进阶岛01-InternVL 部署微调实践
进阶岛
L2G1-InternVL3部署微调测评实践
1 如何部署多模态模型
工具
LMDeploy、vllm、ollama、transformers部署
这里我们用LMDeploy工具部署也是在基础岛阶段说的,今天复习一遍
安装 使用Cuda12.2镜像
conda create -n lmdeploy-vl python=3.10 -y
conda activate lmdeploy-vl
pip install torch==2.4.0+cu121 torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu121
pip install flash_attn --use-pep517
pip install lmdeploy==0.7.3 timm==1.0.15
# pip install lmdeploy==0.7.3 timm==1.0.15 flash_attn==2.7.3 #flash_attn下载很慢使用上面的2 调用本地internvl2_5模型识别图片
2.1 InternVL3-2B的cli-demo
返回结果:
(lmdeploy-vl) (base) root@intern-studio-50076254:~/demo# python cli-demo.py
2025-07-07 21:38:38,398 - lmdeploy - WARNING - model.py:2025 - Did not find a chat template matching /share/new_models/InternVL3/InternVL3-2B.
[TM][WARNING] [LlamaTritonModel] `max_context_token_num` is not set, default to 16384.
2025-07-07 21:38:40,046 - lmdeploy - WARNING - turbomind.py:214 - get 255 model params
[WARNING] gemm_config.in is not found; using default GEMM algo
2025-07-07 21:38:45,156 - lmdeploy - WARNING - tokenizer.py:499 - The token <|action_end|>, its length of indexes [27, 91, 1311, 6213, 91, 29] is over than 1. Currently, it can not be used as stop words
2025-07-07 21:38:45,967 - lmdeploy - WARNING - async_engine.py:645 - GenerationConfig: GenerationConfig(n=1, max_new_tokens=512, do_sample=False, top_p=0.8, top_k=40, min_p=0.0, temperature=0.8, repetition_penalty=1.0, ignore_eos=False, random_seed=None, stop_words=None, bad_words=None, stop_token_ids=[151645], bad_token_ids=None, min_new_tokens=None, skip_special_tokens=True, spaces_between_special_tokens=True, logprobs=None, response_format=None, logits_processors=None, output_logits=None, output_last_hidden_state=None)
2025-07-07 21:38:45,967 - lmdeploy - WARNING - async_engine.py:646 - Since v0.6.0, lmdeploy add `do_sample` in GenerationConfig. It defaults to False, meaning greedy decoding. Please set `do_sample=True` if sampling decoding is needed
这张图片展示了一位滑雪者在雪地上滑雪。她穿着红色和黑色相间的滑雪夹克,黑色滑雪裤,戴着条纹针织帽和太阳镜。她手持滑雪杖,脚上穿着蓝色滑雪靴,正在雪地上滑行。背景是白色的雪地,远处可以看到一些滑雪道的标志。
图中的女人正在滑雪。她穿着滑雪装备,手持滑雪杖,脚上穿着滑雪靴,正在雪地上滑行。python代码:
from lmdeploy import pipeline, TurbomindEngineConfig, GenerationConfig, ChatTemplateConfig
from lmdeploy.vl import load_image
model = '/share/new_models/InternVL3/InternVL3-2B'
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=16384, tp=1), chat_template_config=ChatTemplateConfig(model_name='internvl2_5'))
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
gen_config = GenerationConfig(top_k=40, top_p=0.8, temperature=0.8)
sess = pipe.chat(('描述一下图片', image), gen_config=gen_config)
print(sess.response.text)
sess = pipe.chat('图中女人在干什么?', session=sess, gen_config=gen_config)
print(sess.response.text)2.2 InternVL3-2B的web-demo
# 需要gradio环境
pip install gradio==5.29.0
# 运行代码
python /root/demo/web-demo.py
# 远程系统和本地映射
ssh root@ssh.intern-ai.org.cn -p 43979 -CNg -L 6001:127.0.0.1:6000路径:http://127.0.0.1:6001/ 可以上传图片
代码:
import gradio as gr
import torch
from transformers import AutoModel, AutoTokenizer, AutoConfig
from PIL import Image
# 加载模型部分
path = '/root/share/new_models/InternVL3/InternVL3-2B'
device_map = None
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=False,
low_cpu_mem_usage=True,
use_flash_attn=False,
trust_remote_code=True,
device_map="auto" if device_map is None else device_map
).eval()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# 预处理图片函数
def preprocess(image, max_num=12, image_size=448):
from torchvision import transforms as T
from torchvision.transforms.functional import InterpolationMode
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((image_size, image_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
pixel_values = transform(image)
pixel_values = pixel_values.unsqueeze(0).to(torch.bfloat16).cuda()
return pixel_values
# 推理函数
def predict(image, message, history):
if image is None:
return history + [("请上传一张图片", "")]
pixel_values = preprocess(image)
if history is None or len(history) == 0:
user_input = f"<image>\n{message}"
response, new_history = model.chat(
tokenizer, pixel_values, user_input,
generation_config={"max_new_tokens": 1024, "do_sample": True},
history=None, return_history=True
)
else:
response, new_history = model.chat(
tokenizer, pixel_values, message,
generation_config={"max_new_tokens": 1024, "do_sample": True},
history=history, return_history=True
)
return new_history
# Gradio界面
with gr.Blocks(title="InternVL3-2B Web Demo") as demo:
gr.Markdown("<h1 align='center'>📷 InternVL3-2B Chat Demo</h1>")
with gr.Row():
with gr.Column(scale=1):
image_input = gr.Image(type="pil", label="上传一张图片")
with gr.Column(scale=2):
chatbot = gr.Chatbot(height=600, label="对话")
message_input = gr.Textbox(placeholder="请输入你的问题...", label="提问")
send_btn = gr.Button("发送")
state = gr.State([]) # 保存history
def on_send(image, message, history):
if message.strip() == "":
return history
history = predict(image, message, history)
return history
send_btn.click(
fn=on_send,
inputs=[image_input, message_input, state],
outputs=[chatbot]
)
message_input.submit(
fn=on_send,
inputs=[image_input, message_input, state],
outputs=[chatbot]
)
demo.launch(server_name="127.0.0.1", server_port=6000, share=True)3 InternVL3-9B的微调
再一次安装环境:
conda create -n xtuner77 python=3.10 -y
pip install torch==2.4.0+cu121 torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu121
pip install flash_attn --use-pep517
pip install xtuner timm datasets==2.21.0 deepspeed==0.16.1
conda install mpi4py -y
pip install transformers==4.51.31 准备数据集
cd /root && mkdir train什么样的数据集:
目前主流的大模型对于三国演义电视剧的人物识别和画面剧情解读都很乏力。于是我用1994版《三国演义》的前5集制作了一个用于InternVL系列模型的训练集。
数据集存放于modelscope(https://www.modelscope.cn/datasets/livehouse/SanguoVLM-trainset/files)里,只需要把训练集下载到放在/root文件夹的./train文件夹里即可:
apt install git-lfs -y
git lfs install
git clone https://oauth2:你的token@www.modelscope.cn/datasets/livehouse/SanguoVLM-trainset.git如果有自己构建数据集,微调某个领域的VLM助手,可以参考https://internvl.readthedocs.io/en/latest/get_started/chat_data_format.html内容来制作数据集。
微调代码:
# Copyright (c) OpenMMLab. All rights reserved.
from mmengine.hooks import (
CheckpointHook,
DistSamplerSeedHook,
IterTimerHook,
LoggerHook,
ParamSchedulerHook,
)
from mmengine.optim import AmpOptimWrapper, CosineAnnealingLR, LinearLR
from peft import LoraConfig
from torch.optim import AdamW
from transformers import AutoTokenizer
from xtuner.dataset import InternVL_V1_5_Dataset
from xtuner.dataset.collate_fns import default_collate_fn
from xtuner.dataset.samplers import LengthGroupedSampler
from xtuner.engine.hooks import DatasetInfoHook
from xtuner.engine.runner import TrainLoop
from xtuner.model import InternVL_V1_5
from xtuner.utils import PROMPT_TEMPLATE
#######################################################################
# PART 1 Settings #
#######################################################################
# Model
path = "/root/share/new_models/InternVL3/InternVL3-8B"
# Data
data_root = "/root/xtuner74/datasets/train/SanguoVLM-trainset/"
data_path = data_root + "annotations-sft.jsonl"
image_folder = data_root + "images"
prompt_template = PROMPT_TEMPLATE.internlm2_chat
max_length = 8192
# Scheduler & Optimizer
batch_size = 5 # per_device
accumulative_counts = 2
dataloader_num_workers = 4
max_epochs = 1
optim_type = AdamW
# official 1024 -> 4e-5
lr = 1e-6
betas = (0.9, 0.999)
weight_decay = 0.05
max_norm = 1 # grad clip
warmup_ratio = 0.03
# Save
save_steps = 1000
save_total_limit = 1 # Maximum checkpoints to keep (-1 means unlimited)
#######################################################################
# PART 2 Model & Tokenizer & Image Processor #
#######################################################################
model = dict(
type=InternVL_V1_5,
model_path=path,
freeze_llm=True,
freeze_visual_encoder=True,
# comment the following lines if you don't want to use Lora in llm
llm_lora=dict(
type=LoraConfig,
r=128,
lora_alpha=256,
lora_dropout=0.05,
target_modules=None,
task_type="CAUSAL_LM",
),
# uncomment the following lines if you don't want to use Lora in visual encoder # noqa
# visual_encoder_lora=dict(
# type=LoraConfig, r=64, lora_alpha=16, lora_dropout=0.05,
# target_modules=['attn.qkv', 'attn.proj', 'mlp.fc1', 'mlp.fc2'])
)
#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
llava_dataset = dict(
type=InternVL_V1_5_Dataset,
model_path=path,
data_paths=data_path,
image_folders=image_folder,
template=prompt_template,
max_length=max_length,
)
train_dataloader = dict(
batch_size=batch_size,
num_workers=dataloader_num_workers,
dataset=llava_dataset,
sampler=dict(
type=LengthGroupedSampler,
length_property="modality_length",
per_device_batch_size=batch_size * accumulative_counts,
),
collate_fn=dict(type=default_collate_fn),
)
#######################################################################
# PART 4 Scheduler & Optimizer #
#######################################################################
# optimizer
optim_wrapper = dict(
type=AmpOptimWrapper,
optimizer=dict(type=optim_type, lr=lr, betas=betas, weight_decay=weight_decay),
clip_grad=dict(max_norm=max_norm, error_if_nonfinite=False),
accumulative_counts=accumulative_counts,
loss_scale="dynamic",
dtype="float16",
)
# learning policy
# More information: https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/param_scheduler.md # noqa: E501
param_scheduler = [
dict(
type=LinearLR,
start_factor=1e-5,
by_epoch=True,
begin=0,
end=warmup_ratio * max_epochs,
convert_to_iter_based=True,
),
dict(
type=CosineAnnealingLR,
eta_min=0.0,
by_epoch=True,
begin=warmup_ratio * max_epochs,
end=max_epochs,
convert_to_iter_based=True,
),
]
# train, val, test setting
train_cfg = dict(type=TrainLoop, max_epochs=max_epochs)
#######################################################################
# PART 5 Runtime #
#######################################################################
# Log the dialogue periodically during the training process, optional
tokenizer = dict(
type=AutoTokenizer.from_pretrained,
pretrained_model_name_or_path=path,
trust_remote_code=True,
)
custom_hooks = [
dict(type=DatasetInfoHook, tokenizer=tokenizer),
]
# configure default hooks
default_hooks = dict(
# record the time of every iteration.
timer=dict(type=IterTimerHook),
# print log every 10 iterations.
logger=dict(type=LoggerHook, log_metric_by_epoch=False, interval=10),
# enable the parameter scheduler.
param_scheduler=dict(type=ParamSchedulerHook),
# save checkpoint per `save_steps`.
checkpoint=dict(
type=CheckpointHook,
save_optimizer=False,
by_epoch=False,
interval=save_steps,
max_keep_ckpts=save_total_limit,
),
# set sampler seed in distributed evrionment.
sampler_seed=dict(type=DistSamplerSeedHook),
)
# configure environment
env_cfg = dict(
# whether to enable cudnn benchmark
cudnn_benchmark=False,
# set multi process parameters
mp_cfg=dict(mp_start_method="fork", opencv_num_threads=0),
# set distributed parameters
dist_cfg=dict(backend="nccl"),
)
# set visualizer
visualizer = None
# set log level
log_level = "INFO"
# load from which checkpoint
load_from = None
# whether to resume training from the loaded checkpoint
resume = False
# Defaults to use random seed and disable `deterministic`
randomness = dict(seed=None, deterministic=False)
# set log processor
log_processor = dict(by_epoch=False)微调:
cd /root/train
mkdir lora_output # 方便储存微调过程中各个阶段的模型
conda activate xtuner
export HF_ENDPOINT=https://hf-mirror.com
xtuner train internvl3-9b_lora_finetune.py --work-dir /root/xtuner74/train/lora_output --deepspeed deepspeed_zero1模型合并:
使用到的代码:
# Copyright (c) OpenMMLab. All rights reserved.
import argparse
import os.path as osp
import torch
from mmengine.config import Config
from transformers import AutoTokenizer
from xtuner.model.utils import LoadWoInit
from xtuner.registry import BUILDER
def convert_to_official(config, trained_path, save_path):
cfg = Config.fromfile(config)
cfg.model.pretrained_pth = trained_path
cfg.model.quantization_vit = False
cfg.model.quantization_llm = False
with LoadWoInit():
model = BUILDER.build(cfg.model)
model.to(torch.bfloat16)
if model.use_visual_encoder_lora:
vision_model = model.model.vision_model.merge_and_unload()
model.model.vision_model = vision_model
if model.use_llm_lora:
language_model = model.model.language_model.merge_and_unload()
model.model.language_model = language_model
model.model.save_pretrained(save_path)
tokenizer = AutoTokenizer.from_pretrained(
cfg.model.model_path, trust_remote_code=True
)
tokenizer.save_pretrained(save_path)
print(model)
def main():
parser = argparse.ArgumentParser(
description="Convert the pth model to HuggingFace model"
)
parser.add_argument("config", help="config file name or path.")
parser.add_argument("trained_model_pth", help="The trained model path.")
parser.add_argument("save_path", help="The path to save the converted model.")
args = parser.parse_args()
if osp.realpath(args.trained_model_pth) == osp.realpath(args.save_path):
raise ValueError("The trained path and save path should not be the same.")
convert_to_official(args.config, args.trained_model_pth, args.save_path)
if __name__ == "__main__":
main()执行命令:
python /root/train/internvl3-9b-merge.py /root/train/internvl3-9b_lora_finetune.py /root/train/lora_output/iter_6224.pth /root/train/merged/合并完成后,页面调试:
cd /root/train
touch web-demo-sft.pyimport gradio as gr
import torch
from transformers import AutoModel, AutoTokenizer, AutoConfig
from PIL import Image
# 加载模型部分
path = '/root/train/merged'
# path = '/root/share/new_models/InternVL3/InternVL3-8B'
device_map = None
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=False,
low_cpu_mem_usage=True,
use_flash_attn=False,
trust_remote_code=True,
device_map="auto" if device_map is None else device_map
).eval()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# 预处理图片函数
def preprocess(image, max_num=12, image_size=448):
from torchvision import transforms as T
from torchvision.transforms.functional import InterpolationMode
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((image_size, image_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
pixel_values = transform(image)
pixel_values = pixel_values.unsqueeze(0).to(torch.bfloat16).cuda()
return pixel_values
# 推理函数
def predict(image, message, history):
if image is None:
return history + [("请上传一张图片", "")]
pixel_values = preprocess(image)
if history is None or len(history) == 0:
user_input = f"<image>\n{message}"
response, new_history = model.chat(
tokenizer, pixel_values, user_input,
generation_config={"max_new_tokens": 1024, "do_sample": True},
history=None, return_history=True
)
else:
response, new_history = model.chat(
tokenizer, pixel_values, message,
generation_config={"max_new_tokens": 1024, "do_sample": True},
history=history, return_history=True
)
return new_history
# Gradio界面
with gr.Blocks(title="InternVL3-9B-sft Web Demo") as demo:
gr.Markdown("<h1 align='center'>📷 InternVL3-9B-sft Chat Demo</h1>")
gr.Markdown("<p align='center'>⚠️ 务必上传<strong>正方形图片</strong>,否则人脸压缩,识别不准。推荐分辨率为 <code>448×448</code> 尺寸仍然能看清人脸的图片。</p>")
with gr.Row():
with gr.Column(scale=1):
image_input = gr.Image(type="pil", label="上传一张图片")
with gr.Column(scale=2):
chatbot = gr.Chatbot(height=600, label="对话")
message_input = gr.Textbox(placeholder="请输入你的问题...", label="提问")
send_btn = gr.Button("发送")
state = gr.State([]) # 保存history
def on_send(image, message, history):
if message.strip() == "":
return history
history = predict(image, message, history)
return history
send_btn.click(
fn=on_send,
inputs=[image_input, message_input, state],
outputs=[chatbot]
)
message_input.submit(
fn=on_send,
inputs=[image_input, message_input, state],
outputs=[chatbot]
)
demo.launch(server_name="127.0.0.1", server_port=6000, share=True)执行语句:
conda activate xtuner
pip install gradio==5.29.0
cd /root/train
python web-demo-sft.py
ssh root@ssh.intern-ai.org.cn -p 43979 -CNg -L 6004:127.0.0.1:6000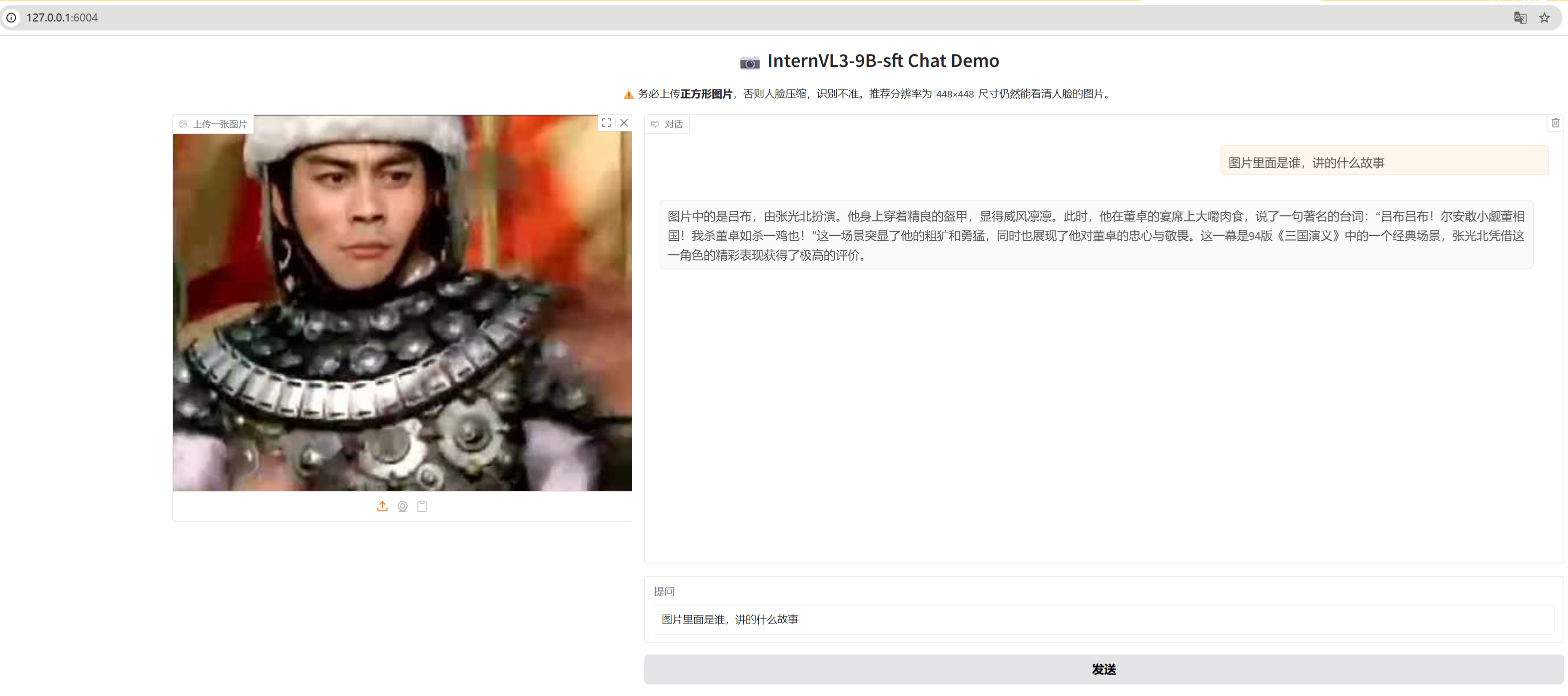
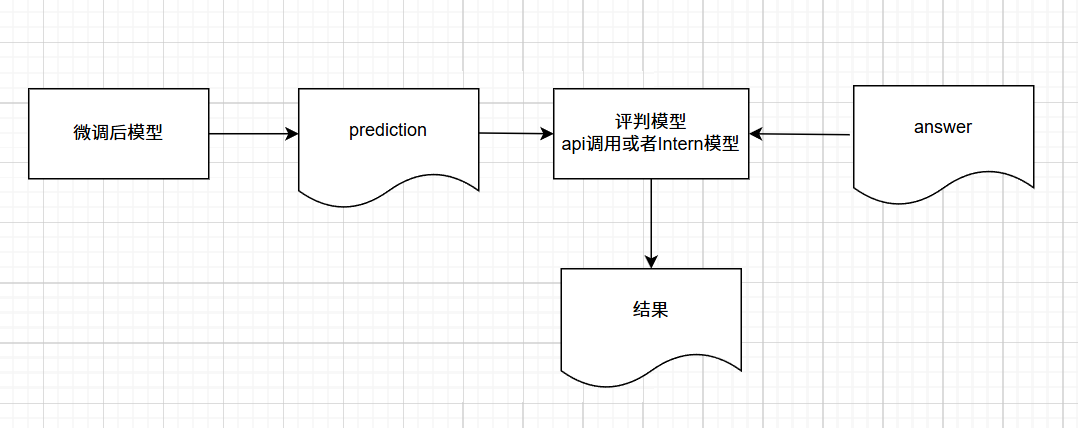
4 使用VLMEvalKit测评
1 本例子使用了SanguoDataset测评集**来测试,下面来复现下vLLM测试时需要修改哪些代码:
E:\216githubCode\VLMEvalKit\vlmeval\dataset\__init__.py
E:\216githubCode\VLMEvalKit\vlmeval\dataset\image_vqa.py
E:\216githubCode\VLMEvalKit\vlmeval\vlm\internvl\internvl_chat.py
E:\216githubCode\VLMEvalKit\run.py具体执行流程如下:
flowchart TD
A[run.py主脚本] --> B[解析命令行参数]
B --> C[初始化分布式环境]
C --> D[遍历模型和数据集]
D --> E[调用build_dataset]
E --> F{是否SanguoDataset?}
F -->|是| G[实例化SanguoDataset]
G --> H[加载数据集]
H --> I[调用infer_data_job]
I --> J[构建prompt]
J --> K[模型生成回答]
K --> L[调用evaluate方法]
L --> M[使用gpt-4-turbo评估]
M --> N[执行Sanguo_auxeval]
N --> O[计算Sanguo_acc]
O --> P[保存结果]
F -->|否| Q[其他数据集流程]完整的SanguoDataset测试执行流程如下:
- 入口: run.py 主脚本
- 解析命令行参数
- 初始化分布式环境
- 遍历所有指定的模型和数据集
- 数据集构建阶段:
- 调用build_dataset函数(vlmeval/dataset/init.py)
- 根据dataset_name匹配到SanguoDataset类
- 实例化SanguoDataset,加载数据
- 推理阶段:
调用infer_data_job函数( vlmeval/inference.py )
为每个样本构建prompt:
使用SanguoDataset.build_prompt方法
包含图像和文本问题
- 调用模型生成回答
- 评估阶段:
- 调用SanguoDataset.evaluate方法:
- 使用gpt-4-turbo作为judge模型
- 执行Sanguo_auxeval辅助评估
- 计算Sanguo_acc最终得分
- 保存结果到.xlsx和.csv文件
关键调用链: run.py → build_dataset → SanguoDataset → infer_data_job → SanguoDataset.evaluate
是否需要我进一步解释任何细节或执行相关测试?
本教程的作者使用下面的代码进行:
cd /root && mkdir temp
cd /root/temp
git clone https://github.com/HelloWarcraft/VLMEvalKit2 测试架构
测试框架: