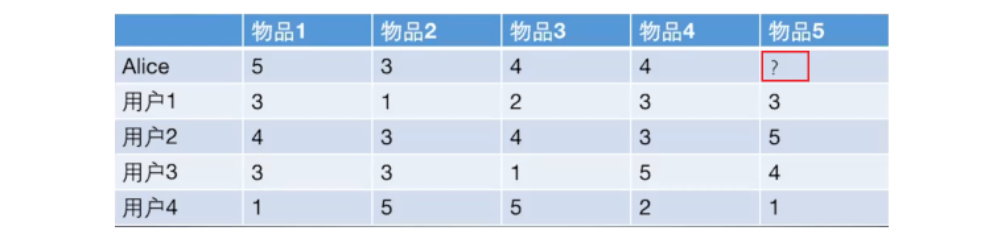
image-20250619091223340 UserCF算法的两个步骤:
- 首先,根据前面的这些打分情况(或者说已有的用户向量)计算一下 Alice 和用户1, 2, 3, 4的相似程度, 找出与 Alice 最相似的 n 个用户。
- 根据这 n 个用户对物品 5 的评分情况和与 Alice 的相似程度会猜测出 Alice 对物品5的评分。如果评分比较高的话, 就把物品5推荐给用户 Alice, 否则不推荐。
具体过程:
- 计算用户之间的相似度
- 根据 1.2 节的几种方法, 我们可以计算出各用户之间的相似程度。对于用户 Alice,选取出与其最相近的 NN 个用户。
- 计算用户对新物品的评分预测
- 常用的方式之一:利用目标用户与相似用户之间的相似度以及相似用户对物品的评分,来预测目标用户对候选物品的评分估计:
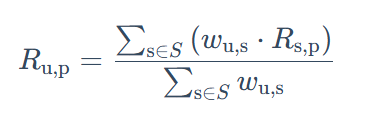
- 其中,

- 其中,
- 另一种方式:考虑到用户评分的偏置,即有的用户喜欢打高分, 有的用户喜欢打低分的情况。公式如下:
- 其中,

- 其中,
- 常用的方式之一:利用目标用户与相似用户之间的相似度以及相似用户对物品的评分,来预测目标用户对候选物品的评分估计:
- 对用户进行物品推荐
- 在获得用户u 对不同物品的评价预测后, 最终的推荐列表根据预测评分进行排序得到。
手动计算:
根据上面的问题, 下面手动计算 Alice 对物品 5 的得分:
计算 Alice 与其他用户的相似度(基于皮尔逊相关系数)
手动计算 Alice 与用户 1 之间的相似度:

image-20250619091716297 计算所有用户之间的皮尔逊相关系数。可以看出,与 Alice 相似度最高的用户为用户1和用户2。
image-20250619091730895
根据相似度用户计算 Alice对物品5的最终得分 用户1对物品5的评分是3, 用户2对物品5的打分是5, 那么根据上面的计算公式, 可以计算出 Alice 对物品5的最终得分是
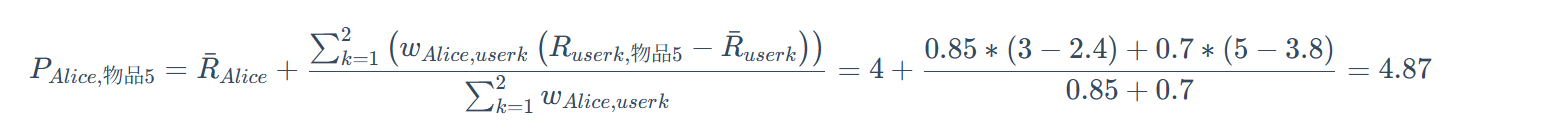
image-20250619092009827 - 同样方式,可以计算用户 Alice 对其他物品的评分预测。
根据用户评分对用户进行推荐
- 根据 Alice 的打分对物品排个序从大到小:物品1>物品5>物品3=物品4>物品2
- 如果要向 Alice 推荐2款产品的话, 我们就可以推荐物品 1 和物品 5 给 Alice。
大白话说明上面的计算:
一、余弦相似性(看两个向量 “方向” 有多像)
你可以把 Alice 和 user1 的向量,想象成空间里的两条 “有方向的线段”。余弦相似性就是看这两条线段 “方向” 有多接近,角度越小、越靠拢,相似性越高。 1. 分子:向量对应位置相乘再相加(衡量 “同向程度”) Alice 向量是 (5,3,4,4),user1 是 (3,1,2,3)。 把对应位置的数相乘: 5×3 = 15(第一个数相乘)、3×1 = 3(第二个数相乘)、4×2 = 8(第三个数相乘)、4×3 = 12(第四个数相乘)。 再把这些乘积加起来:15 + 3 + 8 + 12 = 38 。 这一步是看两个向量在各个维度上,“同方向使劲” 的叠加效果,数值越大,说明整体上越容易往一个方向走。 2. 分母:两个向量 “长度” 的乘积(标准化用,避免向量太长影响判断) 先算 Alice 向量的 “长度”:把每个数平方后相加,再开平方。 Alice 平方和:5² + 3² + 4² + 4² = 25 + 9 + 16 + 16 = 66 ,开平方后就是 √66(可以简单理解成线段的长度)。 再算 user1 向量的 “长度”:3² + 1² + 2² + 3² = 9 + 1 + 4 + 9 = 23 ,开平方后是 √23 。 分母就是这两个 “长度” 相乘:√66 × √23 。 这一步是为了 “公平比较”,不管向量本身多长,都压缩到类似的尺度,否则一个很长的向量,光凭分子大,也会显得 “相似”,但其实可能是因为自己数值大,不是真的方向像。 3. 最后相除得余弦相似性 用分子 38 除以分母 √66 × √23 ,算出来约 0.975 。数值越接近 1 ,说明两个向量方向越像,相似性越高。二、皮尔逊相关系数(看 “去掉平均值后,趋势有多一致”)
简单说,皮尔逊更关注 “去掉各自平均值后,两个向量的变化趋势” ,比如一个涨、另一个也涨,或者一个跌、另一个也跌,就会让系数高。 1. 先算各自的平均值(找 “基准线”) Alice 向量 (5,3,4,4) ,四个数加起来 5+3+4+4=16 ,平均值 16÷4 = 4(Alice_ave = 4 )。 user1 向量 (3,1,2,3) ,四个数加起来 3+1+2+3=9 ,平均值 9÷4 = 2.25(user1_ave = 2.25 )。 平均值就是各自向量的 “基准线”,后面要把每个数和基准线的差距算出来。 2. 向量减去平均值(看每个数 “偏离基准线” 多少) Alice 每个数减平均值 4 : 5-4=1 、3-4=-1 、4-4=0 、4-4=0 → 得到新向量 (1, -1, 0, 0) 。 user1 每个数减平均值 2.25 : 3-2.25=0.75 、1-2.25=-1.25 、2-2.25=-0.25 、3-2.25=0.75 → 得到新向量 (0.75, -1.25, -0.25, 0.75) 。 这一步后,向量就变成了 “相对于自己平均值的波动情况”,方便看两个向量 “波动趋势” 是否一致。 3. 算新向量的余弦相似性(和第一步逻辑一样,看波动趋势的方向) 把新的两个向量,按照余弦相似性的方法再算一遍: 分子:对应位置相乘再相加 → 1×0.75 + (-1)×(-1.25) + 0×(-0.25) + 0×0.75 = 0.75 + 1.25 + 0 + 0 = 2 。 分母:各自新向量的 “长度” 相乘。 Alice 新向量长度:√(1² + (-1)² + 0² + 0²) = √(1 + 1) = √2 。 user1 新向量长度:√(0.75² + (-1.25)² + (-0.25)² + 0.75²) ,算一下平方和:0.5625 + 1.5625 + 0.0625 + 0.5625 = 2.75 ,开平方后是 √2.75 。 分母就是 √2 × √2.75 。 最后相除:2 ÷ (√2 × √2.75) ,算出来约 0.852 。 这个结果越接近 1 ,说明去掉平均值后,两个向量的波动趋势越一致,相关度越高。 总结一下: 余弦相似性更直接看 “原始向量方向像不像”; 皮尔逊相关系数,是先把向量拉到 “以自己平均值为基准”,再看 “波动趋势像不像” 。 你可以理解成,余弦是 “看表面姿势像不像”,皮尔逊是 “看去掉自身基础后,变化节奏像不像” ,这样就好记多啦~算法评估
由于UserCF和ItemCF结果评估部分是共性知识点, 所以在这里统一标识。

image-20250619102709338
2 ItemCF 基于物品的协同过滤
基于物品的协同过滤(ItemCF):
- 预先根据所有用户的历史行为数据,计算物品之间的相似性。
- 然后,把与用户喜欢的物品相类似的物品推荐给用户。
举例来说,如果用户 1 喜欢物品 A ,而物品 A 和 C 非常相似,则可以将物品 C 推荐给用户1。ItemCF算法并不利用物品的内容属性计算物品之间的相似度, 主要通过分析用户的行为记录计算物品之间的相似度, 该算法认为, 物品 A 和物品 C 具有很大的相似度是因为喜欢物品 A 的用户极可能喜欢物品 C。
计算过程
那UserCF的例子来说,参考上午图片:
如果想知道 Alice 对物品5打多少分, 基于物品的协同过滤算法会这么做:
- 首先计算一下物品5和物品1, 2, 3, 4之间的相似性。
- 在Alice找出与物品 5 最相近的 n 个物品。
- 根据 Alice 对最相近的 n 个物品的打分去计算对物品 5 的打分情况。
手动计算:
手动计算物品之间的相似度

image-20250619103308597 根据皮尔逊相关系数, 可以找到与物品5最相似的2个物品是 item1 和 item4, 下面基于上面的公式计算最终得分:

image-20250619103850272
协同过滤算法的权重改进:

协同过滤算法的问题分析
协同过滤算法存在的问题之一就是泛化能力弱:
- 即协同过滤无法将两个物品相似的信息推广到其他物品的相似性上。
- 导致的问题是热门物品具有很强的头部效应, 容易跟大量物品产生相似, 而尾部物品由于特征向量稀疏, 导致很少被推荐。
3 Swing(Graph-based)
算法:
Swing 通过利用 User-Item-User 路径中所包含的信息,考虑 User-Item 二部图中的鲁棒内部子结构计算相似性。
什么是内部子结构? 以经典的啤酒尿布故事为例,张三同时购买了啤酒和尿布,这可能是一种巧合。但两个甚至多个顾客都同时购买了啤酒尿布,这就证明啤酒和尿布具有相关关系。这样共同购买啤酒和尿布的用户越多,啤酒和尿布的相关度就会越高。
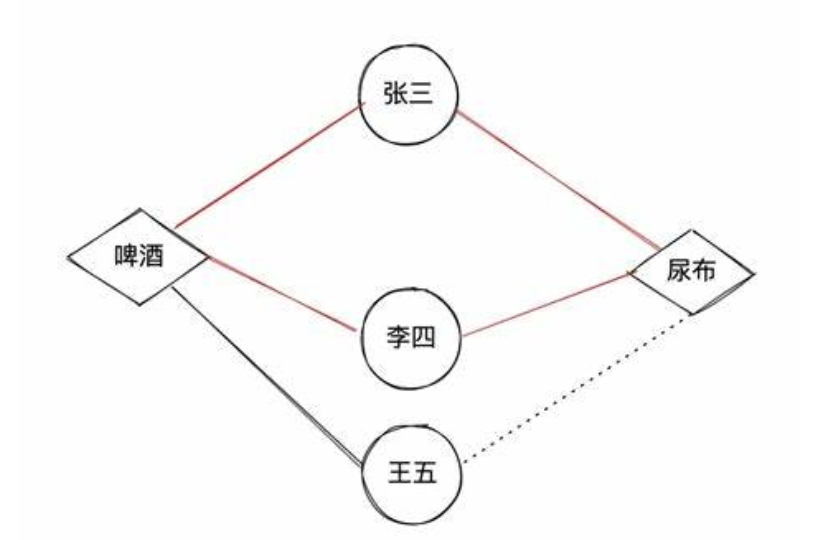
image-20250619110404951 通俗解释:若用户 uu 和用户 vv 之间除了购买过 ii 外,还购买过商品 jj ,则认为两件商品是具有某种程度上的相似的。也就是说,商品与商品之间的相似关系,是通过用户关系来传递的。为了衡量物品 ii 和 jj 的相似性,比较同时购买了物品 ii 和 jj 的用户 uu 和用户 vv, 如果这两个用户共同购买的物品越少,即这两个用户原始兴趣不相似,但仍同时购买了两个相同的物品 ii 和 jj, 则物品 ii 和 jj 的相似性越高。
计算公式
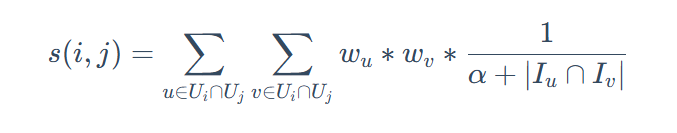
image-20250619110421781
其中U**i 是点击过商品i的用户集合,I**u 是用户u点击过的商品集合,α是平滑系数。

Surprise算法
首先在行为相关性中引入连续时间衰减因子,然后引入基于交互数据的聚类方法解决数据稀疏的问题,旨在帮助用户找到互补商品。互补相关性主要从三个层面考虑,类别层面,商品层面和聚类层面。
4 矩阵分解
协同过滤算法的特点:
- 协同过滤算法的特点就是完全没有利用到物品本身或者是用户自身的属性, 仅仅利用了用户与物品的交互信息就可以实现推荐,是一个可解释性很强, 非常直观的模型。
- 但是也存在一些问题,处理稀疏矩阵的能力比较弱。
为了使得协同过滤更好处理稀疏矩阵问题, 增强泛化能力。从协同过滤中衍生出矩阵分解模型(Matrix Factorization, MF)或者叫隐语义模型:
- 在协同过滤共现矩阵的基础上, 使用更稠密的隐向量表示用户和物品。
- 通过挖掘用户和物品的隐含兴趣和隐含特征, 在一定程度上弥补协同过滤模型处理稀疏矩阵能力不足的问题。
2.2 基于向量的召回
2.2.1 FM 模型结构
我们用一个推荐系统的例子,大白话带你理解 FM 是怎么工作的👇
🎬 场景设定
你在做一个电影推荐系统,现在要判断:
用户 A 看不看电影《阿凡达》?
你有以下特征:
| 特征名 | 特征值 |
|---|---|
| 用户性别 | 男 |
| 用户年龄段 | 18-25岁 |
| 用户职业 | 学生 |
| 电影类型 | 科幻 |
| 电影标签 | 高分、动作 |
🧠 FM 怎么理解这些特征?
传统线性模型只会做这件事👇:
预测评分 = w0 + w1*性别 + w2*年龄 + w3*职业 + w4*类型 + w5*标签就是每个特征加权求和。
❗️问题:这无法捕捉“组合效果”!
比如:
- 男性对“科幻片”更感兴趣
- 学生喜欢“动作片”
- 年轻人爱看“高分电影”
这些都无法在单个特征里表达。
🎯 FM 的魔法来了!
FM 把这些组合关系也考虑进来!比如:
markdown复制编辑预测评分 = 线性部分 +
男性 × 科幻 的兴趣分 +
学生 × 动作 的兴趣分 +
18-25岁 × 高分 的兴趣分 + ...这些组合关系不是硬编码出来的,而是通过“特征向量的点积”学出来的!
💡 举个组合向量的例子(伪代码思想)
v_性别 = [0.1, 0.3]
v_电影类型 = [0.5, 0.2]
v_性别 ⋅ v_电影类型 = 0.1×0.5 + 0.3×0.2 = 0.11说明“男 + 科幻”组合给这个用户带来了 +0.11 的偏好提升!
✅ 最终效果
FM 输出的评分 =
通用打分(线性) + 组合打分(特征间相性)
于是它就知道:
这个用户虽然没看过《阿凡达》,但从“男 + 科幻 + 动作 + 高分”的组合来看,他八成会喜欢!
还想看看 FM 的实际 PyTorch 实现,或者它怎么进化成 DeepFM 吗?我也能帮你撸代码~ 💻
2.2.2 Word2Vec的原理
在所有的NLP任务中,首先面临的第一个问题是我们该如何表示单词。这种表示将作为inputs输入到特定任务的模型中,如机器翻译,文本分类等典型NLP任务。
同义词表达单词
一个很容易想到的解决方案是使用同义词来表示一个单词的意义。 比如WordNet,一个包含同义词(和有“is a”关系的词)的词库。
!pip install --user -U nltk !python -m nltk.downloader popularWordNet的问题
- 单词与单词之间缺少些微差异的描述。比如“高效”只在某些语境下是"好"的同义词
- 丢失一些词的新含义。比如“芜湖”,“蚌埠”等词的新含义
- 相对主观
- 需要人手动创建和调整
- 无法准确计算单词的相似性
one-hot编码
在传统NLP中,人们使用one-hot向量(一个向量只有一个值为1,其余的值为0)来表示单词 如:motel = [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0]
如:hotel = [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0]
one-hot向量的维度是词汇表的大小(如:500,000)
注:上面示例词向量的维度为方便展示所以比较小one-hot向量表示单词的问题:
- 这些词向量是正交向量,无法通过数学计算(如点积)计算相似性
- 依赖WordNet等同义词库建立相似性效果也不好
dense word ventors表达单词
如果我们可以使用某种方法为每个单词构建一个合适的dense vector,如下图,那么通过点积等数学计算就可以获得单词之间的某种联系。
Word2vec
一个单词的意义由它周围的单词决定
下面用一个故事来说明Word2Vec
🏰 故事主角:词国的搬砖工们
在一个叫“词国”的地方,住着很多词语小人,比如:
- 👑 “king”(国王)
- 👩 “queen”(王后)
- 🧔 “man”(男人)
- 👩🦰 “woman”(女人)
- 🐱 “cat”、🐶 “dog”、🍕 “pizza” 等
他们每天在语言大厦里“搬砖”(也就是出现在句子中)。
🚪一天,国王下令:
“所有词语小人必须住进词向量空间!谁住得离谁近,代表谁跟谁更像!”
但词语小人很困惑:
“我们怎么知道自己和谁像?‘cat’ 和 ‘dog’ 是邻居吗?‘king’ 和 ‘queen’ 是一家人吗?”
🧠 智者Word2Vec登场
Word2Vec 智者说:
“我来教大家按出现位置自动学会谁跟谁关系好!”
他制定了一套规矩 👇:
📚 Word2Vec的训练计划
方式一:Skip‑Gram(以己推人)
比如有句子:“The king loves the queen.”
- 智者说:“我观察到 ‘king’ 出现在了 ‘the’ 和 ‘loves’ 之间,我就记录下这个配对。”
- 训练目标:用“king”来预测“the”、"loves"。
这样所有词小人都开始记录自己旁边经常一起搬砖的小伙伴。
方式二:CBOW(众人推我)
还是同一句话:
- 智者反过来说:“我看到 ‘the’ 和 ‘loves’ 夹着一个词,我猜你们在说‘king’。”
- 训练目标:用“上下文”来预测中心词。
🧩 怎么学出来的呢?
每个词都得到一个“坐标”(向量),如果它总跟某些词一起出现,它们的向量就会越靠近。
比如:
- “king” 和 “queen”经常出现在相似语境里
- “man” 和 “woman” 也是
最终出现神奇效果:
$$
\text{"king"} - \text{"man"} + \text{"woman"} ≈ \text{"queen"}
$$
就像“国王去掉男人的特点,加上女人的特点,就是王后”!是不是很酷!
🧱 为什么叫 Word2Vec?
因为它的目标就是把每个**Word(词)**变成一个向量(Vector),而且这个向量能表示:
- 谁跟谁是朋友(语义相近)
- 谁跟谁工作方式一样(上下文相似)
✅ 故事总结:
Word2Vec 就像一个观察语言世界的“记者”,通过谁跟谁经常一起出现,给每个词分配一个“住址”(向量),住得越近说明关系越好。
🌰 一句话理解负采样
负采样就是:不跟所有词比较,只随机挑几个“假词”来骗模型,效率翻倍!
🧠 背景问题:Softmax 太慢了!
在 Word2Vec 的 Skip-gram 里,训练的目标是:
用中心词预测上下文词
那输出是一个概率分布,比如给定词 “king”,你要算它预测“queen”、“man”、“pizza”等词的概率。
这时候 softmax 要遍历词典中所有词(比如 10 万个词),每次训练都要算一大堆点积 + exp + 归一化,计算量爆炸💥
💡 负采样解决什么?
它说:
“我不跟所有词比较,我就只关注:
- 正确的词(真词)
- 随机几个错误的词(假词)
让模型学会区分真和假就够了!”
🔧 举个例子更清楚!
比如一句话:“The king loves the queen.”
- 中心词是:"king"
- 正确上下文词之一:"queen"
传统做法:用 softmax 算 “queen”、“man”、“pizza”、“cat”、... 所有词的概率,再最大化 queen 的概率 —— 太累。
负采样做法:
- 把“queen”当作正样本(label=1)
- 随机选 5 个无关词,比如 “cat”、“pizza”、“banana”… 当负样本(label=0)
然后用一个二分类模型来训练模型:
text复制编辑模型目标:
king + queen → 越相似越好(1)
king + banana → 越不相似越好(0)
...是不是一下轻松了?再也不用理会 99995 个词!
文章正文如下,需要反复理解阅读:
Word2vec概述:Word2vec包含两个模型,Skip-gram与CBOW。
Word2vec模型结构
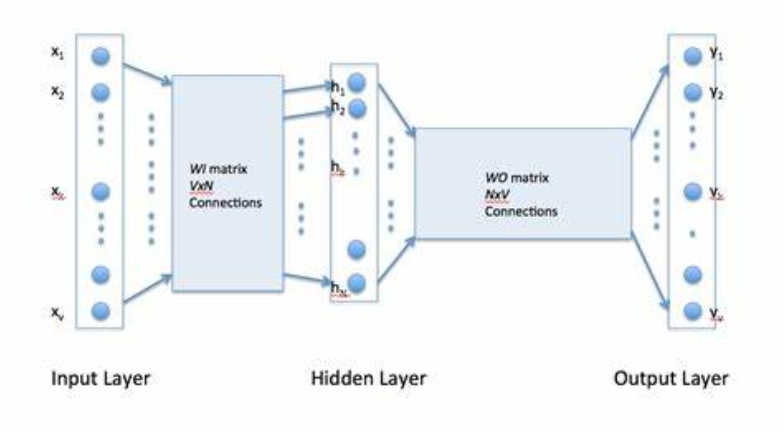
如图所示,这是一个输入为1 X V维的one-hot向量(V为整个词汇表的长度,这个向量只有一个1值,其余为0值表示一个词),单隐藏层(隐藏层的维度为N,这里是一个超参数,这个参数由我们定义,也就是词向量的维度),输出为1 X V维的softmax层的模型。
2.2.3 item2vec
下面是 Item2Vec 的结构化解释,用大白话帮你梳理清楚它到底是干啥的、怎么实施、优劣在哪 👇
1. 📌 基本概念
- Item2Vec 是借鉴 Word2Vec(Skip‑Gram with Negative Sampling)的方法,把商品/内容当作“词”,把 用户会话或购物篮当作“句子”,通过“共现”训练生成稠密的item 向量(embeddings) (arxiv.org)。
- 목표是:让在同一个会话/同一个篮子的 items 它们的向量更接近。
2. 💡 模型结构(类似 Skip‑Gram)
- 输入:一个 item(中心 item)
- 输出:预测会话中出现的所有其他 items(上下文 items)
- 算相似度:测中心 item 和上下文 item 的向量点积,然后通过 sigmoid 判断是不是正样本 。
训练目的是 最大化真实 co‑occur 的 pairs 的相似度,同时最小化随机选择的不相关 pairs 的相似度。
3. 🔁 Negative Sampling(负采样)
- 不像 softmax 要遍历所有 item,item2vec 的训练只选少量与中心 item 不在同一篮子的“假 item”作为负样本 。
- 损失函数:
- 第一个是“正样本”提升相似度,
- 第二项是“负样本”降低不该靠近的 pairs 的相似度。
4. 🧩 为什么结构化成这样?
- Co‑occurrence 假设:如果两个 item 经常被一起浏览/购买,就说明它们“相关”,可以对齐到相近向量 (tech.olx.com, dynamicyield.com)。
- 稀疏问题解决:而且即使是“冷门商品”,只要出现在某个会话里,也会被学习到 embedding。
- 速度快:负采样+SG可以训练非常大的 item 词典 ✔️
5. 🔬 实验与效果
- 在 OLX、微软 Music、Microsoft Store 等大规模数据集上,Item2Vec 学到的 embedding 在:
- item 相似度搜索
- 商品聚类
- Cold‑start 推荐初始化
比传统 SVD 算法效果更好 (tech.olx.com, ceur-ws.org)。
- 数据稀疏时提升尤明显,特别是冷门 item 相比 SVD 精度更高(68% vs 58%)。
✅ 小结用表格记忆
| 项 | Item2Vec(好处) |
|---|---|
| 原理 | 借用 Word2Vec(Skip‑Gram + 负采样) |
| 输入 | item × item 会话/购物篮(类似句子) |
| 输出 | item 向量(dense embedding) |
| 优点 | 弱标签也能学, 弱冷启动, 快训练, 好效果 |
| 常见用途 | 相似推荐、聚类、embedding 提取 |
🌐 整体流程图(大白话)
- 收集 用户历史会话或购物篮;
- 把每个 basket 当作“句子”,里面的商品是“词”;
- 用 Skip‑Gram + 负采样训练;
- 训练出来的 item 向量:
- 相似 item 向量靠近;
- 可以用于**“有人看了 A,也顺便推荐 B”**那种场景。
2.2.4 YouTubeDNN
理解起来非常复杂,就YouTubeDNN的架构和组成进行Image上的理解。
1. YouTubeDNN 是做什么的(推荐系统阶段)
YouTube 的推荐系统分为多阶段:**候选集生成(Candidate Generation)和排序(Ranking)**两个阶段。YouTubeDNN 主要负责第一阶段——从海量视频中召回少量候选视频。通俗地说,它类似于给每个用户做一个“兴趣画像”,从几百万个视频里快速筛选出几百个最相关的视频。这一步做完后,再交给后续的排序模型根据更多细节评分排序。说明,候选集生成网络以用户的历史行为为输入,从百万视频中选出数量级为百的视频列表,保证精度和多样性。
2. YouTubeDNN 的整体结构
YouTubeDNN 的结构可以想象成“多路输入,拼接特征,再经过全连接网络,输出用户向量”。具体过程包括:
- 输入特征:用户最近的观看历史、搜索词、地区、性别、年龄等信息。
- Embedding层:将稀疏的ID或词(如视频ID、搜索词ID、地理区域ID等)映射为密集向量。例如,每个视频ID映射到一个向量表示,搜索词拆成词组后映射向量,地区/设备/年龄等也做嵌入。
- 特征合并:把不同来源的向量拼起来或平均。例如,用户看过的视频向量先做平均得到一个“看过向量”,搜索词词向量平均得到一个“搜索向量”,然后将这些向量和其他特征拼接,形成网络的第一层输入。
- DNN层:将合并后的特征经过多层全连接(ReLU激活)网络,生成一个固定长度的用户兴趣向量(如256维)。可以把这个向量看作当前用户偏好的浓缩表征。
- 向量输出:网络最后的隐藏层输出就是用户向量 $u$。对于视频,每个视频 $i$ 也有一个对应的向量 $v_i$(在训练时作为输出层权重学习得到)。简言之,用户和视频都在同一空间有向量表示。
整个流程可以理解为:“给你和每个视频都贴一个数字标签(向量),把它们放在同一张兴趣地图里”,网络学到的用户向量和视频向量就决定了推荐匹配关系。
3. 核心思想:用户和视频向量建模兴趣、向量匹配
YouTubeDNN 的核心思想是将推荐问题看作向量匹配。具体来说:网络学习一个函数,将用户历史和背景映射成一个用户向量 $u$,同时为每个视频学习一个视频向量 $v_i$。当用户对视频的喜好增加时,对应的用户向量和视频向量会越“接近”。最终推荐时,根据两者的点积(内积)**来评价相关度:$\text{score}(u,i)=v_i^\top u$。点积值越大,表示该视频越符合用户兴趣。可以打个比方:**用户向量**像是一堆标尺(兴趣标签),**视频向量**是视频特征在这堆标尺上的投影。相似性越高,就越可能推荐。正如文中所说:“嵌入是将稀疏实体(视频、用户等)映射到高维空间中。网络的任务就是学习对区分视频有用的用户嵌入”。换句话说,YouTubeDNN把推荐转化为**极端多分类问题,用深度网络学到用户和视频的共同空间。
4. 为什么不用 Softmax 直接预测而用向量匹配
传统分类模型会用 Softmax 对每个视频计算概率,但在YouTube这种规模下有数百万视频,用 Softmax 非常困难:
- 类别太多、分布稀疏:对一个用户而言,能观看的视频只占亿万分之一,真实标签极稀疏。Softmax 要对所有视频分类,计算量极大,不现实。
- 只需要排前几名:实际应用中不需要精确的概率值,只要找出最可能被点击的视频。因此,他们采用了近似做法:训练时使用(采样)Softmax,推理时直接用点积查最相似的视频。如文中所述:到线上服务阶段,不需要 Softmax 的校准概率,评分转化成点积空间的最近邻搜索。也就是说,只关心 $v_i^\top u$ 的大小,而非计算完整 Softmax。这样大大提升了检索效率。
用大白话比喻:如果让你从一亿本书里选一本,你不会一个一个都打分,只会挑感兴趣的几百种主题,然后在这些主题内选。YouTubeDNN也是这个思路——先挑出“相关性高”的视频子集,再根据向量相似度取最优,而不是对所有视频都做精确评分。
5. 模型如何训练:正负样本采样与损失
训练阶段需要教网络区分用户喜欢和不喜欢的视频,一般做法是正负采样结合交叉熵损失或类似目标。具体思路包括:
- 正样本:用户实际观看(完整观看)的视频作为正例。这就是隐式反馈,反馈信号丰富,不用稀缺的点赞数据。
- 负样本采样:由于视频太多,无法把所有没看过的视频都当负样本。一般随机从大背景分布中采几个千倍于正样本数量的负样本(即“采样Softmax”)。这种方法类似Word2Vec中给词选择负例的做法。
- 损失函数:通常使用交叉熵损失(Softmax 交叉熵)训练网络,只对真实观看的视频标签最小化损失,同时推高负样本的损失。这样网络学习到让用户向量 $u$ 与正例视频向量 $v^+$ 点积更大,与负例 $v^-$ 点积更小。另一种思想是对比损失(如三元组损失):直接将三元组(用户,正视频,负视频)送入网络,最大化正例与用户相似度、最小化负例相似度。这与上面采样Softmax本质相通,都强调让用户-正视频向量匹配更紧密。
- 重要性权重:论文中还提到对采样修正使用重要性加权,以校准采样带来的偏差。
- 细节:训练时所有用户行为都用上(包括埋入在其他页面的播放),并对活跃用户做下采样,保证模型公平地学习不同用户兴趣。
简单总结:训练时不断告诉模型“这个用户看了这个视频(正样本),没有看那些视频(负样本)”,网络通过反向传播学习到一组用户和视频向量,使得正向示例的向量点积更大。
6. 与 Word2Vec/Item2Vec 的关系和区别
YouTubeDNN 和 Word2Vec/Item2Vec 有一定相似性,但也有差别:
- 共同点:三者都要学习“嵌入”——将离散的对象(单词、商品、视频)表示为向量。它们都可以采用负采样来加速训练。YouTubeDNN 在设计上就受到词袋模型(Word2Vec CBOW)的启发:把用户观看历史看作上下文,预测下一个要看的视频。就像Word2Vec根据前后词预测某个词,Item2Vec根据商品共现训练商品嵌入,YouTubeDNN 根据用户历史预测感兴趣的视频。
- 不同点:Word2Vec/Item2Vec 通常是无监督学习,只用简单的神经网络(或矩阵分解)的浅层结构对上下文进行预测,不考虑其他信号。YouTubeDNN 则是监督学习,用用户的真实点击数据训练多层深度网络。它不仅用到序列中的视频,还加了用户ID、搜索词、地域、年龄等多种特征。Word2Vec只学习单词与上下文间的统计关系;YouTubeDNN学习到的用户向量和视频向量兼顾了用户个人偏好和视频属性,是更复杂、更个性化的表示。因此可以说YouTubeDNN是对Item2Vec/Word2Vec思路的“深度”推广:在更丰富的输入下用更深的网络求解推荐任务。
7. 优势与应用场景
YouTubeDNN 的设计使其在大规模推荐场景下非常有用,其主要优势包括:
- 可扩展性强:它一次性面对亿级视频,利用负采样和近似搜索仅算出几百个候选,效率极高。同时可以用成熟的近邻搜索库(如FAISS)快速返回结果。
- 灵活性高:可以方便地加入各种特征。与传统协同过滤只能用用户和视频ID不同,深度网络能把搜索词、地域、年龄等各种信息整合到同一个模型中,提高推荐多样性和准确度。
- 非线性表达能力:通过多层网络学习到的是非线性特征组合,相比线性矩阵分解能发现更复杂的兴趣模式。
- 效果显著:实验证明,在候选集生成任务上深度模型效果优于传统模型(本文提到这是对矩阵分解的非线性推广)。它能更好地捕捉用户兴趣随时间和上下文的变化。
- 通用场景:这个模型不仅适用于视频网站推荐,也适合任何需要从海量项目中检索相关内容的场景,比如电商推荐、新闻推荐等,只要把用户历史和内容特征放进网络,就能获得高性能召回。
举例来说,当网站需要大规模召回时(例如百万级商品的个性化检索),YouTubeDNN式的双塔向量匹配特别有效:可以离线预先计算商品向量,在线计算用户向量,然后用近邻搜索快速匹配。这种方法效率高、准确性好,是推荐系统候选生成阶段的主流方案之一。
参考资料: Covington 等人《Deep Neural Networks for YouTube Recommendations》论文、相关技术博客等。
文章正文如下,需要反复理解阅读:
2.3 经典排序模型之特征交叉
1 为什么会有Wide&Deep
在 CTR(点击通过率)预测这个事儿上,以前大家常用线性模型,不过得自己手动设计一些 “特征组合”。比如说,把 “用户性别” 和 “看过的商品类型” 这俩特征搭配起来,让模型记住哪些特征组合经常一起出现(这就叫 “记忆性”)。用这种方法搭出来的基础模型效果还不错,而且每个特征为啥有用看得明明白白。但它有俩大毛病:
第一,手动设计这些特征组合太费时间精力了,得懂业务还得花大量功夫;第二,模型只会死记硬背见过的特征组合,如果遇到没见过的新组合,它就直接当不存在(权重设为 0),完全不会举一反三。
后来为了让模型能 “举一反三”(也就是提高泛化能力),有人引入了 DNN(深度神经网络)。DNN 会把那些又多又稀疏的特征(比如用户 ID、商品 ID 这种)转换成更紧凑的 “Embedding 向量”(类似给特征搞了个 “压缩编码”),这样模型就能更好地处理没见过的新特征组合了。但新问题又来了:如果数据里有些特征出现次数很少(长尾分布),模型可能学不透这些特征,算出来的 Embedding 向量不准,反而会让模型 “想太多”(泛化过度)。
那 Wide&Deep 模型是干啥的呢?它就是专门解决 “记忆性” 和 “泛化性” 的矛盾。所谓 “记忆性”,就是模型能记住历史数据里经常一起出现的特征组合(比如老用户总爱点某类商品);“泛化性” 就是模型能根据特征之间的关联,推测出没见过的新组合(比如没买过手机的用户可能对手机配件感兴趣)。这个模型把两种能力结合起来,还在 Google 应用商店的推荐场景里用得很成功。
2 模型结构和原理
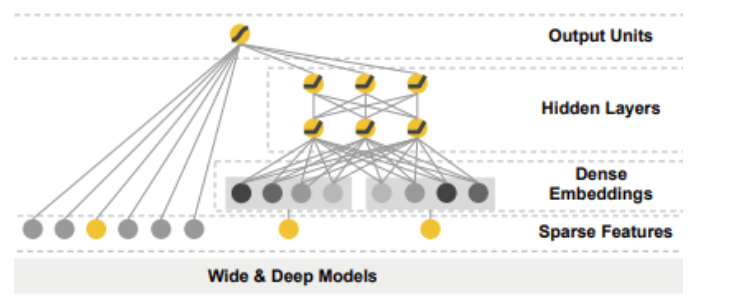
这是 Wide&Deep 模型 的架构示意图,从下往上分层理解更清晰:
1. 底层(Sparse Features)
最下面的 “Sparse Features”(稀疏特征 ),就是像用户 ID、商品 ID、类别标签这类数量多、值很分散的原始数据。比如电商场景里,每个用户 ID 都是独一无二的,单独看就是 “稀疏” 零散的。
2. 中间层(Dense Embeddings + 拆分结构)
左边 Wide 侧(手动特征组合 ):
对应 “手工构造交叉特征” 的思路,直接拿原始稀疏特征做简单拼接、交叉(比如 “用户性别 + 商品类型” 组合 ),让模型 记住高频出现的特征搭配(也就是 “记忆性 Memorization” )。右边 Deep 侧(Embedding + 神经网络 ):
先把高维稀疏的特征,通过 “Dense Embeddings”(稠密嵌入 )压缩成低维、密集的向量(比如把百万级用户 ID 压缩成几百维的向量 )。再丢给 “Hidden Layers”(隐藏层,即 DNN 结构 ),让模型挖掘特征间的关联,探索没见过的新组合(也就是 “泛化性 Generalization” )。但图里也藏着问题:如果数据是 “长尾分布”(大部分是少数高频特征,少部分是低频特征 ),低频特征的 Embedding 可能学不透彻,导致模型泛化过度(比如乱猜没依据的特征关联 )。
3. 上层(Output Units)
最后,Wide 侧和 Deep 侧的结果会 “合流” 到 “Output Units”(输出层 ),一起预测结果(比如点击概率 )。这样就同时兼顾了 记忆性(记住高频组合) 和 泛化性(探索新组合),让模型在实际场景(比如 Google Play 应用商店推荐 )里更靠谱。
简单说,这图就是 Wide&Deep 模型的 “分身术”:一边用 Wide 侧死记硬背高频规律,一边用 Deep 侧脑洞大开探索新关联,最终合体解决 “既要记住历史、又要预判未来” 的推荐难题~
3 代码实现和解释
# Wide&Deep 模型的wide部分及Deep部分的特征选择,应该根据实际的业务场景去确定哪些特征应该放在Wide部分,哪些特征应该放在Deep部分
def WideNDeep(linear_feature_columns, dnn_feature_columns):
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
# Wide&Deep模型论文中Wide部分使用的特征比较简单,并且得到的特征非常的稀疏,所以使用了FTRL优化Wide部分(这里没有实现FTRL)
# 但是是根据他们业务进行选择的,我们这里将所有可能用到的特征都输入到Wide部分,具体的细节可以根据需求进行修改
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
dnn_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
# 在Wide&Deep模型中,deep部分的输入是将dense特征和embedding特征拼在一起输入到dnn中
dnn_logits = get_dnn_logits(dense_input_dict, sparse_input_dict, dnn_sparse_feature_columns, embedding_layers)
# 将linear,dnn的logits相加作为最终的logits
output_logits = Add()([linear_logits, dnn_logits])
# 这里的激活函数使用sigmoid
output_layer = Activation("sigmoid")(output_logits)
model = Model(input_layers, output_layer)
return model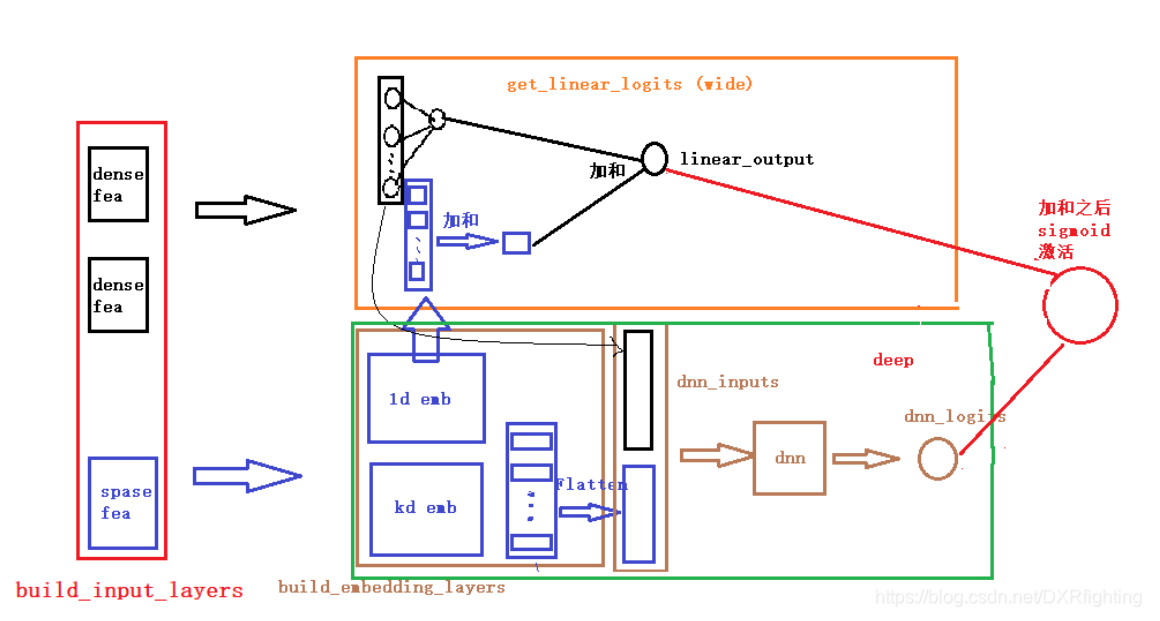
这是 Wide&Deep 模型 的工程实现流程图,把模型拆分、运行逻辑拆得更细了,结合代码 / 工程视角理解会更清晰:
1. 输入层(build_input_layers)
左边 “dense fea”(稠密特征,比如用户年龄、消费金额 )和 “sparse fea”(稀疏特征,比如用户 ID、商品 ID ),是模型的原始输入。
- 稠密特征:数值连续、直接能用(比如年龄 25 岁,金额 100 元 )。
- 稀疏特征:类别多、维度高(比如百万级用户 ID ),得特殊处理。
2. 特征处理层(build_embedding_layers)
中间这部分,是对稀疏特征的 “Embedding 化” 处理:
- 1d emb、kd emb:把高维稀疏的特征(比如用户 ID ),压缩成低维稠密的向量(比如 1 维、k 维的 Embedding )。这一步是为了让 Deep 侧的 DNN 能 “吃得下” 稀疏特征。
- Flatten:把 Embedding 后的多维向量 “拍扁” 成一维,方便和其他特征拼接,生成 “dnn_inputs”(Deep 侧的输入 )。
3. Wide 侧(get_linear_logits)
橙色框里的 “Wide 支路”,干的是 “记忆高频组合” 的事儿:
- 直接拿原始特征(尤其是手动交叉的特征组合,比如 “用户性别 + 商品类型” ),走简单的线性模型(比如逻辑回归 )。
- “加和” 后输出 “linear_output”,让模型死记硬背高频出现的特征搭配(也就是 “Memorization 记忆性” )。
4. Deep 侧(deep)
绿色框里的 “Deep 支路”,干的是 “探索新组合” 的事儿:
- 把处理好的 “dnn_inputs” 丢给 “dnn”(多层神经网络 ),让模型挖掘特征间的隐藏关联(比如 “年轻用户 + 运动商品” 可能和 “户外装备” 有关联 )。
- 输出 “dnn_logits”,负责泛化性 Generalization(探索没见过的新特征组合 )。
5. 输出层(sigmoid 激活)
最后,Wide 侧的 “linear_output” 和 Deep 侧的 “dnn_logits” 会合并,通过 “sigmoid 激活” 输出预测结果(比如用户点击概率 )。
- 合流的意义:Wide 负责 “稳”(记住历史规律 ),Deep 负责 “变”(探索未来可能 ),两者互补解决 “记忆性 + 泛化性” 问题。
- 潜在问题:如果稀疏特征是 “长尾分布”(比如大部分是低频商品 ID ),它们的 Embedding 可能学不透彻,导致 Deep 侧泛化过度(比如乱关联不相关特征 )。
总结一下,这张图把 Wide&Deep 模型从 “输入 → 特征处理 → 双支路计算 → 输出” 的流程拆得很细,核心就是 “Wide 记规律,Deep 挖关联,合流出结果”,解决推荐场景里 “既要记住老用户喜好,又要给新用户猜喜好” 的难题~
4 DeepFM
1 模型的结构和原理
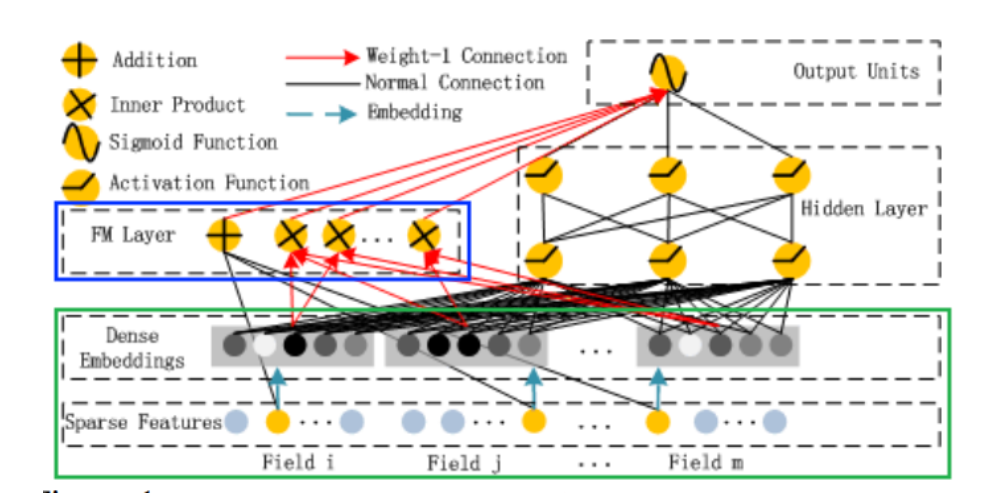
结合图例和流程,拆解核心逻辑:
一、基础流程:分层处理特征
- 输入层(最底层)
- Sparse Features(稀疏特征):像用户 ID、商品 ID 这类维度高、值稀疏的特征,比如千万级用户 ID,每个 ID 单独出现时数据很零散。
- Field(特征域):把稀疏特征按业务逻辑分组(如 “用户信息域”“商品信息域”),方便后续交叉计算。
- Dense Embedding 层(中间层)
通过Dense Embeddings(稠密嵌入),把高维稀疏的特征压缩成低维、密集的向量(比如把百万级 ID 压缩成几十维向量),解决传统模型 “维度灾难” 问题,也为 FM 和 DNN 提供可计算的特征表示。
二、核心创新:FM Layer(因子分解机层)
- 作用:自动挖掘二阶特征组合(如 “用户性别 + 商品类型” 这类简单但重要的组合规律),替代传统 Wide&Deep 里手动构造交叉特征的方式。
- 优势:不用人工设计交叉规则,靠数学方法(内积运算
Inner Product)自动找高频组合,高效强化模型 “记忆性”(记住用户习惯的常见搭配)。
三、双支路协同:记忆与泛化平衡
- FM 支路(负责 “记忆”)
FM 层通过自动交叉特征,让模型高效学习低阶、高频的特征组合(比如 “年轻用户 + 美妆商品” 的点击规律),解决传统 Wide 侧手动交叉的麻烦,强化Memorization(记忆性)。 - DNN 支路(负责 “泛化”)
经 Embedding 后的特征,输入Hidden Layer(隐藏层,即 DNN 结构),让模型挖掘高阶、隐藏的特征关联(比如 “用户收藏户外商品” 可能关联 “露营装备需求”),强化Generalization(泛化性),探索没见过的新组合。
四、输出层:结果融合与预测
- Addition(加法合并):FM 支路和 DNN 支路的结果汇总到
Output Units(输出层),结合两者优势。 - Sigmoid Function(激活函数):最终输出预测概率(如用户点击 likelihood),完成推荐场景的 CTR(点击通过率)预估。
五、解决的痛点与潜在问题
- 解决了啥:用 FM 自动交叉替代人工,既保留 Wide&Deep“记忆 + 泛化” 的平衡,又让低阶特征组合的学习更高效,适合电商、广告等推荐场景。
- 潜在问题:若数据是 “长尾分布”(少数特征高频、多数特征低频),低频特征的 Embedding 可能学不充分,导致 FM 交叉或 DNN 泛化 “跑偏”(比如硬凑不相关特征关联)。
简单说,这是 **“FM+DNN” 双引擎 ** 的推荐模型:FM 负责高效抓 “已知的高频规律”(记忆),DNN 负责挖 “未知的隐藏关联”(泛化),两者协同让推荐更准、更智能,常见于淘宝、抖音等平台的推荐系统~
2 代码实现
def DeepFM(linear_feature_columns, dnn_feature_columns):
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
# linear_logits由两部分组成,分别是dense特征的logits和sparse特征的logits
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
# embedding层用户构建FM交叉部分和DNN的输入部分
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
# 将输入到dnn中的所有sparse特征筛选出来
dnn_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
fm_logits = get_fm_logits(sparse_input_dict, dnn_sparse_feature_columns, embedding_layers) # 只考虑二阶项
# 将所有的Embedding都拼起来,一起输入到dnn中
dnn_logits = get_dnn_logits(sparse_input_dict, dnn_sparse_feature_columns, embedding_layers)
# 将linear,FM,dnn的logits相加作为最终的logits
output_logits = Add()([linear_logits, fm_logits, dnn_logits])
# 这里的激活函数使用sigmoid
output_layers = Activation("sigmoid")(output_logits)
model = Model(input_layers, output_layers)
return model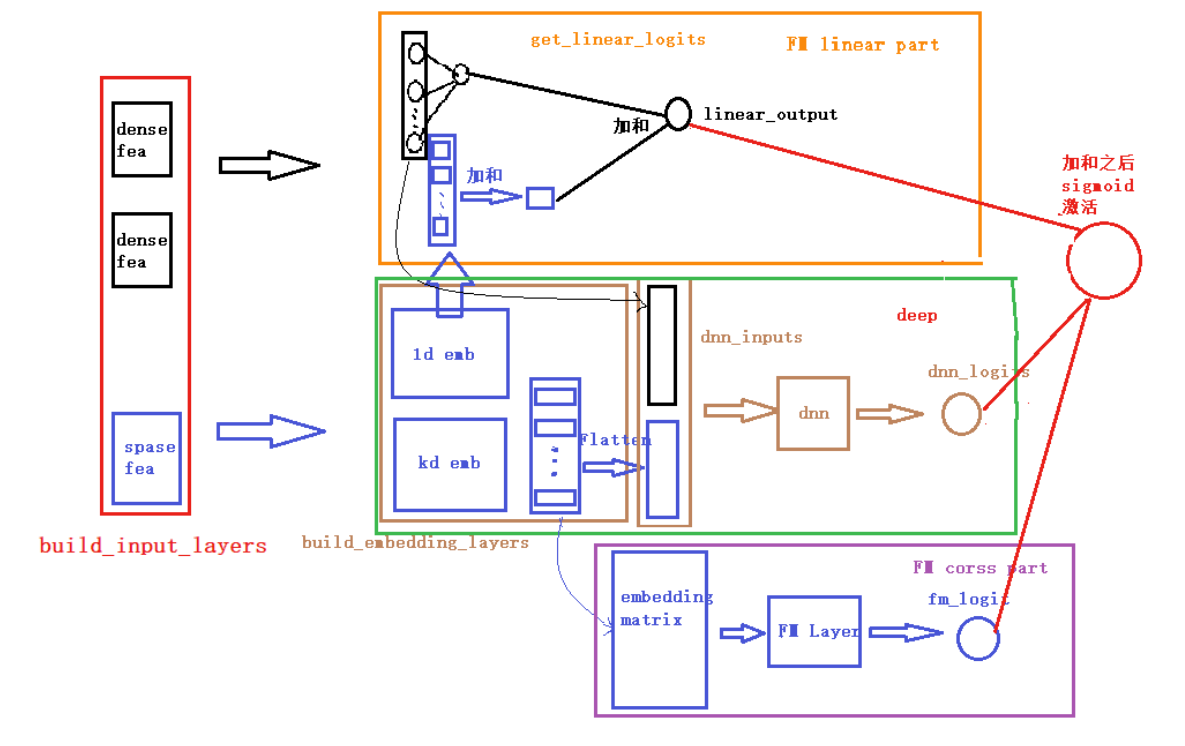
- 整体模型框架:这是一个结合了 FM(Factorization Machine,因子分解机 )和 Wide&Deep 思想的推荐系统模型架构,核心目标是平衡记忆性(Memorization)**和**泛化性(Generalization),常见于 CTR(点击通过率)预测等场景。
- 输入层(build_input_layers)
- 分为稠密特征(dense fea)(如用户年龄、消费金额,数值连续可直接用 )和稀疏特征(sparse fea)(如用户 ID、商品 ID,类别多、维度高 ),是模型的原始数据来源。
- 嵌入层(build_embedding_layers)
- 对稀疏特征做Embedding 处理(1d emb、kd emb ),把高维稀疏的类别特征,压缩成低维稠密的向量(比如百万级用户 ID→几百维向量 ),让模型能 “读懂” 这些特征。
- 处理后生成 “embedding matrix”(嵌入矩阵 ),为后续 FM 和 DNN 提供可用输入。
- Wide 侧(FM linear part + FM cross part)
- FM linear part(橙色框):走简单线性逻辑(get_linear_logits ),直接对特征做线性组合(类似传统 Wide 侧 ),快速捕捉高频、显式的特征关联(比如 “男性用户 + 电子产品” 这类常见组合 ),强化记忆性。
- FM cross part(紫色框):通过 “FM Layer” 自动对 Embedding 后的特征做二阶交叉(比如 “用户性别 Embedding” 和 “商品类型 Embedding” 的内积 ),挖掘特征间的隐藏关联,比手动交叉更高效,同样服务于记忆性(但比线性部分更灵活 )。
- Deep 侧(deep,绿色框)
- 把 Embedding 后的特征(dnn_inputs )丢给 “dnn”(多层神经网络 ),让模型挖掘高阶、复杂的特征关联(比如 “年轻用户 + 户外商品”→“露营装备偏好” ),探索没见过的新组合,强化泛化性。
- 输出层
- Wide 侧的 “linear_output”(线性输出 )、FM cross part 的 “fm_logits”(FM 交叉输出 )、Deep 侧的 “dnn_logits”(DNN 输出 )三者汇总后,通过 “sigmoid 激活” 输出预测概率(比如用户点击 likelihood )。
- 核心逻辑:记忆与泛化的平衡
- 记忆性:靠 FM linear(抓高频显式组合 )和 FM cross(抓二阶隐含组合 )实现,让模型记住历史数据里的规律。
- 泛化性:靠 Deep 侧的 DNN 实现,让模型探索没见过的新特征关联。
- 这样设计能同时覆盖 “老用户高频行为”(记忆 )和 “新用户 / 新场景的潜在需求”(泛化 ),提升推荐效果。
简单说,这模型是 “Wide&Deep + FM” 的进阶版:用 FM 替代 / 增强传统 Wide 侧,既保留线性部分的高效,又靠 FM 自动交叉挖掘更多特征关联;同时用 DNN 兜底泛化性,最终融合多路径结果做预测,在推荐系统里很实用~
文章正文如下,需要反复理解阅读:
2.4 序列模型
DIN:Deep Interest Network(DIIN)是2018年阿里巴巴提出来的模型, 该模型基于业务的观察,从实际应用的角度进行改进,相比于之前很多“学术风”的深度模型, 该模型更加具有业务气息。
这个模型的使用场景是非常注重用户的历史行为特征(历史购买过的商品或者类别信息)。
特征表示
工业上的CTR预测数据集一般都是multi-group categorial form的形式。
基线模型
基准模型的结构相对比较简单,我们前面也一直用这个基准, 分为三大模块:Embedding layer,Pooling & Concat layer和MLP, 结构如下:
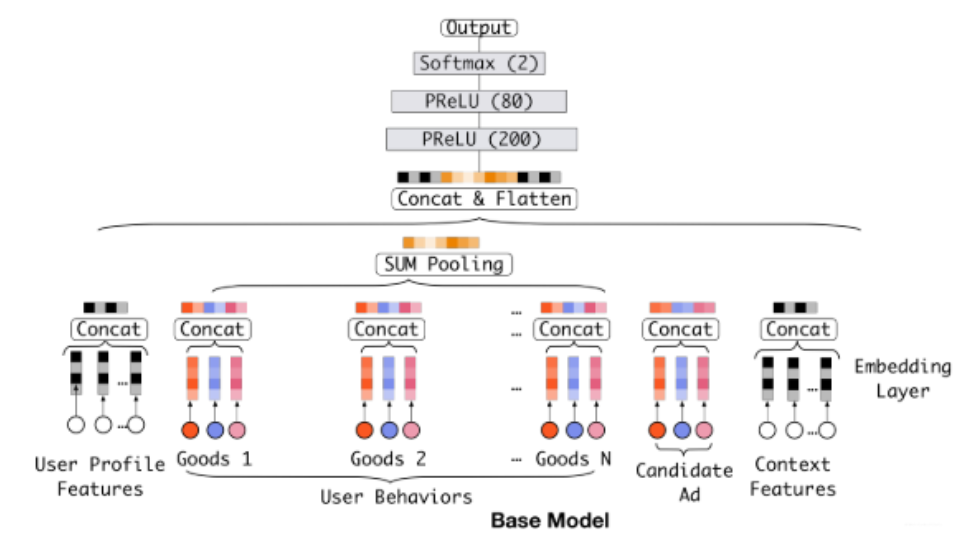
Embedding layer:这个层的作用是把高维稀疏的输入转成低维稠密向量。
pooling layer and Concat layer: pooling层的作用是将用户的历史行为embedding这个最终变成一个定长的向量。
MLP:这个就是普通的全连接,用了学习特征之间的各种交互。
DIN模型架构
相较于基线模型能够根据用户历史行为特征和当前广告的相关性给用户历史行为特征embedding进行加权
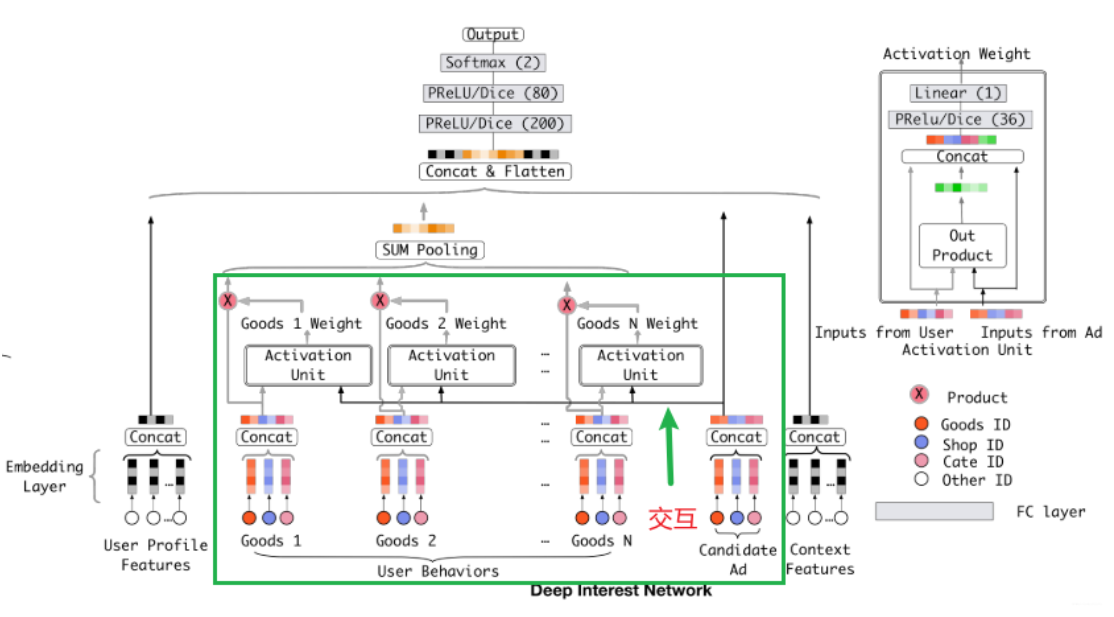
DIN实现
DIN模型的输入特征大致上分为了三类: Dense(连续型), Sparse(离散型), VarlenSparse(变长离散型)
上面三种分类不同的处理方式:
- Dense型特征:由于是数值型了,这里为每个这样的特征建立Input层接收这种输入, 然后拼接起来先放着,等离散的那边处理好之后,和离散的拼接起来进DNN
- Sparse型特征,为离散型特征建立Input层接收输入,然后需要先通过embedding层转成低维稠密向量,然后拼接起来放着,等变长离散那边处理好之后, 一块拼起来进DNN, 但是这里面要注意有个特征的embedding向量还得拿出来用,就是候选商品的embedding向量,这个还得和后面的计算相关性,对历史行为序列加权。
- VarlenSparse型特征:这个一般指的用户的历史行为特征,变长数据, 首先会进行padding操作成等长, 然后建立Input层接收输入,然后通过embedding层得到各自历史行为的embedding向量, 拿着这些向量与上面的候选商品embedding向量进入AttentionPoolingLayer去对这些历史行为特征加权合并,最后得到输出。
模型架构图:
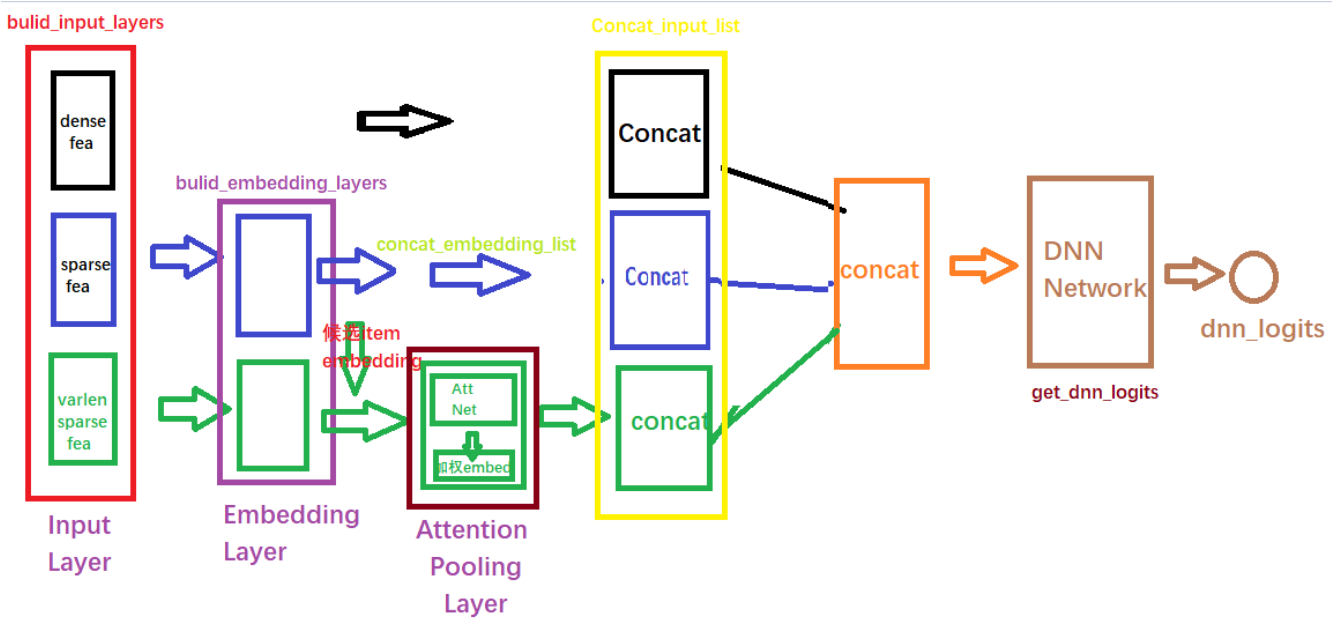
文章正文如下,需要反复理解阅读:
2.5 多任务学习
MMOE模型:MMOE是2018年谷歌提出的,全称是Multi-gate Mixture-of-Experts, 对于多个优化任务,引入了多个专家进行不同的决策和组合,最终完成多目标的预测。
背景:
模型中,如果采用一个网络同时完成多个任务,就可以把这样的网络模型称为多任务模型, 这种模型能在不同任务之间学习共性以及差异性,能够提高建模的质量以及效率。 常见的多任务模型的设计范式大致可以分为三大类:
MMOE模型的理论及论文细节
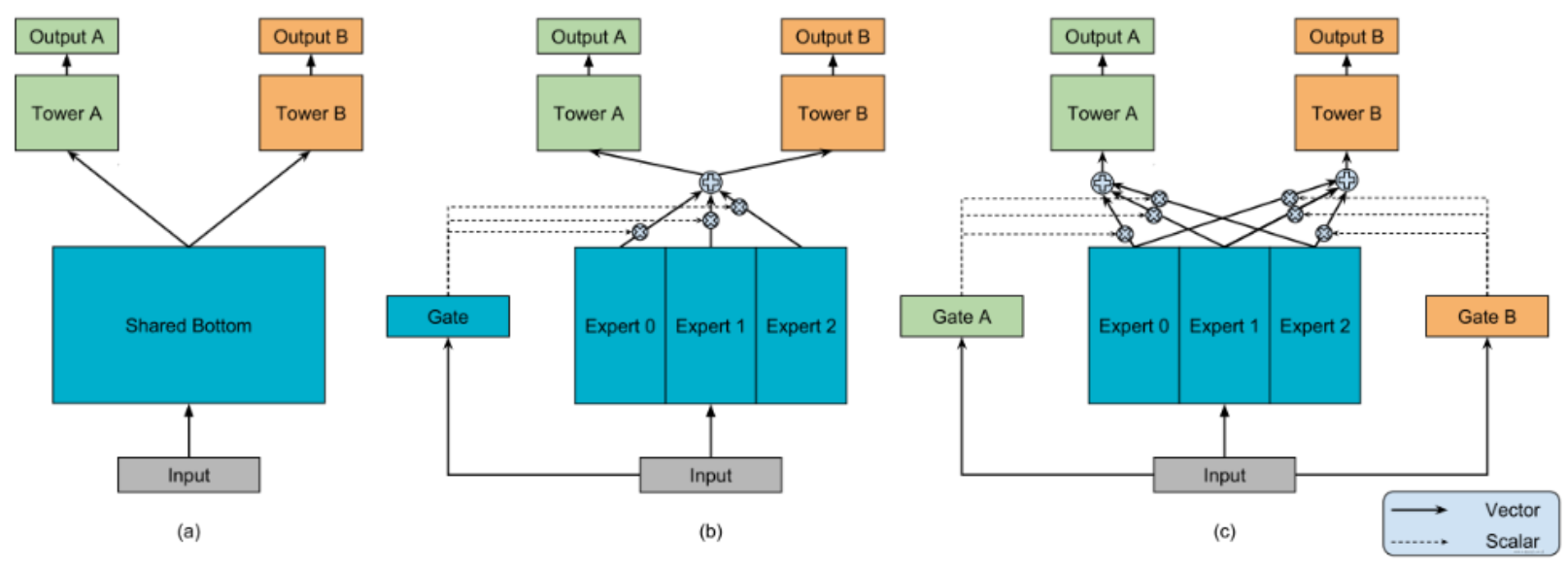
MMOE结构
Multi-gate Mixture-of-Experts(MMOE)的魅力就在于在OMOE的基础上,对于每个任务都会涉及一个门控网络,这样,对于每个特定的任务,都能有一组对应的专家组合去进行预测。
下面用一个场景帮我理解:
🚪大门 + 🧠专家:MMoE 是个啥?
你可以想象一个场景:
👨🏫 有一堆专家(Experts)在等着回答问题,每个专家擅长的方向不太一样。
👩💼 每个任务都有自己的“选门人”(Gate),它来决定该让哪些专家来帮它出主意。
🧠 MMoE 结构步骤:
1️⃣ 先有一堆“专家”(Experts)模块
- 假设我们有 4 个专家,每个专家都是一个小神经网络。
- 每个专家接收同样的输入(比如用户的特征),然后各自做处理。
类比:专家 A 擅长推荐男装,专家 B 擅长推荐女鞋,专家 C 擅长美妆……输入一个用户,每个专家给出一份判断。
2️⃣ 每个任务都有一个“门”(Gate)
- 每个任务会有自己的“门控网络”,根据输入特征来决定该相信哪个专家的建议。
- 门会给每个专家一个权重(比如 0.1、0.4、0.3、0.2),说明你该参考谁多一点。
类比:点击预测任务可能更相信专家 A 和 B,而购买预测任务可能更爱用专家 C 和 D。
3️⃣ 每个任务拿到加权后的输出
- 门控权重 × 每个专家的输出 = 混合专家建议
- 每个任务根据这个加权平均的结果,继续走自己的“任务专属网络”。
🎯 举个具体例子:
比如我们有两个任务:
- 🟢 任务1:点击预测
- 🔵 任务2:购买预测
输入用户信息后:
| 专家 | 输出向量 |
|---|---|
| Expert 1 | [0.1, 0.2] |
| Expert 2 | [0.3, 0.1] |
| Expert 3 | [0.0, 0.4] |
| Expert 4 | [0.2, 0.3] |
然后:
- Gate1(给点击任务)分配权重:
[0.4, 0.3, 0.2, 0.1] - Gate2(给购买任务)分配权重:
[0.1, 0.2, 0.3, 0.4]
最后:
- 点击任务拿的是 4 个专家 * Gate1 的加权和;
- 购买任务拿的是 4 个专家 * Gate2 的加权和。
✅ 总结一句话:
MMoE 就像一个公司里有多个顾问(Experts),每个项目经理(Gate)挑选不同顾问组合来处理自己手上的任务,多任务但不抢人,资源共享又能独立判断。
文章正文如下,需要反复理解阅读:
====文章分界线=*****=*********=============
103 YOLO 全系列教程
1 入门到"真香"的奇妙之旅
You Only Look Once == YOLO
项目简介
本项目主要对YOLO系列模型进行介绍,包括各版本模型的结构,进行的创新、优化、改进等
本课程内容,在传统的DL课程中,大致位于计算机视觉模型里的经典CV模型ResNet等之后,Transformer 等Squential Models 之前的位置
本课程旨在帮助学习者们可以了解和掌握主要YOLO系列模型的发展脉络,以期在各自的应用领域可以进一步创新并在自己的任务上达到较好的效果。
YOLO MASTER 开课计划 0616-0708
项目受众
- 本课程面向有一定的机器学习基础的,上过Deep Learning和图像图形学课程的学生、工程师或者研究者
- 应用领域为基于YOLO的目标检测、图像分类、图像分割、姿态检测和目标跟踪(如 ultralytics 实操 )
- 将YOLO系列模型应用到所在领域数据或者提高表现(Hacking) 的工程师,研究者
- 期待手动实现YOLO算法(From Scratch) 的学习者,
2 yolov系列的发展历程
Task2 笔记:
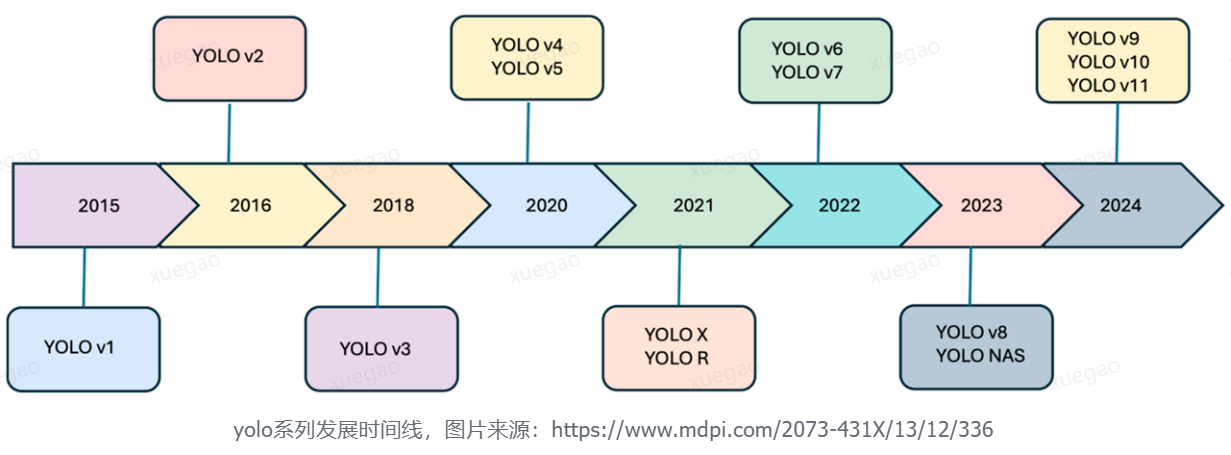
YOLO(You Only Look Once)是一种流行的物体检测和图像分割模型,由华盛顿大学的约瑟夫-雷德蒙(Joseph Redmon)和阿里-法哈迪(Ali Farhadi)开发。YOLO 于 2015 年推出,因其高速度和高精确度而迅速受到欢迎。
- 2016 年发布的YOLOv2 通过纳入批量归一化、锚框和维度集群改进了原始模型。
- 2018 年推出的YOLOv3 使用更高效的骨干网络、多锚和空间金字塔池进一步增强了模型的性能。
- YOLOv4于 2020 年发布,引入了 Mosaic数据增强、新的无锚检测头和新的损失函数等创新技术。
- YOLOv5进一步提高了模型的性能,并增加了超参数优化、集成实验跟踪和自动导出为常用导出格式等新功能。
- YOLOv6于 2022 年由美团开源,目前已用于该公司的许多自主配送机器人。
- YOLOv7增加了额外的任务,如 COCO 关键点数据集的姿势估计。
- YOLOv8Ultralytics YOLOv8 引入了新的功能和改进,以提高性能、灵活性和效率,支持全方位的视觉人工智能任务、
- YOLOv9引入了可编程梯度信息 (PGI) 和广义高效层聚合网络 (GELAN) 等创新方法。
- YOLOv10是由清华大学的研究人员使用该软件包创建的。 UltralyticsPython 软件包创建的。该版本通过引入端到端头(End-to-End head),消除了非最大抑制(NMS)要求,实现了实时目标检测的进步。
- YOLO11 Ultralytics的YOLO 12模型可在物体检测、分割、姿态估计、跟踪和分类等多项任务中提供最先进的 (SOTA) 性能,充分利用了各种人工智能应用和领域的能力。
- YOLO12 🚀新消息:引入了Attention机制,通过区域注意机制(Area Attention)和剩余效率层聚合网络(R-ELAN),YOLO12在保持实时性的同时,显著提升了性能和效率。
从发布频率来看:
- YOLO之父发布了3次(YOLOv1、YOLOv2、YOLOv3)
- Ultralytics 公司有点像YOLO的官方发布机构。它发布了3次(YOLOv5、YOLOv8和YOLO11)
- 台湾Chien-Yao Wang团队参与了3次(YOLOv4、YOLOv7、YOLOv9)
- 中国美团公司参与了1次(YOLOv6),中国清华大学参与了1次(YOLOv10)
- 美国纽约州立大学布法罗分校和中国科学院大学联合参与了1次(YOLO12)
3 YOLO系列算法原理之IoU总结
Task3笔记:课件链接
(一)IoU 是干什么的?
- 专业定义:衡量两个区域重叠程度的指标,用于目标检测中评估预测框和真实框的匹配度
- 大白话比喻:
好比用 “贴纸” 来比喻:真实框是物体本身的轮廓贴纸,预测框是模型贴上去的贴纸。IoU 就是计算这两张贴纸重叠部分占总覆盖面积的比例。
(二)IoU 的数值怎么看?
- 数值范围:0 到 1 之间([0,1])
- 比喻说明:
- IoU=1:两张贴纸完全重合,模型完美预测了物体位置(像用模板精准剪出的贴纸,严丝合缝)。
- IoU=0:两张贴纸毫无重叠,模型完全没预测到物体位置(像把贴纸贴在了完全无关的地方)。
(三)IoU 怎么计算?
- 数学逻辑:IoU=并集面积 交集面积
- 计算步骤拆解(附比喻):
- 确定交集坐标
- 左上角:取两框左上坐标的较大值(比如左边贴纸左上角在 (2,3),右边贴纸在 (5,4),则交集左上角从 (5,4) 开始)。
- 右下角:取两框右下坐标的较小值(比如左边贴纸右下角在 (10,8),右边在 (9,7),则交集右下角到 (9,7) 结束)。
比喻:像找两个贴纸重叠的 “最小包围圈”,先确定左上角的 “右边界” 和 “下边界”,再确定右下角的 “左边界” 和 “上边界”。
- 计算面积
- 交集面积:用上面确定的坐标算出重叠部分的面积。
- 并集面积:两张贴纸的总面积减去重叠部分(避免重复计算)。
比喻:交集面积是 “两张贴纸重叠的部分”,并集面积是 “两张贴纸总共覆盖的区域”,IoU 就是 “重叠部分占总面积的比例”。
- 确定交集坐标
(四)GIoU 是什么
是对 IoU 的增强版,用来解决“两个框没交集时 IoU 无法训练”的问题。
GIoU 是在 IoU 基础上加了“空间意识”,能解决 IoU 无法训练非重叠框的问题,是更强的定位指标,常用于目标检测 Loss,后续还有 DIoU 和 CIoU 可进一步优化。
作用:
因为我们训练 AI 模型时,不是只想知道“中了没”,
我们更希望它学会“怎么从偏的状态慢慢对齐目标”。
GIoU 就是这种“带方向感”的评价标准。
(五)DIoU
DIoU = IoU - 中心点距离惩罚项
它在 GIoU 的基础上,不再只看面积,还看两个框的中心点之间的距离。
现在裁判(GIoU)说:“嗯...你扔歪了,但你离框不算太远,我给你个中评。”
但 DIoU 上场后说:
“等会儿,我不光看你有没有砸中,
我盯着你手里球和篮筐的中心对不对齐!”“你偏左?我扣分!偏远?我更狠扣!”
DIoU 和 GIoU 的区别(类比好记!)
| 比喻 | GIoU | DIoU |
|---|---|---|
| 裁判角色 | 看你“投没中 + 距离外框有多远” | 直接看你“球心离筐心多远” |
| 惩罚对象 | 框之间的空白面积 | 框之间的中心点距离 |
| 收敛效果 | 还行 | 更快、更准! |
| 精度提升 | 中等 | 明显!尤其在训练前期 |
(六)CIoU
CIoU = IoU - 距离惩罚项 - 长宽惩罚项
🏀 篮球场故事继续升级!
- IoU 说:“你投进了吗?”
- GIoU 说:“你没投进?我看看你离框多远。”
- DIoU 说:“我不光看距离,我看球心离筐心远不远。”
- 💡CIoU 登场说:
“你砸中了是好事,但我得看看你这球扔得方向对不对、力度正不正、球型是不是跟篮筐搭!”
它考虑:
- 你中心点对没对齐?(像 DIoU)✅
- 你扔的球是不是太长太扁?跟篮筐像不像?🎯
- 你重叠面积够不够大?📦
🧩 类比总结(“三个标准的裁判”)
| 裁判 | 只看有没有命中 | 看位置偏移 | 看形状贴合度 |
|---|---|---|---|
| IoU | ✅ | ❌ | ❌ |
| GIoU | ✅ | ✅(面积) | ❌ |
| DIoU | ✅ | ✅(中心) | ❌ |
| CIoU | ✅ | ✅(中心) | ✅(形状) |
(七)EIoU:增强版 IoU
🧠 正式解释
EIoU = IoU - 中心点距离 - 宽度偏差 - 高度偏差
它把 CIoU 的“形状惩罚”进一步拆开细看,分别计算:
- 中心点距离差
- 宽度差距
- 高度差距
$$
\text{EIoU} = \text{IoU} - \frac{\rho^2(b, b{gt})}{c2} - \frac{(w - w_{gt})2}{w_c2} - \frac{(h - h_{gt})2}{h_c2}
$$
你不只告诉 AI:“框画错了!”
你得告诉它:“你画偏了 X 米,宽度多了 Y,身高少了 Z。”
它不像 CIoU 只说“你形状差”,而是更具体地指出:“你哪儿差”。
🧠 一句话总结:
EIoU 就是“老师讲评错题时不仅告诉你错了,还标注错在哪个步骤上”的版本!
(八)SIoU:带“方向意识”的 IoU
🧠 正式解释
SIoU = IoU - 角度惩罚 - 距离惩罚 - 形状惩罚
它的关键新特性:引入“角度惩罚”(Angle cost)
比如预测框偏得很奇怪,角度方向离得很离谱,会被重点扣分
类似“你写作业不光写错了,你错得还特别偏门”
投篮时,如果你往天花板扔球、往地上砸,SIoU 会立刻提醒:
“兄弟,你角度根本不对,先调整方向!”
它考虑:
- 中心点偏不偏(位置)✅
- 框的长宽像不像(形状)✅
- 你的框是朝哪个方向偏的(角度)🔥
🧠 一句话总结:
SIoU 是“会看你投篮方向的教练”,角度错得离谱,它就不忍了,直接惩罚你!
4 YOLO系列算法的基本原理与网络结构
1 YOLO框架
概念太复杂,这里作为类比想象你是一个快递分拣员:
- Backbone:拆开包裹,快速扫描物品形状(特征提取)
- Neck:把小件、中件、大件包裹分层摆放(多尺度融合)
- Head:根据大小贴标签,分到对应区域(分类+定位)
实际效果:一张图输入 → Backbone榨汁 → Neck调匀 → Head输出检测结果(框+类别+概率)
这样设计的好处是:分工明确、效率高,适合实时检测(比如YOLO名字的含义"You Only Look Once")!
上面所述均以yolo 11为例,具体到早期版本大框架不会变,但是细节实现会有一些变化。
2 各版本特征融合演进
| 版本 | 特征融合方法 | 方向 | 核心创新点 |
|---|---|---|---|
| YOLOv6 | RepBi-PAN | 双向(显式) | 重参数化优化计算效率 |
| YOLOv7 | 动态FPN+PAN | 双向(动态加权) | 动态卷积权重分配 |
| YOLOv8 | PAN-FPN+SPPF+注意力 | 双向(高效) | 简化连接与梯度优化 |
| YOLOv9 | BiFPN+Transformer | 双向(注意力增强) | Transformer上下文建模 |
| YOLOv10 | Dual-PAN | 解耦双向 | 分离语义与位置特征流 |
| YOLOv11 | C2PSA(隐式双向) | 隐式双向(注意力驱动) | 通道分割与多尺度注意力 |
⭐FPN的核心是自上而下的特征金字塔(高层特征上采样后与低层融合),而YOLOv2的passthrough仅是简单拼接,缺乏层级化的语义传递。
各版本的特征融合方法:
- V1:无明确的特征融合结构,主要基于卷积层和全连接层。
- V2:首次引入FPN(特征金字塔网络)(自上而下)
- V3:结合SPP、FPN和PAN,开始双向融合。
- V4:使用FPN+PAN,双向融合。
- V5:继续使用FPN+PAN,并加入C3和SPP模块。
- V8:在FPN-PAN基础上改进,增加浅层特征利用,引入BiFPN。
- V11(来自):可能使用类似PANet的结构,但具体细节较少,可能延续了之前的双向融合方法。
3 YOLO网络的“套路核心”:特征融合方式
FPN:自上而下,语义从深层传浅层;
PAN:自下而上,细节从浅层补深层;
后面版本都在这个基础上升级,比如:
- YOLOv6:用了RepBi-PAN
- YOLOv8:用了BiFPN
- YOLOv10:语义和位置分两路
- YOLOv11:引入注意力特征融合(C2PSA)
4 常用算法模块
- NMS(非极大值抑制):多个框里选最靠谱那个,避免重叠太多。
- IoU / GIoU / CIoU / DIoU:衡量预测框和真实框重合度的指标,越往后越“智能”。
- Loss函数:从MSE、IoU到DFL,各种损失函数帮助模型更准地画框。
文章正文如下,需要反复理解阅读:
5 YOLO系列模型算法中的LOSS
🧠 一句话总结
YOLO的“损失函数”就是模型判断“预测准不准”的标准,从最早的简单“扣分规则”MSE,到后来的各种花里胡哨的组合(如CIoU、DFL、VFL等),一路变聪明、变复杂、变实用。
🧩 核心概念
1. BCE(二元交叉熵)
- 是什么? 常见的分类损失,用于判断分类预测和真值是否一致。
- 大白话: 如果你预测某图是猫的概率为0.9,但其实它是狗,那就“扣你分”——预测越离谱,扣分越狠。
2. DFL(分布式焦点损失)
- 是什么? 用概率分布来表示边界,而不是单一值。
- 大白话: 检测目标边缘模糊怎么办?那我就别死磕一个点,而是学会“目标在哪附近的可能性”。
3. CIoU、GIoU、DIoU、SIoU(边界框的对比)
- 是什么? 用于判断预测框和真实框的“重合程度”。
- 大白话: 模型画框抓猫,框画得越准、跟猫越贴边,分就越高。
4. VFL(变焦损失)
- 是什么? 一种改进版分类损失,考虑了IOU置信度。
- 大白话: 猫图预测得准了(框画得好、分类也对),才给你打高分;要不然你就别得高分。
🧱 各版本 YOLO 的 Loss 演进史(浓缩版)
| 版本 | Loss 特色 | 大白话点评 |
|---|---|---|
| YOLOv1 | 用 MSE 计算框+分类误差 | 太简单了,把框和类别当一样处理,容易翻车 |
| YOLOv2 | 加了 anchor 框 & noobj 策略 | 检测不到目标也“管你分”,更严格了 |
| YOLOv3 | 改用 BCE 损失,更科学了 | 分类和置信度更靠谱了 |
| YOLOv4 | bbox 回归改为 CIoU | 框画得不准?分数降! |
| YOLOv5 | 加权不同目标尺寸 | 小目标更吃香,大目标少扣分 |
| YOLOv6 | 用 VFL、GIoU/SIoU + DFL | 精准得有“尺度”,还要有“模糊感” |
| YOLOv7 | 和 v5 类似,没创新 | 按部就班地优秀 |
| YOLOv8 | BCE + CIoU + DFL | 多元结合,表现稳定 |
| YOLOv9 | 跟 v7 类似,偏保守 | 不求创新,只求稳定 |
| YOLOv10 | 加入解耦头 + TaskAlignedAssigner | 回归和分类分开算,思路更清晰 |
| YOLOv11 | 跟 v10几乎一样 | 微调优化版 |
| YOLOv12 | 用 Box Loss + DFL | 比较新,细节不全但整体类似 YOLOv8 |
✨总结一句话
YOLO的Loss从“用锤子敲钉子”到“用精密螺丝刀”——越来越知道该怎么“合理打分”,让模型学得更快、识别更准,特别是对边界模糊的小目标,也越来越“人性化”。
文章正文如下,需要反复理解阅读:
====文章分界线=*****=*********=============
200 MCP相关
201 MCP技术开发入门实战
本地代码:地址
201.1 Agent回顾
Agent由四个部分组成:
Tools模块:负责让大模型连接外部工具;
Planning模块:负责规划大模型的行动;
Action模块:负责管理大模型行动的基本流程;
Memory模块:负责管理大模型对话时的记忆;
201.2 MCP在Agent中的作用
MCP统一Tools模块
201.3 MCP中的Client开发流程
1 UV工具
MCP官方推荐使用uv虚拟环境,类似conda环境;
1.1 uv安装
方法1:使用pip安装
pip install uv方法2:使用curl直接安装
curl -LsSf http://astral.sh/uv/install.sh | sh方法3:windows系统安装uv github地址
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
set Path=C:\Users\GaoYuan\.local\bin;%Path% (cmd)
$env:Path = "C:\Users\GaoYuan\.local\bin;$env:Path" (powershell)2 创建MCP客户端
2.1 创建MCP客户端项目
uv init mcp-client
cd mcp-client2.2 创建虚拟环境
# 创建环境
uv venv
# 激活环境
.venv\Scripts\activate
激活前:
(D:\00Program\miniconda3\datawhale_env) PS D:\306Datawhale\mcp\mcp-server>
激活后:
(D:\00Program\miniconda3\datawhale_env) (mcp-client) PS D:\306Datawhale\mcp\mcp-server>
#安装MCP SDK
uv add mcp
# 执行
uv run client.py安装完成效果:
warning: Failed to hardlink files; falling back to full copy. This may lead to degraded performance.
If the cache and target directories are on different filesystems, hardlinking may not be supported.
If this is intentional, set `export UV_LINK_MODE=copy` or use `--link-mode=copy` to suppress this warning.
Installed 21 packages in 370ms
+ annotated-types==0.7.0
+ anyio==4.9.0
+ certifi==2025.1.31
+ click==8.1.8
+ colorama==0.4.6
+ h11==0.14.0
+ httpcore==1.0.7
+ httpx==0.28.1
+ httpx-sse==0.4.0
+ idna==3.10
+ mcp==1.6.0
+ pydantic==2.11.1
+ pydantic-core==2.33.0
+ pydantic-settings==2.8.1
+ python-dotenv==1.1.0
+ sniffio==1.3.1
+ sse-starlette==2.2.1
+ starlette==0.46.1
+ typing-extensions==4.13.0
+ typing-inspection==0.4.0
+ uvicorn==0.34.02.3 新增接入OpenAI、DeepSeek
1 新增依赖
uv add mcp openai python-dotenv
(mcp-client) D:\306Datawhale\mcp-client>uv add mcp openai python-dotenv2 创建env环境
接下来创建.env文件,并写入OpenAI的API-Key,以及反向代理地址。借助反向代理,国内可以无门槛直连OpenAI官方服务器,并调用官方API。
BASE_URL="反向代理地址"
MODEL=gpt-4o
OPENAI_API_KEY="OpenAI-API-Key"201.4 服务端开发
1 服务器依赖安装
http请求天气:
uv add mcp httpx201.5 MCP Inspector功能介绍
在实际开发MCP服务器的过程中,Anthropic提供了一个非常便捷的debug工具:Inspector。借助Inspector,我们能够非常快捷的调用各类server,并测试其功能。Inspector具体功能实现流程如下。
- 安装nodejs
curl -fsSL https://deb.nodesource.com/setup_20.x | sudo bash -
sudo apt install -y nodejs
npx -v- 运行Inspector
npx -y @modelcontextprotocol/inspector uv run server.py然后即可在本地浏览器查看当前工具运行情况:http://127.0.0.1:5173/#resources
201.6 Cline 和 Cursor 如何配置 MCP
2.6.1使用fetch生成科技日报 Cursor
Screentime(屏幕时间)
这些新闻反映了当前科技行业的主要趋势,包括AI发展、
帮我整理一个科技日报,参考模板:
事件
实践内容或主要功能(一句话描述内容,或者列举最多3个点)
详情:url地址202 吴恩达MCP讲义
做一个课程
飞书链接:https://fg3l4eddfw.feishu.cn/docx/XeoUddaN6ovkqyxpavEcWreGnDc?from=from_copylink
有下面的内容:
中文翻译这一篇学习材料,让AI
加入在windons mac 系统
加入trae工具编程
加入python java编程
用户身份验证
202 MCP实战
MCP 官方教程:https://modelcontextprotocol.io/quickstart/client
.venv\Scripts\activate
uv add mcp openai python-dotenv
OS/Liunx:
touch client.py
touch .env
windows:
ni client.py
ni .env
echo ".env" >> .gitignore
# 创建天气服务:
uv init weather
uv venv wether_env
source ./wether_env/Scripts/activate
.\wether_env\Scripts\activate.ps1====文章分界线=*****=*********=============
300 n8n
是什么
n8n 是一款开源、自由可控的工作流自动化神器。它采用“公平代码”许可,允许用户自由查看、修改和分发源代码。名字源自 nodemation(节点自动化),核心就是用“节点+连线”方式,把各种应用和服务串联起来,帮你轻松实现数据搬运、流程跑通、业务自动化。
300.1 传统项目解释
1、能做什么
🔄 跨应用数据同步与处理
比如,从数据库取数据 ➡️ 自动生成 Excel ➡️ 邮件群发。
或者,CRM 有新客户 ➡️ 自动在营销平台建档 ➡️ 发送欢迎邮件,全程不用动手。
🕰️ 定时任务与计划作业
想每天凌晨抓取各渠道数据?每周五生成报表发给老板?用 Cron 节点一键搞定,还能设置资源监控,异常时自动触发脚本处理。
📝 业务审批流程自动化
员工报销、请假?n8n 自动帮你判断金额大小、走不同审批流,合理的自动批准,超额的自动加审,还能同步更新到日历和系统。
🚨 异常监控与智能告警
定时检查系统、接口是否正常,一旦宕机或数据异常,立刻通过邮件、Slack、微信等多渠道提醒;还能监控安全日志,发现风险即时响应。
💬 客户服务自动化
客户来咨询?n8n 根据内容和历史记录,自动把客户派给最合适的客服,让服务又快又准。
2、n8n 与其他工具的对比
- n8n和Coze、Dify比较
| n8n | Coze | Dify | |
|---|---|---|---|
| 核心定位 | 通用工作流自动化中枢 | 轻量零代码应用搭建 | 大语言模型应用平台 |
| 适合场景 | 跨系统集成、复杂业务流程 | 快速原型开发、小应用 | 构建 AI 聊天、智能客服等 |
| 技术要求 | 适合懂一点 JS/Python 的人 | 零代码,面向非技术用户 | 主打低/零代码 |
| 部署方式 | 支持自托管、本地或云 | 云端为主 | 云端为主,企业版可私有部署 |
| 成本 | 开源免费,可自托管零成本 | 云服务费用 | 按 Token 使用量计费 |
| 集成生态 | SaaS、数据库、API 全覆盖 | 主要是轻应用内部集成 | 聚焦 AI 模型集成 |
- 那和 Zapier、Make 这些自动化工具比呢?
- 灵活性爆棚:开源可改,想连啥连啥,想怎么改怎么改,自由度远超 Zapier、Make。
- 成本超级友好:自己托管?0元!不必担心用量一高,订阅费就飞天。
- 集成潜力无限:Zapier 集成多(5000+),但 n8n 可以自己写节点、接任何 API,天花板更高,越用越香。
300.2 安装N8N
1、本地快速安装(适合体验)
用 npm 安装(适合开发者)
bash复制编辑npm install n8n -g
n8n直接全局安装,一行命令起飞!启动后浏览器访问 http://localhost:5678。
✅ 适合快速试水
⚠️ 生产环境不推荐直接 npm 起服务。
2、Docker 安装(最常用!适合自托管)
用 Docker Run安装,快速;前提是需要安装Docker Desktop
bash复制编辑docker run -it --rm \
-p 5678:5678 \
n8nio/n8n一条命令跑起来,容器版又干净又方便!
注意:在同一台机器上npm和docker安装的数据环境是不通的;
3、用 Docker Compose (推荐生产环境)
✅ 写个 docker-compose.yml 文件,管理起来更丝滑:
version: "3"
services:
n8n:
image: n8nio/n8n
restart: always
ports:
- "5678:5678"
# environment: 新版本没有作用
# - N8N_BASIC_AUTH_ACTIVE=true
# - N8N_BASIC_AUTH_USER=admin
# - N8N_BASIC_AUTH_PASSWORD=yourpassword
volumes:
- ~/.n8n:/home/node/.n8n # C:\Users\你的用户名\.n8n然后运行:
bash
复制编辑
docker-compose -f n8n-docker-compose.yml up -d
# 将文件命令为 n8n-docker-compose.yml 的使用方式,如果命名为 docker-compose.yml使用[docker-compose up -d]命令即可✅ 支持账号密码登录
✅ 自动挂载数据,重启不丢工作流
✅ 一键停止 n8n
在你的项目目录(x:\yyyy\n8n)里打开终端,敲:
bash
复制编辑
docker-compose -f n8n-docker-compose.yml down💬 作用:
- 停止并删除容器
- 保留你的数据(因为数据挂载在
./n8n_data目录)
bash
复制编辑
docker-compose -f n8n-docker-compose.yml down --volumes💬 作用:
- 移除数据卷
✅ 一键更新 n8n 镜像 + 重新启动
如果官方发布了新版本,你想升级 n8n,敲这两步:
bash复制编辑
docker-compose -f n8n-docker-compose.yml pull
bash 先停止在重启
docker-compose -f n8n-docker-compose.yml down
docker-compose -f n8n-docker-compose.yml up -d
bash 重启命令
docker-compose -f n8n-docker-compose.yml restart4、云端部署(如果不想自己搞服务器)
- n8n 官方也提供了 n8n.cloud,一键注册,省心省力,就是要付费。
- 也可以自己买台云服务器(比如阿里云、腾讯云、AWS、Vultr),用 Docker 部署,很香。
5、总结
| 方法 | 适合人群 | 特点 |
|---|---|---|
| npm 本地安装 | 想本地玩玩 | 快速、简单 |
| Docker Run | 想临时测试 | 快捷、无残留 |
| Docker Compose | 长期自托管 | 稳定、可持久化 |
| 官方云服务 | 不想自己折腾 | 省心,但要花钱 |
300.3 登录n8n
使用docker-compose启动
http://127.0.0.1:5678 第一次登录需要输入邮箱和密码,回到n8n的云里面注册;
300.4 实战
1、n8n+crawl4ai工作流,一键抓取任意网站
1.1 安装crawl4ai
参考:https://github.com/unclecode/crawl4ai
# 拉群镜像
docker pull unclecode/crawl4ai
# 启动镜像
docker run --rm -it -e CRAWL4AI_API_TOKEN=12345 -p 11235:11235 unclecode/crawl4ai启动成功:
(base) PS C:\Users\xxx> docker run --rm -it -e CRAWL4AI_API_TOKEN=12345 -p 11235:11235 unclecode/crawl4ai
2025-04-29 04:45:44,361 INFO supervisord started with pid 1
2025-04-29 04:45:45,367 INFO spawned: 'redis' with pid 7
2025-04-29 04:45:45,371 INFO spawned: 'gunicorn' with pid 8
7:C 29 Apr 2025 04:45:45.439 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
7:C 29 Apr 2025 04:45:45.439 # Redis version=7.0.15, bits=64, commit=00000000, modified=0, pid=7, just started
7:C 29 Apr 2025 04:45:45.439 # Configuration loaded
7:M 29 Apr 2025 04:45:45.439 * monotonic clock: POSIX clock_gettime
7:M 29 Apr 2025 04:45:45.443 * Running mode=standalone, port=6379.
7:M 29 Apr 2025 04:45:45.443 # Server initialized
7:M 29 Apr 2025 04:45:45.446 * Ready to accept connections
[2025-04-29 04:45:46 +0000] [8] [INFO] Starting gunicorn 23.0.0
[2025-04-29 04:45:46 +0000] [8] [INFO] Listening at: http://0.0.0.0:11235 (8)
[2025-04-29 04:45:46 +0000] [8] [INFO] Using worker: uvicorn.workers.UvicornWorker
[2025-04-29 04:45:46 +0000] [13] [INFO] Booting worker with pid: 13
2025-04-29 04:45:47,039 INFO success: redis entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
2025-04-29 04:45:47,039 INFO success: gunicorn entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
MCP server running on 0.0.0.0:11235
[2025-04-29 04:45:48 +0000] [13] [INFO] Started server process [13]
[2025-04-29 04:45:48 +0000] [13] [INFO] Waiting for application startup.
[INIT].... → Crawl4AI 0.6.1
[2025-04-29 04:45:49 +0000] [13] [INFO] Application startup complete.Cral4AI本地地址:http://127.0.0.1:11235/playground/
====文章分界线=*****=*********=============
400 AI编程重塑产品设计逻辑-使用trea工具设计产品
今天,咱们手把手用AI来做一个产品。
1️⃣ 会用到 Trae 来协助完成整个过程,从 理解赛题、头脑风暴、用户洞察、功能梳理,到文档撰写、代码对接,
2️⃣ 甚至连 产品介绍和营销文案 都可以一并搞定。
3️⃣ 我们还让模型读懂了我们设计好的界面,只要把 Figma 链接一丢,它就能自动理解并后续继续干活。
详细拆解可以看看我这篇文章:https://mp.weixin.qq.com/s/DmgBAvoHRO1FIRyovQ2reg
小红书工具箱
另外、你还可以使用flowith这种产品帮你快速验证产品想法和demo。
界面展示链接:https://flo.host/njMdn-z/
过去,我们需要根据需求手动撰写大量代码,一步步搭建产品原型;而如今,通过与AI协作,我们只需要用自然语言描述想法,AI就可以辅助生成底层代码、搭建界面、优化交互逻辑。
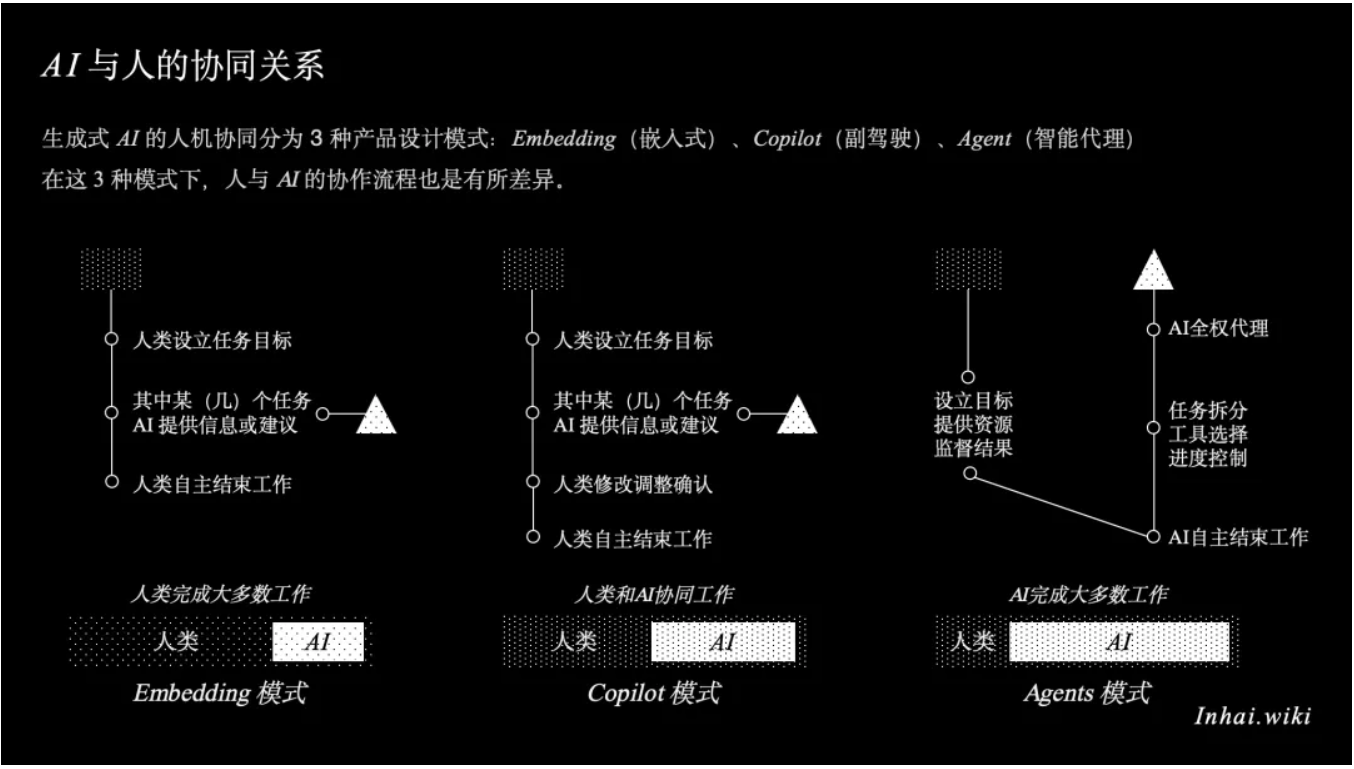
接下来,让我们一起看看,在 AI时代 下, 新的工作流程设计 会呈现出怎样的变化。未来,很多时候我们只需要简单地 口头表达需求 ,比如:
- “帮我完成一份需求文档。”
- “帮我设计一个针对某某主题的访谈提纲。”
- “指导我如何整理用户旅程地图。”
- “我有一个简单的功能需求文档,希望直接通过Vibe Coding的方式,帮我快速生成界面。”
- “帮我完成一个结构完整、视觉专业的PPT。”
这些场景,过去往往需要产品经理、设计师、运营等角色多轮沟通、多轮手动制作,而在AI的加持下,现在 只需一句话的描述 ,系统就可以理解意图、自动完成中间的繁琐环节,直接产出高质量的结果。
可以看到,这样的流程设计,已经 非常接近我们的自然思考方式 了 —— 不再是先写需求文档,再开发,再调整,而是 从想法到成品,几乎无缝衔接 。

一、初步了解
1、先搞清楚我们到底要做啥
拿到项目需求后,让 Trae 帮我们拆解赛题内容 就是一个很好地方式。
它就能帮我们捋清楚逻辑。比如:项目到底要解决什么问题?有没有什么限制条件?评判标准是啥?它能一步步帮我们拆解出来,相当于是先把方向搞明白,别一开始就瞎忙活。
首先,确保赛题的文本不是图片格式,然后保存赛题信息——
- 直接点击“Ctrl+S”直接把赛题的网页信息拿下来,
- 也可以全选复制到markdown文本中
接下来,让Trae读取一下这个项目需求,然后给我们分析一下我们需要参加什么样子的比赛,建议的方向是什么。
💡参考Prompt模版:
我现在有一份需求内容,我希望你能像一位产品策略专家一样帮我逐步拆解它的核心要素。请你按照以下逻辑来分析:
问题定义:这个项目想解决的核心问题是什么?能不能帮我总结成一句话的问题描述?
目标澄清:最终希望达到的结果是什么?目标是产品交付、用户增长,还是解决某个痛点?
评判标准:有没有明确的评分维度或隐含的成功标准?比如技术可行性、商业价值、用户体验等。
约束条件:有没有给出特定的使用范围、时间限制、技术框架或者团队配置要求?
用户视角:从用户角度出发,这个题目服务的核心人群是谁?他们有什么痛点或需求?
帮我用结构化的方式回答,最好每点用简洁直白的语言概括清楚,适合后续直接拿去写 PRD 或进入头脑风暴阶段。这个 Prompt 核心参考了 设计思维(Design Thinking)中的问题定义阶段 ,以及 产品经理常用的 4W1H 框架(What/Why/Who/When/How)
同时也留了很大的空间让 Trae 用自己的知识和分析能力展开拆解。
把这个模板稍微调整一下用在不同题目上,比如补充上下文或加上具体的题干,AI 就能更准确地帮你分析。
2、想点子的时候,别自己瞎琢磨
有了方向,下一步当然是想办法解决问题。
但一个人脑子里蹦出来的点子毕竟有限,有时候还容易陷进去出不来。
让 Trae 帮我们进行头脑风暴**,**把思路说给 Trae 它听,它就能从不同角度帮你发散思维。比如可以从用户需求、技术实现、商业价值这几个方向帮你找灵感,还能顺手把你说的一些模糊点归纳得更清楚。
就像随时有个不累的同事在和你对话。
💡
参考Prompt 模板:帮我发散思路、头脑风暴一下解决方案
接下来我想请你帮我进行一轮头脑风暴,围绕我们已经明确的赛题方向,帮我从不同角度提出一些可能的产品创意或解决思路。
请你尝试从以下几个维度来发散,每个维度列出多个可探索的方向或场景:
用户视角:用户是谁?他们的痛点可能在哪?有没有什么新的使用场景可以挖掘?
技术可行性:基于当前主流的大模型、API、工具,能不能有技术上的新用法或组合?
场景拓展:除了直接解决问题的方案,有没有什么“借力”的方式?比如结合已有平台、已有数据流?
商业与增长:有没有什么设计能兼顾转化率、用户留存、商业模式?
已有方案优化:现在市面上有没有类似解决方案?能不能改造升级、差异化突破?
如果可以,也帮我用一句话总结每个创意背后的核心逻辑。目标不是一步到位,而是尽可能多地打开思路,把盲区点亮。这个 Prompt 的设计,核心参考了几个专业的创意发散模型:
- SCAMPER (替代、组合、调整、放大、缩小、替换、反转)
- 五个维度发散法 (用户、场景、技术、市场、价值)
- 第一性原理思考法 (从问题本质出发推导新路径)
你可以把当前你手头的赛题描述或已有的思路补充进去,效果会更好。
3、搞清楚用户到底在意什么
比如我们通过上面的头脑风暴之后,最终选定了一个“社交媒体内容分析策略师”的场景,那么接下来我们应该去洞察这个场景下用户更在意的点是什么,我们的核心发力点在哪里。
让 Trae 帮我们进行洞察分析—— 如果手上有用户反馈、竞品资料或者数据报告,直接扔给 Trae,它就能帮你分析哪些问题是用户反复提的,哪一类人最常碰到这些问题,还有哪些功能可能会被忽略但其实很关键。它会帮你从这些杂乱信息里捞出有价值的洞察,告诉你应该往哪个方向优化或者创新。
💡Prompt 模板:帮我从用户反馈或竞品资料中提炼出有价值的洞察
我现在有一批资料(包括用户反馈、调研记录、竞品分析报告等等),信息量比较大,也比较杂,我想请你像一个懂产品和用户研究的分析师一样,帮我把这些内容整理出清晰的洞察结果。请从下面这些角度来分析:
高频问题归类:哪些问题或需求是被反复提到的?能不能帮我分成几个主题或类目?
用户群画像:根据提问或反馈的内容,哪些用户群体最关注这些问题?有没有可以细分的人群特征?
潜在痛点挖掘:有没有哪些隐含的问题不是直接被说出来的,但可以从表述中读出背后的需求?
机会点识别:从用户的角度看,有哪些功能是他们觉得不方便、但市面上的竞品也没做好的?我们有没有机会切入?
体验差异化建议:有没有什么需求点是可以作为我们产品的差异化亮点来设计的?
最后,请你用结构化的方式输出这些分析结果,最好能分点呈现,便于我下一步进入功能梳理和产品方案设计阶段。这个 Prompt 参考了用户体验研究和产品洞察中的典型分析结构,例如:
- Affinity Mapping(相似观点归类)
- Jobs to be Done(用户要完成什么任务)
- Pain-Gain Map(痛点与收益分析)
4、功能要怎么设计,让它来帮我们梳理一下
ok,上面我们已经基本清晰了用户的画像和痛点信息,接下来其实主要就是根据这些场景去梳理出咱们的MVP(最小可行产品)的功能模块分别是什么,然后需要有一份清晰的需求清单。
让 Trae 帮我们梳理功能需求
当你有了大概的产品想法或者解决方向,下一步就是把它拆成一个个具体功能。Trae 会根据前面分析的结果,帮你列出“这个产品应该包括哪些功能”“每个功能解决什么问题”“用户是怎么一步步操作的”。这一块它特别擅长,能把我们脑子里模糊的想法变成一条条写得清楚的功能点,给设计和开发用起来也方便。
💡Prompt 模板:帮我把产品想法拆成一份清晰的功能需求清单
我现在有一个初步的产品构想(或者一个明确的目标/场景),我希望你能根据我们前面的分析结果,帮我整理出这个产品应该包含的核心功能。请从下面几个维度来帮我一步步梳理出来:
功能清单:这个产品从“用户第一次使用”到“完成主要任务”应该包括哪些主要功能模块?请列出每一块并简单解释下它是干嘛的。
用户操作路径:站在用户的角度,整个使用过程大概是怎么一步步走下来的?每个功能点出现在哪个环节?
每个功能解决什么问题:帮我对齐一下:每个功能点的设计目的是什么?它具体是在解决哪个用户痛点或需求?
功能之间的逻辑关系:有没有依赖关系、优先级?哪些是核心功能,哪些是辅助功能?
MVP视角收敛:如果我要先做一个最小可用版本(MVP),应该保留哪些功能?可以先放弃哪些?
请把回答整理成结构清晰的段落或表格,方便我直接拿去做 PRD 或和团队沟通设计方案。这个 Prompt 的设计参考了产品规划中的经典方法论:
- 功能-需求映射表(Function vs. Need)
- 用户路径分解(User Journey Mapping)
- MoSCoW 优先级模型(Must, Should, Could, Won’t)
5、写文档这活,也能交给它搞定
让 Trae 生成一份 AI 看得懂的 PRD 文档 现在写 PRD,不光是给人看的,还得让 AI 工具也能读懂。Trae 会根据我们前面聊出来的功能,自动生成一份结构清晰的产品需求文档。里面包括功能说明、用户流程、接口逻辑这些关键点。它写出来的文档逻辑很清楚,拿去跟团队同步,或者对接别的智能工具,都能直接用。
💡参考Prompt 模板:帮我生成一份结构清晰、AI 可读的 PRD 文档
我已经有了产品的基本构想和功能列表,现在想请你帮我整理成一份AI 能看懂也能继续执行的 PRD(产品需求文档)。这份 PRD 不仅要让人看得懂,更要考虑结构的清晰度、格式的规范性,方便后续接入自动化流程或智能工具调用。请按以下结构来输出:
产品背景和目标:简单描述产品要解决什么问题,服务什么场景,核心目标是什么。
核心功能模块列表:列出每个功能模块的名称、功能描述、使用场景,最好补充一句“这个功能解决的问题”。
用户流程图(文字版):从用户视角出发,描述用户从进入产品到完成关键任务的操作路径(可分步骤标序号)。
每个功能的输入/输出:列清楚用户或系统输入了什么、期望的输出结果是什么,适合后续和大模型交互或和 API 对接。
接口需求(如有):说明每个功能点是否需要接口支持,如果需要,说明接口用途、调用方式、数据结构要求。
边界条件和异常处理:列举常见的边界情况和异常场景,说明系统应如何响应。
请按模块清晰排版,内容尽量结构化,避免散乱描述,最好用 Markdown 或表格格式输出,便于后续被其他智能工具或工程团队复用。
最后保存到当前文件夹中,以md格式存储。这个 Prompt 融合了:
- 机器友好型 PRD 写作法 (结构明确、模块分割、数据流清晰)
- 产品六要素 (目标、用户、功能、流程、数据、边界)
- 适用于自动化系统理解的语法习惯 (如 Markdown 表达、字段命名清晰、明确的输入输出分离)
6、让模型知道我们想要的界面长啥样
让模型知道我们想象中的界面长什么样子,使用 Figma MCP 的服务,把 Figma 链接放进去就可以了。
咱们前几天的中已经给大家分享过Figma MCP服务的使用技巧,咱们也可以通过这个文章来回顾一下,有详细的Figma MCP安装教程:https://mp.weixin.qq.com/s/AX0-N3DR4KCdoLb_Ch2XVA
创建完之后,我们把相关的mcp都粘贴进去,主要用到的是figma的mcp服务,配置完成之后,也可以直接看下Trae目前哪些MCP服务是可以用的。
更多mcp服务可以在mcp.so或者modelscope里面找到。
有时候我们脑子里已经有了产品大概的样子,甚至已经在 Figma 上画好页面了,这时候完全可以让模型直接“看图说话”。我们只需要把 Figma 的设计链接丢给它,它就能通过 MCP 服务自动识别页面结构、组件类型、交互关系这些细节。
咱们可以在Figma社区里面找一些公开的图像设计资源,然后喜欢的风格布局等等,当然约接近越好,就好比我们要做一个内容创作工具,我们就去找类似的设计资源,当然很细分的需求也难找到一摸一样的,其实主要看你喜欢什么风格可以直接视觉化的描述即可。
这一步最大的好处是,模型理解界面的方式就跟人一样,知道哪个是按钮、哪个是输入框,知道用户点一下会发生什么。后面你要让它写前端代码,或者生成交互逻辑,就会顺畅很多,省得我们一个个功能再解释一遍。
💡这个参考Prompt提示词很简单:
结合我的figma设计稿链接(https://www.figma.com/design/WXpW4QN4xFIeDVdZ7uqppm/Minimalistic-Social-Media-Templates--Community-?node-id=29-1239&t=fyrkseULN35IUmeL-4),读取我的prd文档,帮我实现这个功能。7、如果要它接入模型能力,那接口文档得准备好
给 Trae 准备好对应的 API 文档 想让它进一步帮我们动手干活,比如调用数据库、调取用户信息,那就得先把 API 文档给它。只要我们把接口说明、参数规则、请求方式写清楚,它就能“学会”怎么调用这些服务,后面可以自动帮我们写代码、拉数据、生成内容,不用我们手动对接每个环节。
以讯飞星火大模型API平台为例,我们去拿到它的大模型API文档,全部贴入到文档里面就好了。
- 把鉴权信息获取到我们的文档中。
- 把接口文档保存到我们的文档中。
接口文档地址:https://www.xfyun.cn/doc/spark/X1ws.html#_1-%E8%AF%B7%E6%B1%82%E5%9C%B0%E5%9D%80
当然了也可以在咱们的星辰MaaS平台中直接调用相关的模型
模型地址:https://training.xfyun.cn/modelService
这里默认的文档用的是“Spark-x1”,如果需要指定模型id,我们“查看详情”页面中可以去拿模型的code信息。当然,如果你实在也不知道该拿一块信息,直接把上面几个页面都全选复制粘贴就好了(也不是不行)...
最后我们会得到这样的一份Markdown文档:
如果有需要,我们直接让Trae去帮我读取一下这个文档就好了,跟上面的方法是一样的,这样就具备了模型的接入能力了!
8*八、前面准备好了,就让它开始上手干活**
让 Trae 开始读取文档帮我们干活 一旦 PRD 和接口都搞定了,就可以让 Trae 正式“上岗”。我们可以直接告诉让它去读取我们的需求文档、API文档,它就能根据文档自动处理,真正把分析、设计、开发串在一起干了。
咱们之前已经直接让它开始干活了,可以看到它已经出了一个基础版本的内容:
咱们也可以来看看最后实现的效果(数字营销场景的案例)
💡点击右侧◀展开查看效果案例
9、产品介绍也不用自己写,交给它就行
**让 Trae 帮我们写产品介绍文档,**我们可以直接根据赛事提交的要求大纲去填充相关内容。

产品做出来了,总得有个对外或对内的介绍材料。这个时候也可以让 Trae 来写,它能根据我们之前的需求文档、用户场景和产品功能,总结成一份像样的介绍内容。不管是给团队成员看,还是用于内部评审,它写出来的内容结构都挺专业的,不啰嗦,重点也很清楚。
💡
Prompt 模板:帮我写一份简洁且专业的产品介绍文档
我现在有一个已经完成的产品,我希望你根据之前的需求文档、用户场景和功能说明,帮我生成一份清晰的产品介绍文档。这个文档的目标是让外部或内部团队快速理解我们产品的核心价值、功能和使用方式。请按照以下结构来写:
产品概述:简短介绍产品是什么,解决什么问题,面向什么样的用户,简洁地传达产品的核心价值。
目标用户群体:说明该产品的主要用户是谁,如何满足他们的需求,为什么它对这些用户有吸引力。
核心功能:列出并简要描述产品的主要功能,每个功能点用一两句话概述它的用途和目标。
使用场景:给出几个典型的用户使用场景或使用流程,帮助理解产品是如何在实际环境中解决问题的。
技术架构和创新点:简要说明产品的技术亮点、创新之处,或是产品的独特技术实现,帮助突出产品的竞争力。
市场定位和竞争优势:分析产品在市场上的定位,以及相对于竞品的优势和差异化。
未来发展和优化方向:简单介绍一下产品的未来发展计划,未来可能的功能拓展或优化方向。
请保持文档结构清晰、重点突出,不啰嗦,语言简洁明了,适合用作内部汇报、外部介绍或者评审材料。10、宣传文案也能一把包了
让 Trae 帮我们搞定产品营销推广文案 产品要推向市场,就得有能打的文案。
这事儿也可以交给 Trae。你告诉它你要发在哪个平台、目标人群是谁,它就能帮你写出贴合场景的宣传内容。
不管是要正式一点的介绍,还是轻松一点的社交媒体文案,它都能根据语气和渠道自动调整风格,不用我们反复改来改去。
💡
Prompt 模板:帮我生成贴合场景的营销推广文案
我现在需要一份针对产品的营销推广文案。请你根据我提供的背景信息和目标,帮我写出适合不同平台发布的文案,确保文案能够吸引目标用户,并在适当的语气和风格上有所调整。以下是文案的要求:
平台:文案将发布在哪些平台?比如官网、微博、微信公众号、抖音、小红书等。根据平台特点,调整文案风格和语气。
目标受众:我的目标用户是谁?他们的需求、兴趣、痛点是什么?(比如年轻人、企业管理者、技术人员等)
文案类型:你需要写哪种类型的文案?
正式的介绍文案:适合官网、产品手册、企业宣传等正式场合。
轻松的社交媒体文案:适合微博、朋友圈、短视频平台等互动性较强的渠道。
核心卖点:产品的哪些功能或优势最值得突出?(例如节省时间、提高效率、降低成本、创新性强等)
号召性用语(CTA):希望用户看到文案后采取什么行动?例如点击购买、注册体验、了解更多等。
请根据这些要求生成文案,确保不同平台和受众有相应的风格变化。如果能提供多个版本(例如短版和长版),就更好了。这个 Prompt 的设计参考了 文案创作中的多渠道策略 和 用户画像驱动的个性化营销 ,并通过不同的语气调整来确保文案符合发布平台的特点。
备注:
二、实战进阶
AI应用开发的核心在于充分挖掘大模型的内在潜能
以下策略为常见的AI应用开发策略,我们也将和大家一起持续收集和分享相关最佳实践。
还可以看看 官方文档(点击跳转),有很多阿里云百炼平台的使用说明和应用API参考示例代码
另外、大家也可以学习一下阿里云计缘老师分享的《AI应用开发新范式》:
优化项目效果的有四种核心方式
大模型时代的应用开发范式——应用设计 + 挖掘模型能力
进入大模型时代,人工智能领域的边界正以前所未有的速度扩展,而 **如何充分挖掘大模型的内在潜能** ,成为了应用开发者面前的一道关键课题。
在这一背景下,不同的应用场景催生了多样化的应用开发策略,这些策略不仅展现了大模型应用开发的丰富可能性,也预示着未来AI技术在各行业落地的广阔前景。
1. Prompt工程
参考《如何做好Prompt工程》:https://www.datawhale.cn/learn/content/159/3799
- 作用:通过优化输入提示词,提升模型输出的准确性和可控性。
- 方法:
- 角色扮演:明确模型角色(如“你是一个专业的翻译专家”)。
- 结构化指令:分步骤引导模型(如“首先生成大纲,再填充细节”)。
- 示例:翻译任务中限定输出格式(如保留术语、控制段落长度)。
2. 设计应用交互和功能(应用的核心)
参考《优化攻略:应用设计》:https://www.datawhale.cn/learn/content/159/3802
以及《AI时代、如何做好AI应用设计》:https://www.datawhale.cn/learn/content/157/3763
3. 引入知识库和RAG技术(检索增强生成)
参考
- 作用:结合外部知识库解决模型“幻觉”问题,提升专业领域回答的准确性。
- 实现步骤:
- 构建知识库(如企业文档、行业数据)。
- 在 Agent/工作流 中调用知识库
⭐展开了解【RAG的基本概念】
1.1 什么是RAG
在实际业务场景中,通用的基础大模型可能存在无法满足我们需求的情况,主要有以下几方面原因:
- 知识局限性:大模型的知识来源于训练数据,而这些数据主要来自于互联网上已经公开的资源,对于一些实时性的或者非公开的,由于大模型没有获取到相关数据,这部分知识也就无法被掌握。
- 数据安全性:为了使得大模型能够具备相应的知识,就需要将数据纳入到训练集进行训练。然而,对于企业来说,数据的安全性至关重要,任何形式的数据泄露都可能对企业构成致命的威胁。
- 大模型幻觉:由于大模型是基于概率统计进行构建的,其输出本质上是一系列数值运算。因此,有时会出现模型“一本正经地胡说八道”的情况,尤其是在大模型不具备的知识或不擅长的场景中。
为了上述这些问题,研究人员提出了检索增强生成(Retrieval Augmented Generation, RAG )的方法。这种方法通过引入外部知识,使大模型能够生成准确且符合上下文的答案,同时能够减少模型幻觉的出现。
由于RAG简单有效,它已经成为主流的大模型应用方案之一。
如下图所示,RAG通常包括以下三个基本步骤:
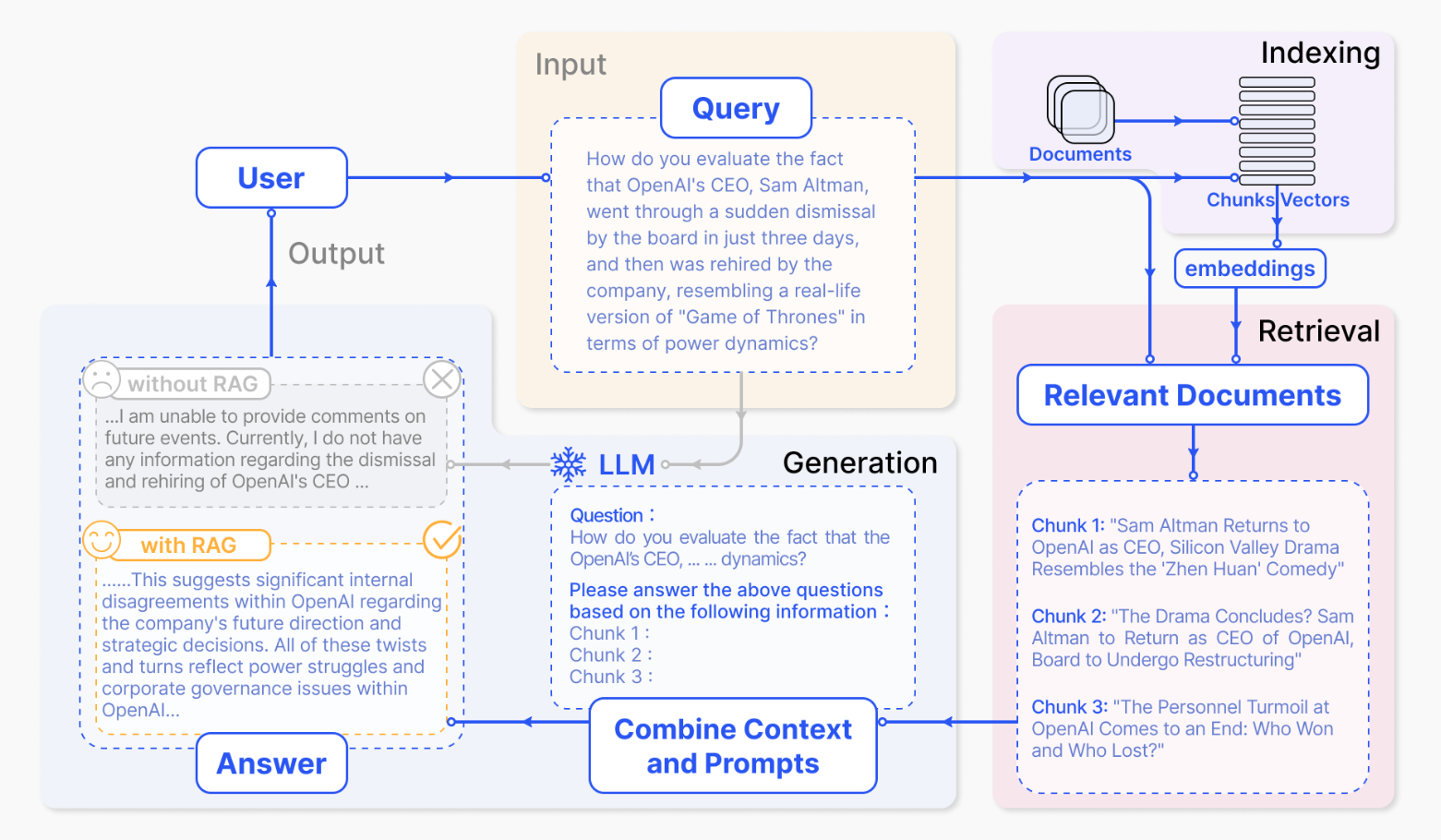
- 索引:将文档库分割成较短的 Chunk ,即文本块或文档片段,然后构建成向量索引。
- 检索:计算问题和 Chunks 的相似度,检索出若干个相关的 Chunk。
- 生成:将检索到的Chunks作为背景信息,生成问题的回答。
4. 构建工作流
** 💡有手就行的Prompt工程 **
Prompt工程(Prompt Engineering)是指通过精心构造提示(Prompt),直接调教大模型,解决实际问题。
为了更充分地挖掘大模型的潜能,出现了以下两种技术:
上下文学习(In-Context Learning, ICL):将任务说明及示例融入提示文本之中,利用模型自身的归纳能力,无需额外训练即可完成新任务的学习。
思维链提示(Chain-of-Thought, CoT):引入连贯的逻辑推理链条至提示信息内,显著增强了模型处理复杂问题时的解析深度与广度。
同时,我们还可以经常看到很多“Prompt框架”,及分享的优质Prompt,我们都可以尝试使用,慢慢构建自己实用的Prompt武器库** 💡RAG给LLM外接大脑 **
这个部分,阿里云百炼的知识库功能已经很好地做了封装
尽管大模型具有非常出色的能力,然而在实际应用场景中,仍然会出现大模型无法满足我们需求的情况,主要有以下几方面原因:
知识局限性:大模型的知识来源于训练数据,而这些数据主要来自于互联网上已经公开的资源,对于一些实时性的或者非公开的,由于大模型没有获取到相关数据,这部分知识也就无法被掌握。
数据安全性:为了使得大模型能够具备相应的知识,就需要将数据纳入到训练集进行训练。然而,对于企业来说,数据的安全性至关重要,任何形式的数据泄露都可能对企业构成致命的威胁。
大模型幻觉:由于大模型是基于概率统计进行构建的,其输出本质上是一系列数值运算。因此,有时会出现模型“一本正经地胡说八道”的情况,尤其是在大模型不具备的知识或不擅长的场景中。
因此,将知识提前转成Embedding向量,存入知识库,然后通过检索将知识作为背景信息,这样就相当于给LLM外接大脑,使大模型能够运用这些外部知识,生成准确且符合上下文的答案,同时能够减少模型幻觉的出现。====文章分界线=*****=*********=============
401 AI办公实践与应用
Cpt0-开篇
人工智能是什么;
就是让机器像人一样思考和做事。
拥抱人工智能的意义;
拥抱AI,就是拥抱更美好的未来。
如何拥抱,实际应用 AI 的方法,包括智能设备、学习工具和职业发展。
以及系列课的简单内容概述。
围绕实际场景出发 ,确保学以致用。
Cpt1-用kimi完成一个小案例
看看用AI该怎么做?
用AI的方法:
1、把数据扔给AI
2、让AI自动分析,并告诉你结果Step1、打开一个AI文本大模型网站
知识点:AI文本大模型
什么是AI文本大模型?
想象一下,你有一个超级聪明的朋友,他读过无数的书,知道世界上各种各样的事情。你问他任何问题,他都能用很流畅的语言回答你,甚至还能 帮你写作文、编故事、整理资料 。这个超级聪明的朋友,其实就是AI文本大模型。
简单来说:
AI文本大模型就像是一个超级大脑,它通过学习海量的文字信息(比如书籍、文章、网页内容等),学会了怎么用语言表达各种想法。你可以给它一个提示,比如“写一篇关于环保的文章”,它就能根据它学到的知识,生成一篇通顺的文章。它还能帮你回答问题、翻译语言,甚至写代码呢!咱们这次以月之暗面的KIMI为例(网址:https://kimi.moonshot.cn/)
Step2、输入提示词(prompt)
提示词参考如下:角色+背景介绍+输出要求
你是高级数据统计员,现在有一份微信群的接龙帖子,请帮我统计成表格的形式,整理好后给你100块钱;
(然后把接龙帖子的内容粘贴进来)
可以看到效果不错,是我们想要的结果。
- 注:如果想要导出来,可以直接复制粘贴到Excel表格上。因为目前有很多的AI文本大模型并不支持导入或导出Excel表格,你也可以试试让AI把输出结果转换成Markdown格式,再用专门的Markdown转xlms的网站(免费)来完成格式转换。
Step3、补充信息,完善分析
拿到数据以后,我们继续结合数据背后的含义(零食清单),来继续下一步的分析,例如,看看大家喜欢哪一种零食多一点?
继续输入如下:
以下是每个数字选项对应的含义,结合数字背后的含义,帮我做一下数据分析,看看大家都喜欢什么样的零食?
# 零食清单
1 炸鸡汉堡
2 旺旺零食大礼包
3 星球杯大桶- LLM在统计数据这里确实不够完美期待大模型进一步完善
Cpt2- 讯飞做PPT
这里我们用讲讲提示词文本来生成:
1.在Kimi链接下使用如下Prompt生成PPT文案
你是编写PPT的专家,荣获过多次国际大奖
现在需要用做一份演讲,主题是《射雕英雄传的黄蓉为什么喜欢郭靖》,
你帮我设计演讲框架,包含一二三级标题,同时对框架填补好文稿文字,演讲大概10分钟左右,演讲文稿的风格要偏向幽默的、活泼的、青春的。这份文稿将给讯飞智文进行PPT创作,把文稿写出来给我,谢谢生成文案后使用讯飞文本生成PPT生成PPT看下生

image-20250619135626001
生成的过程调整文字:
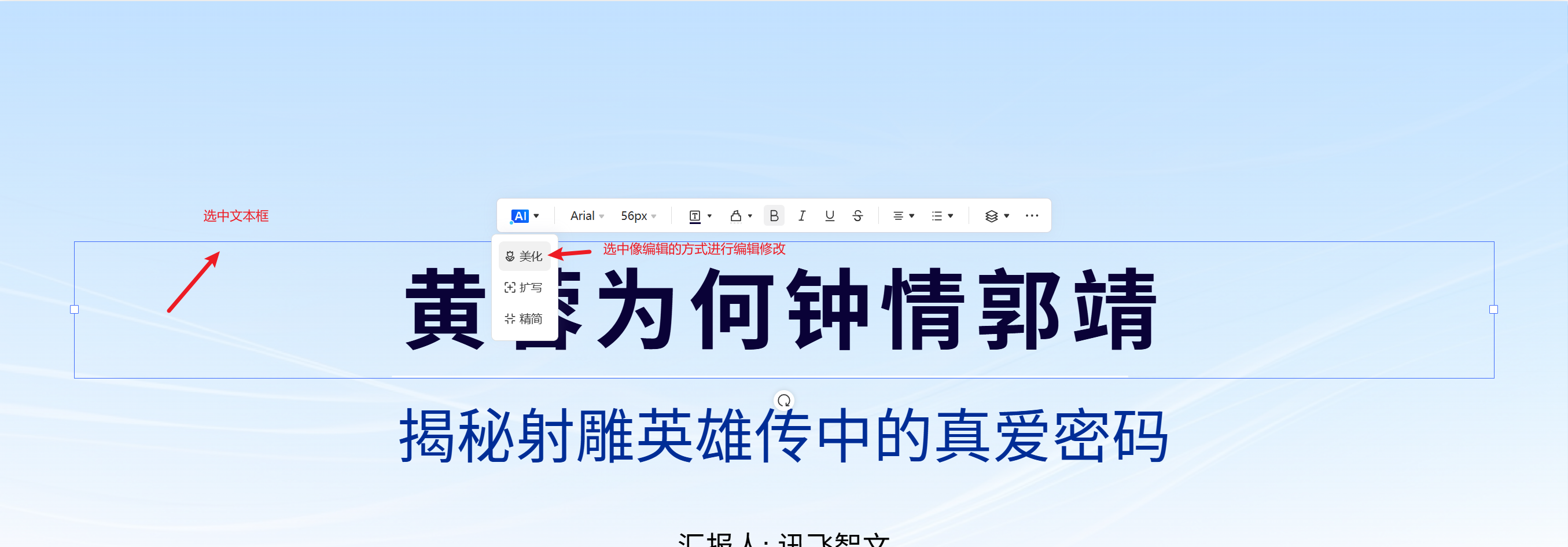
生成的过程中调整图片:
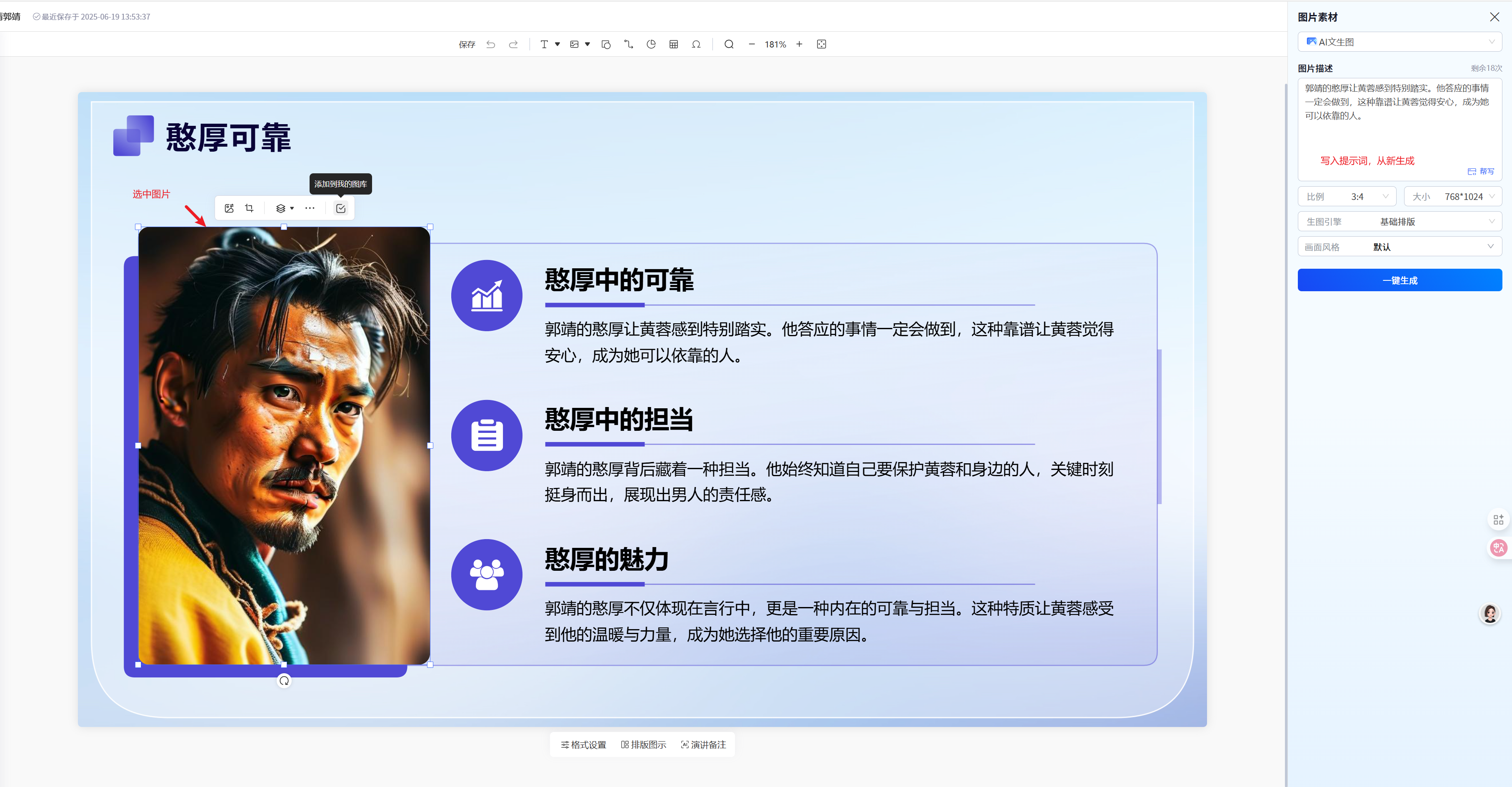
生成后的PPT样子:

Cpt3和Cpt4
1.使用AI处理数据
[小浣熊家族 Raccoon - AI 智能助手 - 商汤科技](https://xiaohuanxiong.com/login)
将Excel数据扔给AI帮你分析出数据,并且视觉化呈现,关键在于提示词,这里可以用教案给出的:
结构:AI的角色+背景+需求
假设你是一名专业的财务数据分析师,最近总是感觉自己每个月的现金支出速度非常快,而且似乎不太合理。附件是2月份的所有现金流量明细,你需要分析出下面几个方面的问题:
1、对数据进行描述性分析,看数据质量好不好
2、分析数据,看看现金支出有没有不合理的地方
3、分析数据,分析为什么总是到月底了就没钱用了的原因2.用AI画“靓”图
经常需要画图:思维导图”和“流程图”是一项非常耗时的工作,特别是开头部分特别难搞,我们有了AI工具能够让你焦距与创作。
思维导图具体步骤:
Deepseek,网址是https://www.deepseek.com/
提示词结构:角色+背景+需求
角色:你是一名国内985院校优秀的应届毕业大学生、校内优秀的“明日之星”候选人 背景:你现在在参加“明日之星”评选大赛,需要进行论述和报告,大赛规模很大,标准很高。 在学习上,只拿了三次奖学金,专业排名前十,绩点4.2(满分5.0)。社会活动中,做过一次三下乡队员、一次农村支教教师、一次大学生军训带训教官。比赛方面,拿到过数据竞赛二等奖、羽毛球比赛单打冠军、排球院赛前三、合唱比赛全球赛银奖。 要求:你现在要写一份述职汇报的思维导图,要求条理清晰、逻辑合理、概述精要,思维导图只需要两个层级即可。思维导图按照Markdown的格式生成发给我。新建md文件
将Deepseek生成的md文件以.md结尾的文件保存。
使用思维导图软件打开
可以看到效果
流程图具体步骤:
Deepseek,网址是https://www.deepseek.com/
提示词结构:角色+背景+需求
帮我画一个财务报销流程图,用mermaid格式呈现打开图形生成网站
将刚才的内容黏贴进去
image-20250623100731555 保存便可以看到效果。
Cpt5 进阶
1. DeepSeek
1 使用豆包国内常用模型对比图:
以下是 DeepSeek、豆包和 Kimi 的优缺点对比表格,从核心能力、功能特点、适用场景等维度进行结构化呈现:
| 对比维度 | DeepSeek | 豆包 | Kimi |
|---|---|---|---|
| 核心优势 | - 复杂推理能力强(代码开发、数学公式推导等) - 长上下文支持(约 10 万字符) - 成本低(API 价格亲民) - 垂直领域优化(金融、编程) | - 多模态能力强(文 / 图 / 音生成交互) - 响应速度快(<2 秒) - 字节生态集成(抖音、飞书等) - 互动娱乐性强(表情包、热梗解读) | - 长文本处理标杆(支持 200 万字文档) - 信息溯源(标注引用来源) - 中文优化好 - 实时联网搜索 |
| 专业能力 | - 代码生成与调试、数学问题求解、数据处理能力突出 - 金融 / 编程领域模型更适配业务场景 | - 图文创作、短视频脚本生成效率高 - 日常对话流畅,但专业深度不足 | - 文档解析(PDF/TXT 等)能力强 - 中文语义理解精准,但复杂推理(如代码、数学)中等 |
| 上下文处理 | 支持约 10 万字符,可解析代码 / 公式 | 支持约 1.6 万字符,需分段输入 | 支持 20 万 + 字符(可处理 200 万字文档),支持文档直接上传解析 |
| 多模态功能 | 主要支持文本 / 代码,图像 / 语音功能有限或未开放 | 支持文生图、语音对话、表情包生成等,多模态交互丰富 | 纯文本交互,暂不支持语音 / 图片生成 |
| 成本与部署 | API 成本低(输入 2 元 / 百万 tokens,输出 8 元 / 百万 tokens) 支持端侧部署(如 R1 模型 2GB 资源运行) | 依托字节服务器,免费版功能基础,企业版需定制收费 | 基础功能免费,高级功能(如实时搜索)部分收费,企业版支持私有化部署 |
| 适用场景 | - 专业开发者(代码辅助) - 科研人员(公式推导) - 企业级成本敏感型应用(如金融数据处理) | - 普通用户(日常聊天、娱乐互动) - 内容创作者(图文 / 短视频脚本) - 字节生态内办公协同(飞书文档辅助) | - 学术研究者(文献解析) - 职场人士(长文档处理、实时信息检索) - 中文内容深度阅读与分析 |
| 缺点 | - 日常对话流畅性一般 - 多模态能力较弱 - 界面操作稍复杂,新手入门门槛高 | - 长文本处理需分段,深度分析能力不足 - 专业领域定制方案缺失 - 创意内容易触发安全限制 | - 多模态功能缺失 - 知识库更新截止 2023 年,实时性不足 - 复杂推理能力中等 |
| 生态整合 | 侧重技术开发者生态,与编程工具集成较多 | 深度整合抖音、飞书、剪映等字节系产品,工作流衔接便捷 | 支持多客户端(网页 / APP / 小程序),与办公场景结合紧密 |
2 使用ChatGPT对比各模型,大家可以根据自己需要选择使用:
以下是 DeepSeek、豆包(字节跳动)、Kimi(月之暗面)和 ChatGPT(OpenAI)的对比分析,涵盖模型能力、使用场景、数据来源、特色功能、优缺点等维度,适合用于专业决策和评估:
✅ 大模型横向对比表(截至 2025年6月)
| 对比维度 | ChatGPT(GPT-4.5/o4) | Kimi(月之暗面) | 豆包(字节跳动) | DeepSeek(深度求索) |
|---|---|---|---|---|
| 开发公司 | OpenAI(美国) | 月之暗面智能科技(中国) | 字节跳动(中国) | DeepSeek AI(中国,清华系) |
| 最新模型 | GPT-4.5(o4 / GPT-4o) | Kimi Chat(Yi-Large,Yi-34B) | 云雀(Skywork)/豆包大模型 | DeepSeek-VL / DeepSeek-Coder |
| 能力方向 | 全面泛化(文本、代码、数学、对话) | 长文本能力强,适配中文 | 中文问答、电商推荐、泛内容生成 | 编程能力强,数学推理表现佳 |
| 上下文长度 | GPT-4o:128k | 最大支持 200 万汉字(~400k token) | 标准20k(部分对话最大支持100k) | 标配200k token |
| 使用语言支持 | 多语种,英语/中文均佳 | 中文最佳,英文合格 | 中文为主,支持少量英文 | 中文好,英文较弱 |
| 插件/工具调用 | 强(浏览器、代码执行、图像生成等) | 支持联网搜索、文档解析 | 支持多模态(图文) | 支持 Web 阅读和代码生成 |
| 本地部署能力 | 不开放本地部署 | 不开放 | 不开放 | 部分模型可本地部署 |
| 响应速度 | 较快(GPT-4o),低延迟 | 中等偏快 | 快速,适合移动端 | 快速,开发者响应好 |
| 长文本总结能力 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐(主打功能) | ⭐⭐⭐⭐ | ⭐⭐⭐⭐(结构化处理好) |
| 代码生成能力 | ⭐⭐⭐⭐⭐(强代码、调试能力) | ⭐⭐⭐(基础可用) | ⭐⭐⭐(面向内容运营类) | ⭐⭐⭐⭐⭐(接近 GPT-4) |
| 价格/使用门槛 | Plus需付费,API较贵 | 免费/部分收费(高并发需排队) | 基本免费,API开放中 | 免费网页体验,API需申请 |
| 典型使用场景 | AI编程助理、教育、科研、营销 | 文档阅读、PDF解析、会议总结 | 电商客服、内容创作、短视频脚本 | 算法竞赛、代码辅助、学术问答 |
| 优点 | 全球领先,综合能力顶尖 | 长文本处理极强,体验友好 | 中文优化深、落地场景丰富 | 数学与代码领先,适合专业开发 |
| 缺点 | 国内访问速度稍慢、部分限制 | 代码能力较弱,推理能力中等 | 英文能力弱,创新性不强 | 内容创意/生成能力相对保守 |
📌 总结建议:
| 使用目的 | 推荐模型 |
|---|---|
| 中文长文总结 | ✅ Kimi |
| 多语言/代码开发 | ✅ ChatGPT |
| 本地部署可选、开源需求 | ✅ DeepSeek |
| 中文场景泛用(客服、电商) | ✅ 豆包 |
如你有特定任务(如法务文档、教育评测、AI编程助手等),我可以继续帮你定制更详细的推荐。需要吗?
3 提示词怎么写?
3.1 三步速成法 :
1、明确需求 (核心指令)
- 烂例子:"写个方案" → AI可能给你编菜谱
- 好例子:"用小学生能听懂的话,解释区块链技术,带两个生活比喻"
2、细化要求 (添加约束)
- 格式:"请列出3点,每点不超过20字"
- 风格:"模仿鲁迅杂文风格,带讽刺语气"
- 数据:"参考2023年统计局报告数据"
3、场景设定 (角色扮演)
- 加魔法前缀:"假设你是10年经验的私募基金经理…"
- 或后缀:"回答后请用★符号标注不确定的内容"
3.2 高级技巧(专业向)
- 思维链提示 (Chain-of-Thought)输入:"请分步骤思考:如何用50元预算策划情人节惊喜?"输出:①需求拆解 ②预算分配 ③执行步骤
- 多轮对话控制 第二轮追加:"针对第三步,给出3个具体礼物采购链接(限京东平台)"
- 知识库限定 指令:"仅依据《民法典》第三章内容,解释肖像权保护范围"
3.3 注意要点(避坑清单)
- ❌ 避免模糊词:"写得好一点" → 改为"使用四字成语,带押韵"
- ❌ 控制长度:单次提示词建议<300字(超长指令AI会漏看)
- ❌ 特殊字符:慎用#%&等符号(可能触发系统过滤)
- ✅ 最佳实践:复杂任务拆解为"背景说明+具体要求+输出格式"三段式
4 提示词模板
角色+背景+需求+其他小技巧
5 Cpt3 作业练
使用DeepSeek可以:

使用Kimi差一点:
2 AI文生图
- 使用DeepSeek优化作画提示词
我现在策划设计一张活动宣传海报,活动内容是“六一儿童节”现场直播的歌舞晚会,我打算用ai工具做海报,海报具体内容如下:1、海报标题,帮我想一下,标题要简明扼要、直观;2、活动时间,2025年6月1日晚上8点;3、直播会议号,123456。请帮我生成一段提示词,用来告诉AI让AI帮我生成这个海报- 用通义万相来画
- 用豆包来画图,豆包本身可以优化提示词;直接使用也可以;
总结
- 文生图的核心要点
文生图的核心在于“精准描述+风格选择”。首先, 描述要具体 ,比如“戴着墨镜的酷炫猫咪”比“一只猫”更容易生成理想效果;其次, 风格要匹配 ,比如二次元适合头像,写实风适合场景图。此外, 关键词组合也很重要 ,如“赛博朋克+夜景+未来都市”能生成科幻感十足的画面。最后, 多次调整 是常态,AI生成是一个迭代优化的过程,需要不断尝试和优化描述,才能得到满意的结果。
- 上述AI工具各自的特性及注意事项
DeepSeek :擅长生成高细节、高写实度的图像,适合商业设计或专业场景,但对硬件要求较高,生成速度稍慢。
豆包 :操作简单,风格多样,适合快速生成个性化头像或趣味插画,但生成分辨率有限,适合轻量级需求。
通义万相 :支持多种艺术风格,尤其擅长二次元和中国风,生成速度快,但部分风格需要付费解锁。
使用这些工具时, 注意版权问题 ,避免生成侵权内容;同时, 保存生成参数 ,方便后续优化和复用。
- 实践出真知
文生图是一个充满创意和可能性的领域,不要害怕失败,每一次尝试都是进步。多练习描述技巧,多探索不同工具的特性,你会发现AI的潜力远超想象。大家记住, 实践是最好的老师 ,从生成一张头像开始,逐步挑战更复杂的场景和风格。期待大家用AI文生图技术,创造出属于自己的视觉奇迹!
3 AI文生视频
引言,需要生成一个科技含量的视频:DeepSeek
我是一名资深的人工智能办公技能的讲师,现在需要设计一份深蓝色为基调、富含科技风的幻灯片首页,希望用AI文生视频的工具来设计出一份PPT首页背景用的小视频,要富含科技感、有淡淡的律动、类似于圆圆的小齿轮转动的那种。请你告诉我一份提示词,要精准、精炼deepseek返回的提示词:
"Ultra HD 8K, deep navy blue tech background with subtle glowing circuit lines, multiple minimalist silver gears rotating smoothly in sync, holographic light particles floating, cyberpunk aesthetic with clean futuristic style, soft rhythmic pulsation of blue neon lights, cinematic depth of field, 4 seconds loop, ultra-detailed render --ar 16:9 --v 6"提示词优化点:
1、色彩控制:深海军蓝(#000080)为主,搭配银色机械元素
2、动态元素:同步旋转的极简齿轮 + 全息光粒子浮动
3、律动节奏:通过蓝色霓虹光的柔和脉动实现
4、适配性:16:9比例适配PPT,4秒循环视频确保无缝播放可以使用:
通义万相的地址是:https://tongyi.aliyun.com/wanxiang/
即梦AI的地址:https://jimeng.jianying.com/
可灵AI的地址:https://app.klingai.com/cn/
例子:制作红包封面小视频
本实践的主要步骤,和上面实践的步骤差不多
推荐看下面这篇知乎实践文章~
https://zhuanlan.zhihu.com/p/19909831738
总结
总结
一、文生视频核心要点
动态脚本即蓝图: 用文字指挥时间轴,描述中必须包含动作(“跳跃转身”)、时长(“3秒特写镜头”)和场景变化(“镜头从星空拉到地面”),动词比形容词更重要。
分镜思维: 将长视频拆解为“5秒单位”(如“前5秒日出→中间5秒飞鸟→结尾5秒笑脸”),避免一镜到底导致AI混乱。
物理合理性: AI常违背重力/光影逻辑(如头发反重力飘动),需添加约束词(“自然垂落”“符合现实光影”)。
版权地雷: 商用需排查AI训练数据版权,避免生成明星脸、商标元素,人物最好用“通用形象”(如“穿西装的卡通熊”)。
二、工具特性及注意事项
通义万相: 擅长3-10秒故事片段,场景宏大但动作生硬(如人物走路像木偶)。建议生成后手动补关键帧,输入指令时细化动作节点(“先抬手→再弯腰→最后跳跃”)。
即梦AI: 动态特效王者(粒子光效/水波纹),但分辨率仅720p。适合抖音风短视频,输入词需强调“炫光”“流动感”,避免复杂叙事。
可林AI: 分镜控制精准(可指定镜头切换方式),但素材库风格单一(偏日系二次元)。生成前必选风格滤镜(“赛博朋克/水墨风”),否则默认产出萌系画风。
通用法则: 所有工具都吃“帧率彩蛋”——输入“24fps电影级流畅”比默认15fps更顺滑,但生成耗时翻倍。
三、多实践多应用
做时间轴指挥官: 把AI当成会犯错的动画师,你的指令越像“导演脚本”(“镜头从左移到右,同时人物挥手”),它越听话。每次失败都藏着AI的“脑回路密码”(例如发现“微笑”指令总生成咧嘴怪,就改用“嘴角轻微上扬”)。
建你的魔法配方库: 记录成功案例的关键词组合(如“夏日海滩+奔跑+慢动作=可林AI_2秒片段”),这些配方会随着AI迭代升值。
警惕技术滤镜: 别被酷炫特效迷惑,观众永远为“情感共鸣”买单。哪怕用最简陋的AI工具,只要你的脚本里有“小狗冒雨送伞”的温暖瞬间,就是好作品。Cpt5 AI办公
1. AI辅助内容运营
内容运营的本质是什么?是传递产品价值。
流量的背后是什么?是内容。就内容是撬动流量,现在是一个内容为王的时代,流量的内容如何体现其价值?答案就是:内容营销。
- 1分享有价值的内容
- 2吸引目标用户的注意力
- 3好内容帮助品牌赢得信任
- 4提高品牌知名度
- 5最终转化为客户
什么是AIGC?
AIGC(AI生成内容)就像一位"数字魔法师",能用AI技术自动创作文字、图像、音视频等内容。
AIGC对内容运营的形式
既然AIGC对内容运营有这么多的帮助,那么内容运营,或者说内容营销,它的形式有哪些呢?
1.文本内容的生成
对AIGC说一个指令,直接就能拿到一个文本形式的结果。这个已经相当普及了,deepseek,kimi,星火,文心一言,等等国内知名的大模型,都能做到这一步。
2.AIGC图片生成
找插图总是搜不到合适的图片?文生图可以帮到你。
3.AIGC真人图像建模
简单的说,就是数字人技术。
4.AIGC声音的生成
前段时间闹得沸沸扬扬的一个事件,有人用已故歌手的声音进行训练,创作了新的歌曲甚至是视频。虽然从立场来看并不被群众所认可,但这个技术已经相当完善了。包括很多唱歌APP都推出了AI智能唱歌的功能,就算你五音不全,也能帮你“训练”出明星的声音和曲风来。
5.AIGC视频生成
文生视频的技术目前似乎还不太完善,当然相信不久的将来这门技术也会面世。
====文章分界线=*****=*********=============
备注: