02业务架构设计与分析
2. 需求框架分析
1.1 一些概念
1 架构与系统
1. 软件架构
架子 骨架 + 组合 构成
描述实体和关系
本质上是为客户提供解决方案
2. 软件系统
系统是为客户提供的业务价值的领域的功能。
3. 架构与系统
架构的核心是思想,比如降低复杂度,可复用;
影响架构的因素:
内在因素:优化、重构
外因素:需求变化
简单总结:
- 系统 = 实际运行的 “实体”(房子),由零件(代码)组成;
- 架构 = 规划零件如何组装的 “蓝图”,决定系统的稳定性、扩展性和性能;
- 关系:没有蓝图(架构)的房子(系统)会摇摇欲坠,没有架构的系统会变成 “屎山代码”,难以维护和升级。
核心逻辑:架构是 “提前规划”,系统是 “按规划落地的结果”,好架构让系统像 “设计合理的房子”,住得舒服(运行稳定、容易迭代)。
2 将需求文档细化
概念:是对客观事物或者现象的描述;可以帮人更好的理解复杂的信息。
思考:汽车的概念
答:四个轮子,有方向盘,可以行驶在路上
功能:事物或系统能完成的任务或效用。
显性功能:在需求中体现出来;
隐性功能:有可能在产品描述中没有提到的功能:比如登录 注册 联登 三方数据等;
区别:概念和功能是不同的东西。
概念定义了是什么,功能是解释了能做什么。
※ 在拆分需求时首先明确 项目的主旨 的概念和功能;
业务往往就是一句话,产品是业务的具体化功能拆解和组成;
3 功能分类
1 什么是分类
根据对象的某种特征或者属性将其划分到不同的类别或范畴中。
2 分类标准:
待分类的对象前提是有特征的;
比如:机票的特征 价格 航班时间

需求中的名词解释就是领域专家的事情,AI时代可以问AI可以替代大部分领域专家。
3 功能分类的步骤
1 看到功能要理解有哪些特征;
2 基于这些特征,问领域或者业务专家,在理解上面的偏差;
3 得出一个标准性的功能的特征;
4 分类的标准
特征的相似性
找关键字是否一样,如下面的图。

image-20250624140043718 可以分类为下面的样子:

image-20250624142208344 功能相似性
根据对象的功能是否相似类进行分类。

目的和用途
更具对象的目的和用途来进行分类。

image-20250624143343759 时空分布法
根据对象在时空上的分布来分类。
※这个分类就是建模的依据
4 抽象的产物
抽象出来的东西在调整,有可能宽了有可能小了,需要合并;
最终这种产物就是 划分出来的子域;
5 三种架构图
业务架构图
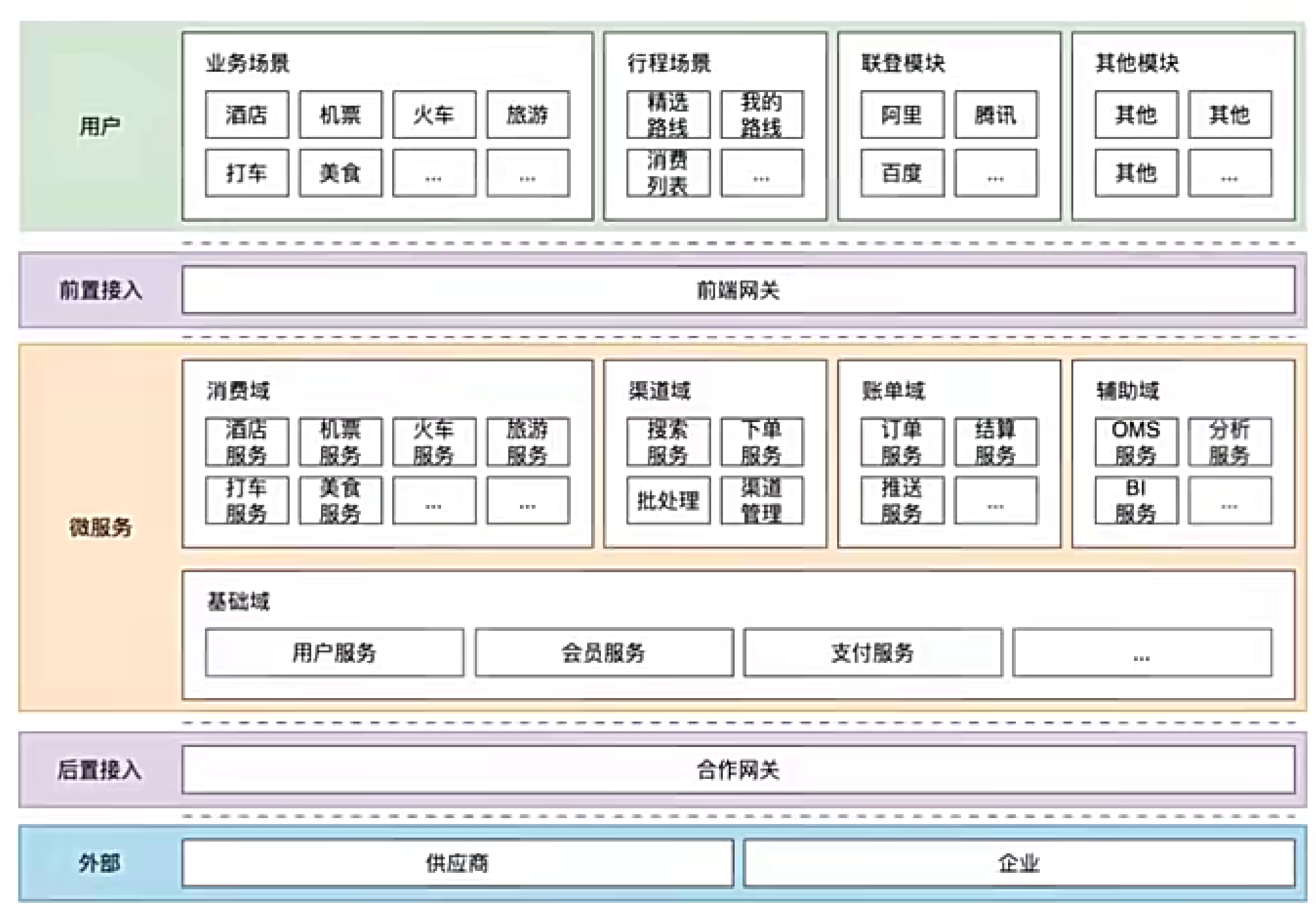
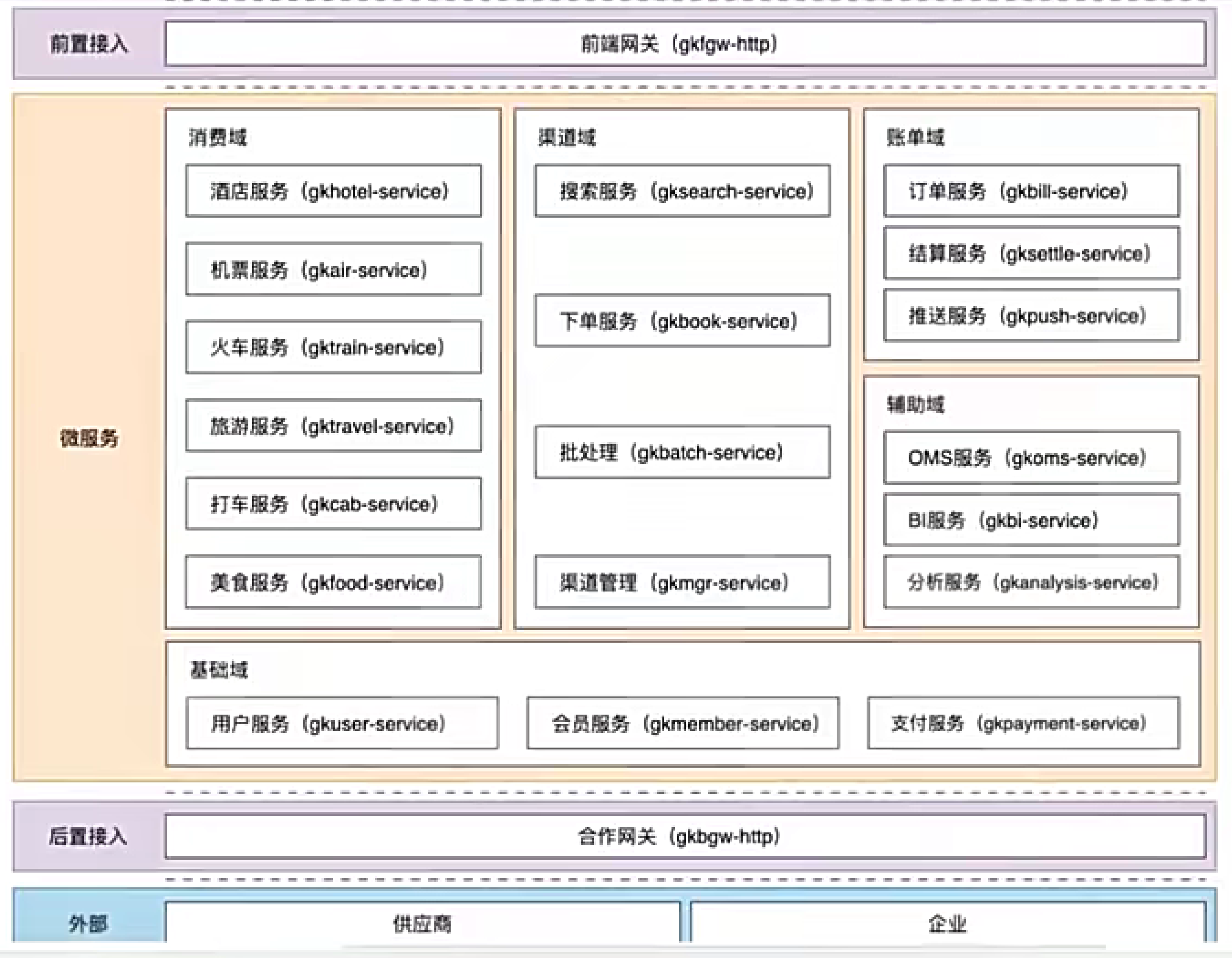
微服务架构图
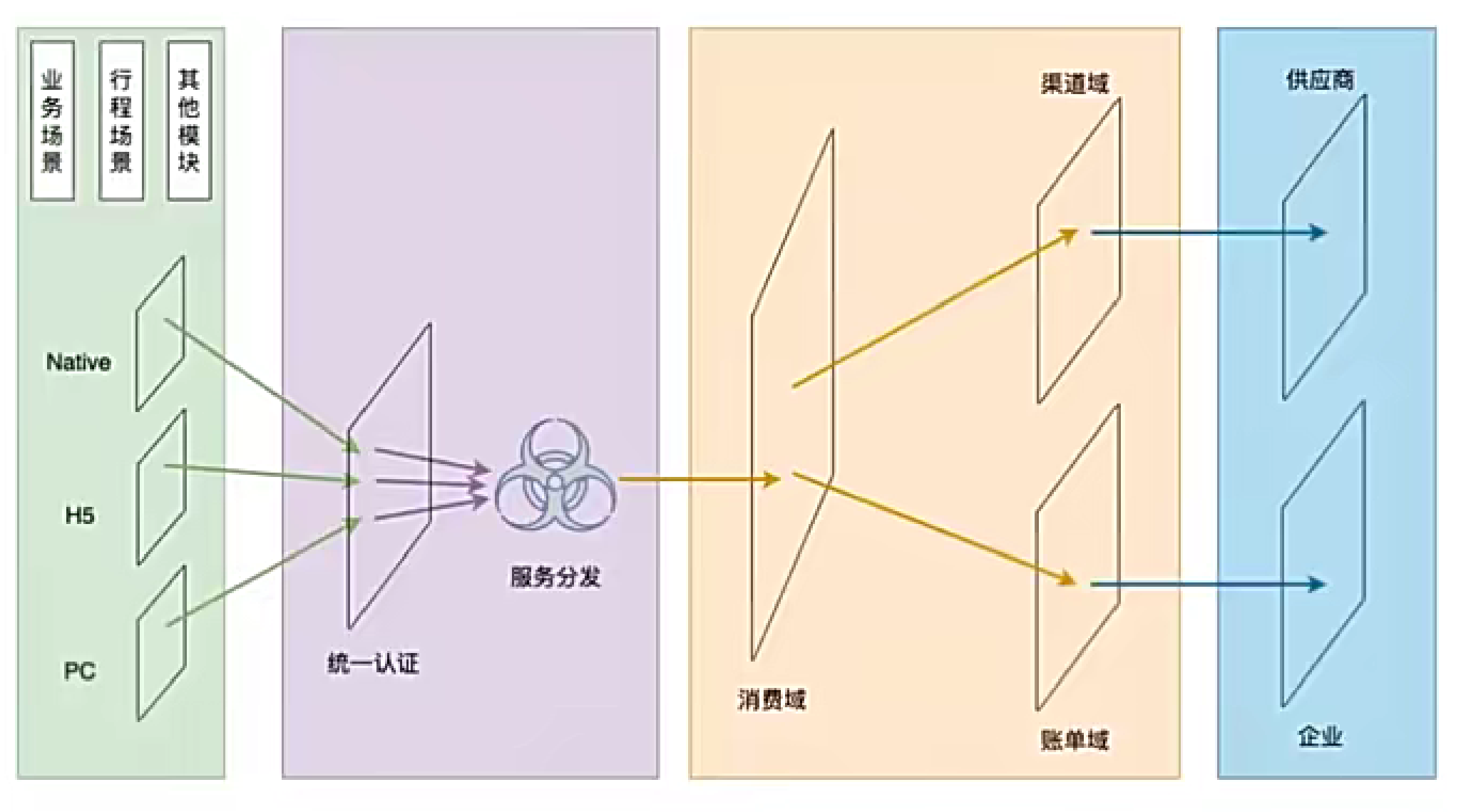
数据流规划图
2 百万并发认证业务分析
2.1 百万并发认证需求分析
看到需求后,分析需求的方法论有吗:
方法论一 流程分析法
它是一种系统分析方法,用于分析和理解一个系统或过程的工作原理和操作步骤。
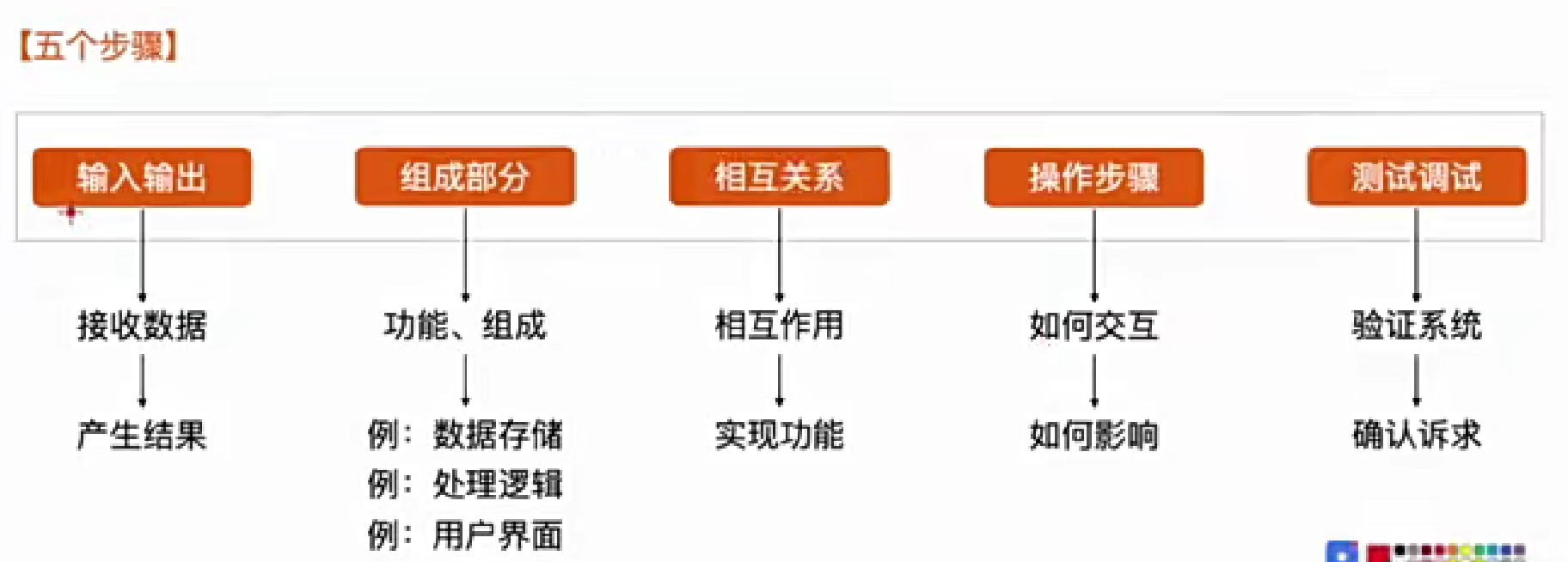
自所以一开始提出输入输出,是将开始和最后定下来,形成某种意义上的固定。
组成部分中,在当前步骤或者多个步骤中,去掉某一个组成能用吗,多问一问,发现问题。
如下业务拆解出来的流程,需求拆解出来后可以是一个或者多个流程。

在流程中,比如提交材料的步骤带上【五个步骤】进行思考,可以深入理解需求或者业务流。
【作用】:
分析产品需求
梳理业务诉求
排查产线问题
方法论二 时间顺序法
要求我们按照时间顺序对问题进行排序和处理。

举例子:

2.2 百万并发技术选型
1 了解一些名词 和 常识
并发 并行 QPS TPS 几个9
并发:一段时间内,以秒衡量承载体的并发量。比如:多个任务给一个CPU处理。
并行:同一时刻内,同事处理任务。使用多个处理者同时处理多个任务。比如:多台服务器处理多个任务。
⭐ 并发强调的是多个任务共享同一个资源。
⭐ 并行强调的是多个资源处理多个任务,集群的概念。
QPS:每秒响应的查询次数。侧重 系统处理能力。
TPS:每秒能够处理的事物次数。1个TPS包含多个QPS。侧重 处理的速度。
几个9
1个9:(1 - 90%) * 365 = 36.5d
2个9:(1 - 99%) * 365 = 3.65d
3个9:(1 - 99.9%) * 365 * 24 = 8.76h
4个9:(1 - 99.99%) * 365 * 24 = 0.876h = 52.6min
5个9:(1 - 99.999%) * 365 * 24 * 60 = 5.26min
6个9:(1 - 99.9999%) * 365 * 24 * 60 * 60 = 31s
内存、进程
【内存】
DDR4:4C8G机器的RAM⼀般是这种类型,读写延迟通常在5-10纳秒,慢的也有100ns以上的情况。
SWAP:交换空间利⽤率 70%。延迟达到1ms-100ms级别
【CPU】
应⽤:70%
数据库:65% ~ 70%。
【进程】
windows:每个进程中的线程数,不允许超过 2000
Linux:每个进程中的线程数,不允许超过 1000
⽹络、磁盘
【⽹络】
带宽:万兆带宽(实际是 bit 算的),实际 1250M/s 8bit=1Byte
时延:以太⽹延迟⼀般为 100 - 150ms
光纤⽹延迟⼀般为 1 - 10ms
举例:ping 127.0.0.1,好的情况 1μs - 30μs,坏的情况⼏百μs也是有可能的
传输:1M 数据⼤致需 1 - 10ms,压缩则更佳
【磁盘】
HDD(Hard Disk Drive),5400 RPM(Rotations Per Minute,每分钟转数)的硬盘,读写理论最⼤值 12.5 MB/s
HDD SMR,写 100MB/s,读 500MB/s
SSD,写 1000MB/s,读 2000MB/s 一般使用这个
NVMe SSD,写 2000MB/s,读 2000MB/s
NVMe PCIe SSD,写 3000MB/s,读 3000MB/s
F5、DNS、LVS、Nginx、Tomcat 流量分发处理
【F5】
普通的,10W
⾼配的,100W
更⾼配的,数百万,反正就是贵
【DNS】
不⽤考虑并发,运营商会解决
【LVS】
普通的,8 - 10W
⾼配的,100W
【Nginx】
官⽹ 10W+
并发 ⼀般可达 6 - 10W 并发
通过加配置,调参数,10W+ 还是可达的,再厉害点的 15W+ 也是可⾏的
单台 4C8G,⻓链接 TPS 2 - 3W,短链接 TPS 1W,QPS > TPS
【Tomcat】
最⼤连接数:2 - 3K
最⼤线程数:300 - 1000
MySQL、Redis、Ehcache、Caffeine 缓存设计
20C256G,8K连接数,普通 QPS = 1 - 5W,快的话可达 10W+
PrimaryIndex: kw+,1 - 10ms
UniqueIndex: kw+,5 - 50ms
Index: kw+,5 - 50ms
【Redis】
⼩数据 8 - 10W 并发 ⼀般 5W 并发
我在 MBP(MACBooK) 可达 15W 并发
同步刷盘 1.5 - 2W
【Ehcache】
延时位于 ns 与 ms 之间,取决于数据和内存
Ehcache 读写可达 14W+
来看⼀段从百万数据检索千万次的情况
【Caffeine】
使⽤ Java8 对 Guava 缓存的重写版本,
⽽且在 Spring5 取代了 Guava
读写 100W+
ActiveMQ、RocketMQ、Kafka 消息队列设计
【ActiveMQ】
并发量:1W
【RocketMQ】
并发量:10W
【Kafka】
并发量:100W
了解这些基本常识,在架构实践时可以对当前系统做一个是否有问题的评判。
2 估算 应用 的资源消耗
要求:比如有100W的并发量
分析的结构如下:
【掌握资源经验估算⽅式】 掌握⼀个度:70% 百分⽐
【估算认证架构雏形】
⼊⼝ 100W:
DNS 怎么来,暂不考虑
⽹络带宽: 等会计算
负载均衡: 会从 F5、LVS、Nginx、Tomcat 等⽅⾯进⾏计算
【计算⽹络带宽】
- 100W * 1K = 1000000K 量⼤数据
- 换算为兆:1000000K / 1024 = 977M
- 换算为带宽:977M * 8 = 7816Mbps ==》 快到万兆带宽了么?
- 负载⼊⼝带宽:万兆带宽
- 内⽹通信:⼀般都具备万兆带宽
【计算负载均衡(F5/LVS/NGINX)】
【F5】
掌握⼀个度:70% 百分⽐
【LVS】
▪ (100W * 0.3 = 30W)/LVS,100/30 = 4
▪ (100W * 0.5 = 50W)/LVS,100/50 = 2
▪ (100W * 0.7 = 70W)/LVS,100/70 = 2
【NGINX】
▪ (2.5W * 0.7 = 1.75W)/Nginx,
▪ (30 + 3)/ 1.75 = 19
▪ (3W * 0.7 = 2.1W)/Nginx,
▪ (30 + 3)/ 2.1 = 16
▪ (5W * 0.7 = 3.5W)/Nginx,
▪ (30 + 3)/ 3.5 = 10
【计算负载均衡(Tomcat)】
线程数:500
▪ (500 * 1000 / 50 = 1W * 0.7 = 0.7W)/Tomcat,
1.75 / 0.7 = 3
▪ (500 * 1000 / 50 = 1W * 0.7 = 0.7W)/Tomcat,
2.1 / 0.7 = 3
▪ (500 * 1000 / 50 = 1W * 0.7 = 0.7W)/Tomcat,
3.5 / 0.7 = 5